



移动互联网数据分析前需要先启动spark-shell交互命令:
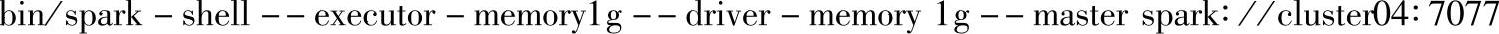
其中,cluster 04为spark集群的Master节点。
启动后使用下面语句,去除过多的日志信息:

数据字段模型等变量的定义:

一、移动互联网数据的加载及预处理
这里分析的移动互联网数据已经是经过一定处理之后的数据,为了给出一些预处理(比如无效数据过滤)的案例,在各种统计分析之前先加载数据文件,并对文件进行简单处理。
首先加载文件,然后通过判断每行数据的字段个数,对访问记录的有效性进行判断。

如果有多个有效性过滤条件,尽可能在一个API中,比如这里的filter中的判断函数。因为每个对分区进行操作的API,都对应了一次Iterator的迭代,当分区记录比较多时,多次迭代会对性能会有一定影响。
二、不同应用使用情况的统计
对移动互联网数据的不同应用使用情况的统计,可以简化为对APP字段访问次数的简单统计,统计代码如下:
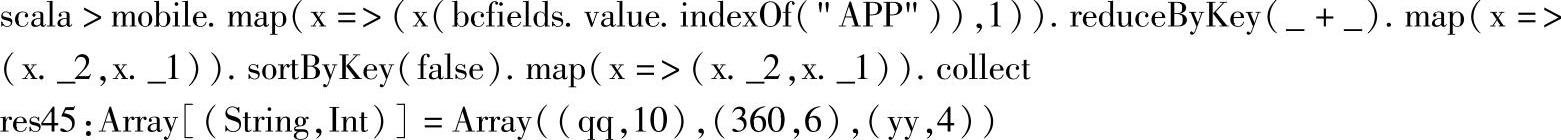
首先,第一个map将移动互联网数据转换为org.apache.spark.rdd.RDD[(String,Int)]类型,其中,String对应APP的信息,Int对应使用的计数信息;然后使用reduceByKey对APP进行计数统计;最后通过map交换key与value,并使用sortByKey进行排序,这里sortByKey的参数为false,表示计数从大到小进行排序。
为了方便查看,这里通过collect在界面上显示结果,在实际的应用中,可以保存到文件中,如下所示:
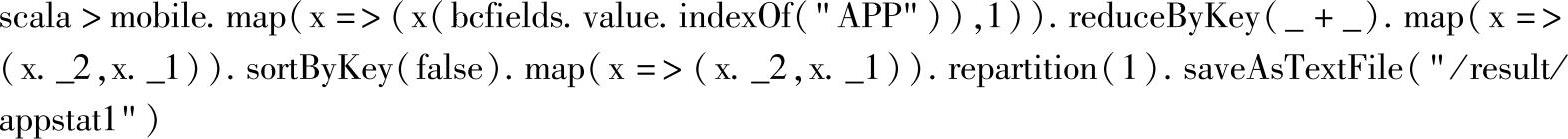
在保存文件时,通过repartition(1)指定分区个数为1,可以将所有内容保存到一个文件中。文件保存的结果如下:

三、移动互联网上的DAU及MAU的统计(https://www.xing528.com)
对动互联网上的DAU及MAU的统计时,需要注意对用户的去重处理:每个用户由字段“IMEI”唯一标识,统计时需要去除重复用户。
统计移动互联网上的DAU的代码如下:
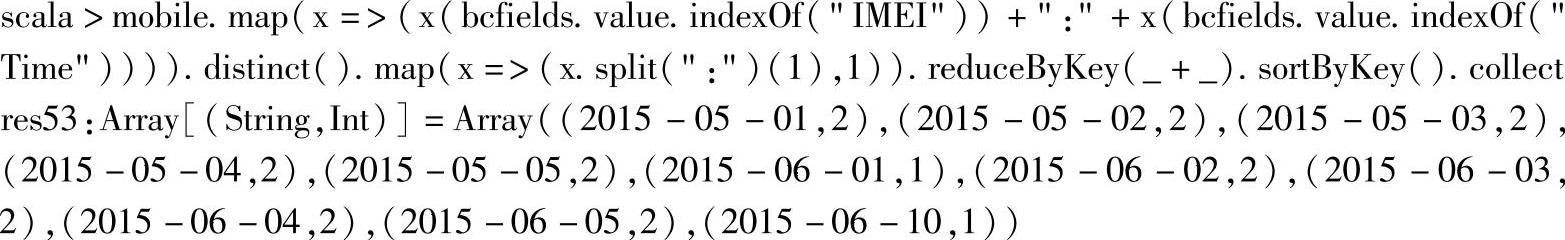
首先,为了统计DAU时对用户进行去重,通过第一个map操作,将唯一标识用户信息的“IMEI”字段和标识日访问的时间“Time”字段进行合并;然后调用distinct()方法进行去重;最后从合并数据中提取出“Time”字段,并进行计数统计。
同样,为了方便查看,这里通过collect在界面上显示结果,在实际的应用中,可以保存到文件中,具体参考对移动互联网数据的不同应用使用情况的统计中的保存文件代码部分。后续代码中都会通过collect方式显示统计结果(collect适合在调试代码或查看少量数据时使用,大量数据处理结果的查看,可以通过take等方法)。
统计移动互联网上的MAU的代码如下:
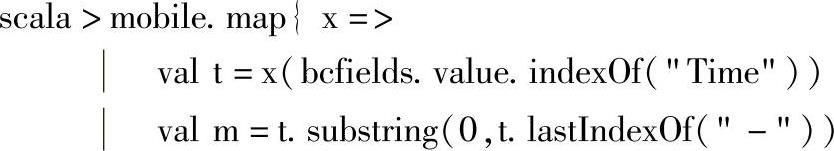

MAU的统计和DAU的统计仅仅在统计的时间上存在差异,这里首先在合并“IMEI”字段和时间“Time”字段时,将时间“Time”字段转换为月份,之后的处理和DAU的统计是一样的。
四、在不同应用中的上下行流量统计
对移动互联网数据的不同应用的流量统计可以得到不同应用的基础分析信息,比如可以结合各个应用的使用次数,各个应用的类型(比如视频应用、网页浏览应用等)等信息分析各个应用在流量使用上是否合理,以及分析出不同应用对网速的不同要求等。
具体上下行流量的统计代码如下:

首先,通过map方法,将每条访问记录转换为(应用名称,[上行流量,下行流量])的数据类型;然后通过reduceByKey方法对各个应用的上下行流量进行统计分析。
需要说明的是,实际情况下各种应用中会包含不同的子应用(即一个大类型的应用中会有子类型的应用),比如在QQ应用中,会包含QQ空间、文本聊天、语音聊天以及视频聊天等。在真实的移动互联网数据中,通常会使用两个字段,即大业务类型和小业务类型来表示QQ应用及其具体的子应用,这时候可以针对大应用和小应用进行统计以实现更精确的分析。
对移动互联网数据进行统计分析之后,可以进一步通过可视化工具进行呈现。下面应用程序统计如图2.74所示。
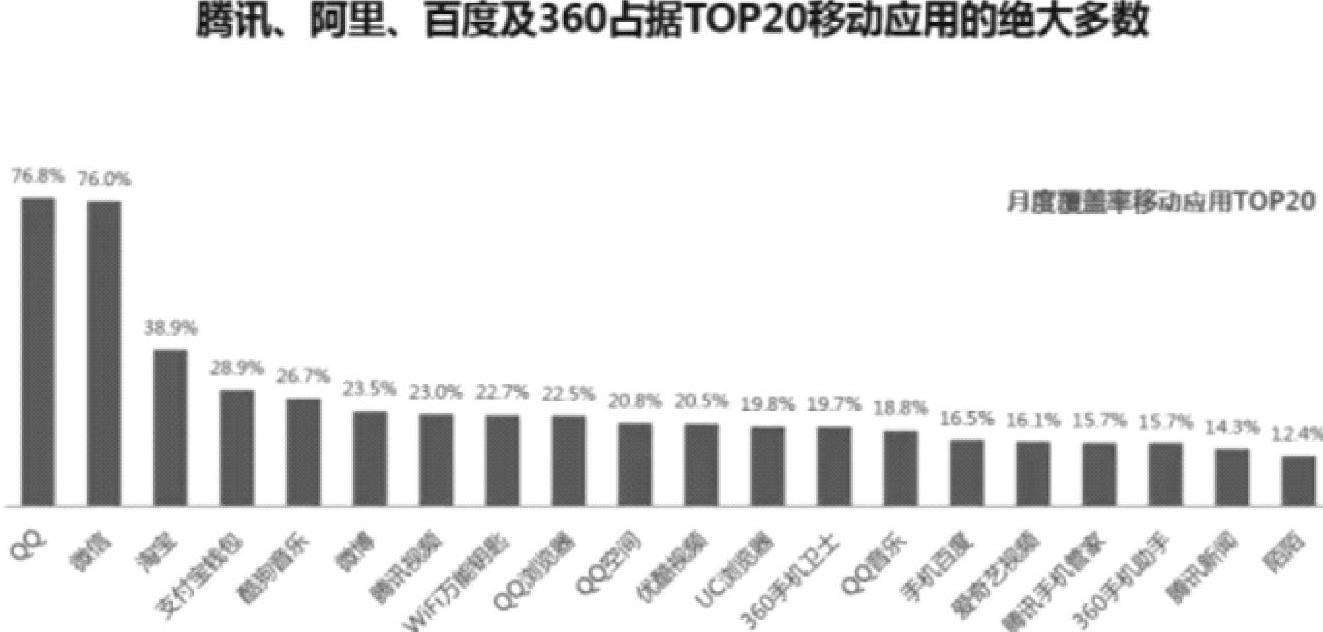
图2.74 移动互联网Top20应用的占比图
通过统计分析并以图表方式呈现后,可以让用户更易于了解移动互联网的行业发展情况。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。