



对初学者而言,只需要掌握以下几个启动、停止的命令,就可以相应地启动和停止对应的集群了。在接下来介绍的集群准备时,只启动HDFS和Spark两个服务。
一、集群规划
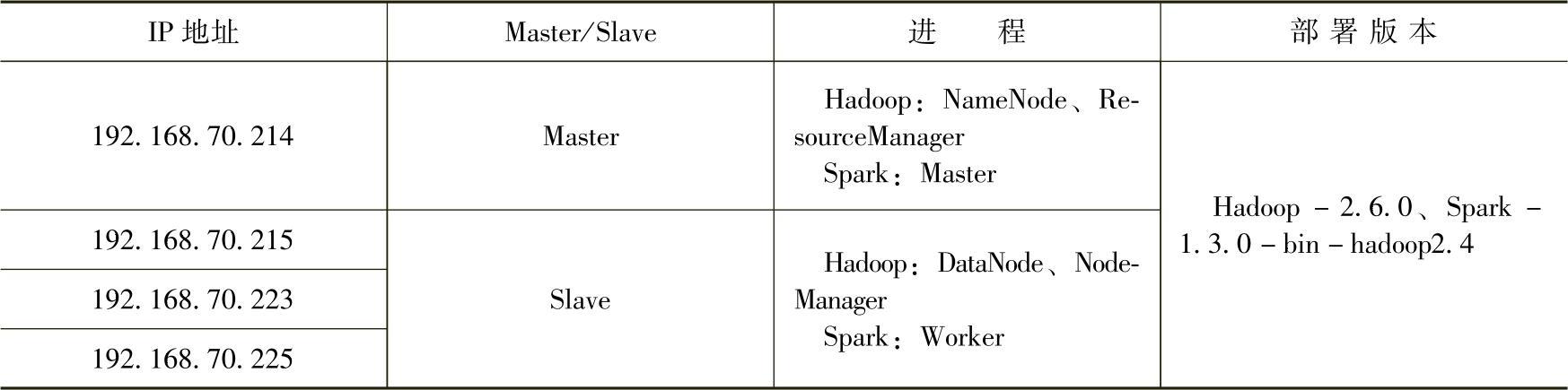
在四台机器上构建集群,具体环节搭建的规划如表2.3所示。
表2.3 集群部署环境说明
二、版本说明
1.支持环境采用Hadoop-2.6.0-64:64位操作系统上重新编译的Hadoop 2.6.0版本的部署包。
2.Spark-1.3.0-bin-hadoop2.4:基于Hadoop 2.4版本重新编译的spark 1.3.0版本的部署包。
由于Hadoop的客户端兼容二进制,因此基于Hadoop 2.4版本编译的Spark可以访问Hadoop2.6版本的HDFS。
三、启动Hadoop支持环境
Hadoop集群环境的搭建请参考王家林老师的《大数据Spark企业级实践》,在此不再赘述。
Hadoop环境对Spark的支持主要有两方面:
1.通过HDFS实现底层存储系统的支持
HDFS是一个主/从(Mater/Slave)式的体系结构,从最终用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件执行CRUD(Create、Read、Update和Delete)操作。但由于分布式存储的性质,HDFS集群拥有一个NameNode和一些DataNode。Name-Node管理文件系统的元数据,DataNode存储实际的数据。客户端通过同NameNode和Data-Nodes的交互访问文件系统。客户端通过访问NameNode来获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。
2.通过Yarn实现集群资源管理的支持
Yarn是Hadoop 2.0新增的集群资源管理系统,负责集群的资源管理和调度,使得多种计算框架可以运行在一个集群中。
如果使用Spark自带的资源管理器,即使用Spark Standalone模式的话,只需要提供Ha-doop的HDFS支持;如果同时使用了Hadoop的集群资源管理器,即采用Spark on Yarn模式的话,需要同时提供Hadoop的Yarn。
在集群中的Master节点上,分别启动HDFS和Yarn。
四、HadoopHDFS的格式化
Hadoop的HDFS部署好了之后并不能马上使用,而是先要对配置的文件系统进行格式化。在这里要注意两个概念,一个是文件系统,此时的文件系统在物理上还不存在,或许用网络磁盘来描述会更加合适;二就是格式化,此处的格式化并不是指传统意义上的本地磁盘格式化,而是一些清除与准备工作。在Hadoop部署目录下输入命令:
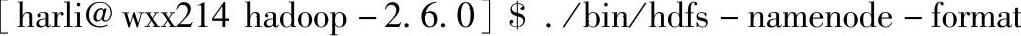
执行结果如下所示:

五、启动集群的HDFS服务
格式化NameNode后,在Master节点用启动脚本启动集群HDFS,在Hadoop部署目录下输入命令./sbin/start-dfs.sh,启动dfs,运行该命令结果如下:

对应的停止dfs的命令为./sbin/stop-dfs.sh,运行该命令结果如下:
 (https://www.xing528.com)
(https://www.xing528.com)
六、启动集群的Yarn服务
如果要使用Spark on Yarn模式,在Hadoop的资源管理器Yarn下提交应用的话,可以通过Yarn启动脚本来启动集群的Yarn,在Hadoop部署目录下输入命令./sbin/start-yarn.sh,运行该命令结果如下:

对应的停止Yarn命令为./sbin/stop-yarn.sh,运行代码如下:

从启动和停止后的Jps信息中,可以看出对应服务的进程信息。
七、启动Spark集群
Spark集群环境的搭建请参考王家林老师的《大数据Spark企业级实践》一书。
进入Spark部署目录,输入命令start-all,启动Spark集群:

对应的停止命令为stop-all,程序执行代码如下所示:

八、查看当前集群启动进程情况
在Master节点,使用jps命令查看进程启动情况,输入命令后执行结果如下:

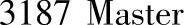
由上述执行结果可知,当前Hadoop的NameNode,ResourceManager等Master进程和Spark的Master进程部署在同一台机器上,即这里的命令行提示信息中的wxx214节点上。
其中各个服务支持的进程对应关系如下:
1)Hadoop的HDFS服务:NameNode进程。
2)Hadoop的Yarn服务:ResourceManager进程。
3)Spark的Master服务:Master进程。
在Slaves节点,使用jps命令查看进程启动情况,命令执行结果如下:

其中各个服务支持的进程对应关系如下:
1)Hadoop的HDFS服务:DataNode进程。
2)Hadoop的Yarn服务:NodeManager进程。
3)Spark的Slave服务:Worker进程。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。