



解析各种情况下的RDD的分区数设置情况,具体包括加载文件创建的RDD的分区数、SparkContext中默认的分区数、经过转换后的RDD的分区数以及针对特定的Key-Value格式类型的RDD的分区数。
一、加载文件创建RDD时的分区数解析
如下所示:

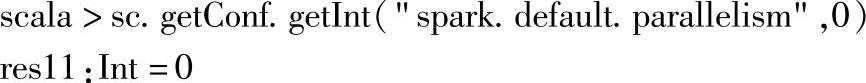
sc.defaultParallelism是当前默认的并行数,对应加载的本地文件(非HDFS文件系统)以默认的并行数作为构建的RDD的分区数。
注意:当前没有设置“spark.default.parallelism”配置属性,所以使用sc.getConf.getInt("spark.default.parallelism",0)获取属性时,值为设置的默认值0。
查看SparkContext的源码:
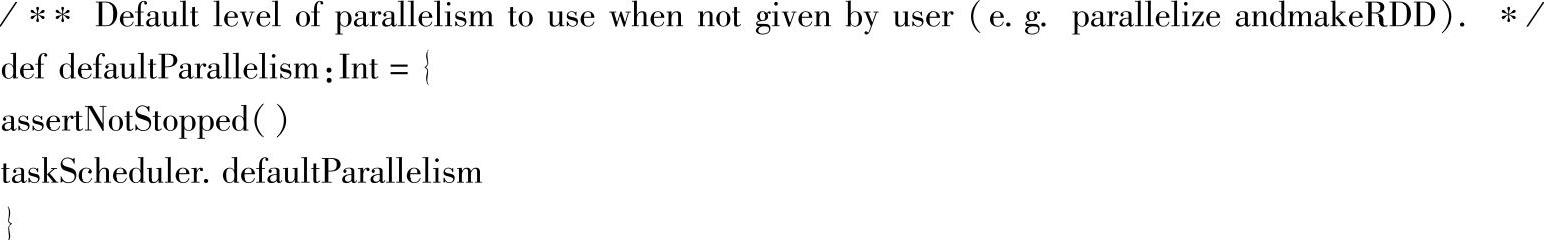
跳转到taskScheduler.defaultParallelism源码:
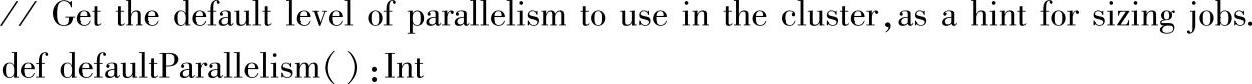
单击方法前的箭头,获取其具体子类的实现,当前仅提供一个具体子类,即TaskSchedulerImpl,如图2.28所示。
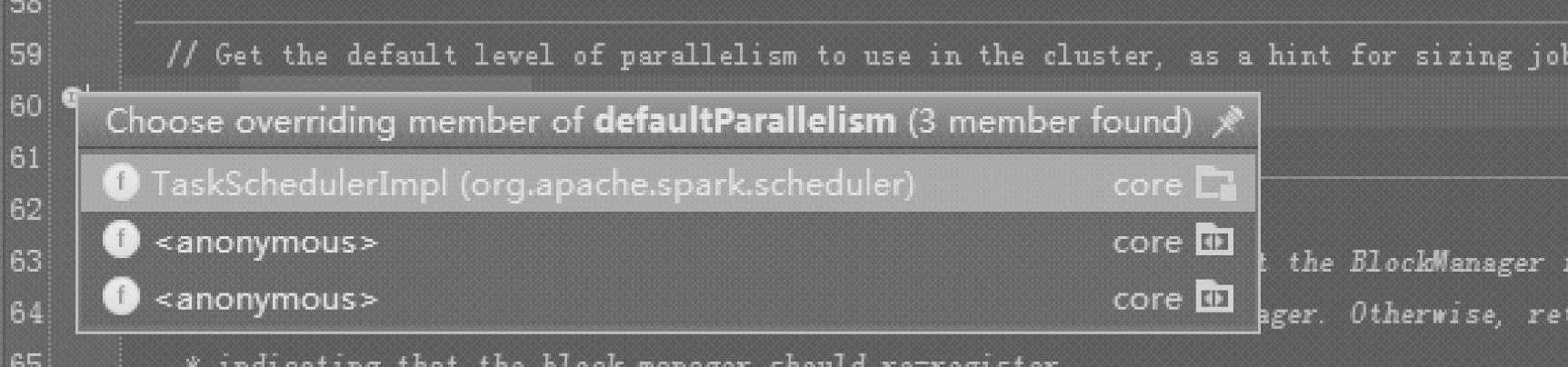
图2.28 获取taskScheduler.defaultParallelism方法的具体重载信息
跳转到TaskSchedulerImpl的源码:
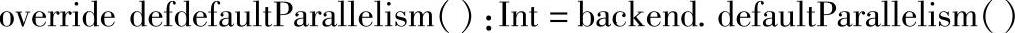
继续跳转到backend.defaultParallelism,然后跳转到具体子类的实现,继承的全部子类如图2.29所示。

图2.29 获取重载backend.defaultParallelism方法的具体子类
如MesosSchedulerBackend(对应集群模式)中的源码所示:
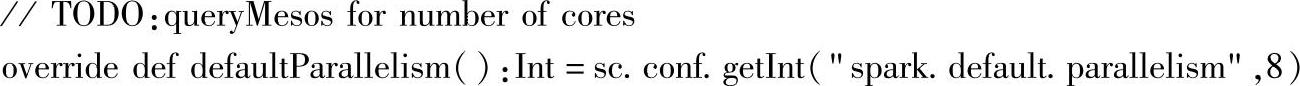
可以看到defaultParallelim的配置属性为:“spark.default.parallelism”,即集群模式下使用该属性作为defaultParallelim,并且默认值为8。
如子类LocalBackend中的源码(对应Local模式)所示:(https://www.xing528.com)
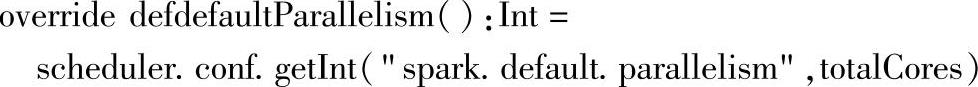
可以看到defaultParallelim的配置属性为:“spark.default.parallelism”,但当没有设置该配置属性时,默认值为总的内核数,LocalBackend对应Local模式。
修改默认的配置文件:$_HOME/conf/spark-defaults.conf,在文件中添加该属性的配置,如下所示:

在文件中添加一行配置:spark.default.parallelism 6。重新启动脚本,加载文件,并查询加载后RDD的分区数。
注意:默认的并行度只是作为加载文件时分区数的最小值参考,实际的分块数由加载文件时的Splits数决定,即文件的Blocks数。也可以由加载时的API参数指定分区数。
二、Key-Value元素类型的RDD的分区数解析
所有RDD都可以从getPartitions方法中找出分区数和父RDD的分区数间的依赖关系。同时,针对Key-Value元素类型的RDD,还提供了精细控制的分区器partitioner,可以通过设置分区器,来指定元素如何分区的策略,以及分区的个数。
当没有设置分区器时,默认使用HashPartitioner,具体参见分区器中的默认分区器定义源码:


从代码中可以看到,当没有设置分区数时,会使用“spark.default.paralelism”属性配置的值作为默认的分区数值。
以Key-Value为特定类型的PairRDDFunctions类中reduceByKey方法构建RDD为例,参见reduceByKey代码:

在调用基础的reduceByKey方法(另两个API会分别设置分区数或分区器)时,由于没有设置分区数或分区器,因此使用了默认的分区器,这里的默认分区器就是使用上面在ob-ject Partitioner中提到的defaultPartitioner方法。
三、源码解析的扩展
在源码解析过程中,可以进行一些扩展,比如之前的MapPartitionsRDD源码:


一般RDD设置了分区器partitioner时,在getPartitions中都会通过该分区器,控制如何从依赖的各个父RDD中获取各个分区的数据,而在MapPartitionsRDD中,只是根据参数pr-eservesPartitioning是否为true来控制是否设置MapPartitionsRDD的分区器partitioner。
因此引出了以下问题:当preservesPartitioning控制当前MapPartitionsRDD的partitioner的设置,preservesPartitioning的作用是什么?两种取值true或false具体应该在什么情况下?
问题的解析:当前MapPartitionsRDD的getPartitions方法中并没有依据partitioner记录分区的数据来源,但作为分区器,它不仅可以用于RDD分区获取其依赖的父RDD的数据上,还可以将该分区器传递到其子RDD中,在这里,主要的目的是后者,将分区器信息在DAG的Lineage上进行传递。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。