



1.语音识别模块实现
情感机器人语音识别模块选择Pattek ASR SDK在Visual C++6.0环境下进行开发。Pattek ASR SDK提供动态链接库以及C++头文件:ASRAPI.h:头文件,提供所有函数原型以及参数定义等;asrapi.lib:静态链接库;asrapi.dll:动态链接库。语音识别流程如图7-25所示。
2.语音合成模块实现
经过对多家语音合成开发包以及硬件合成芯片进行对比,发现采用硬件合成芯片语音识别模块运行比较稳定,且识别效率比较高。最后对多家硬件合成芯片进行对比,认为科大讯飞的XF—S4240与电脑连接和通信实现起来比较简单方便,因此选用该芯片作为本平台的语音合成模块。

图7-24 人机交互界面实现

图7-25 语音识别流程图
XF-S4240中文语音合成模块,是安徽中科大讯飞信息科技有限公司(科大讯飞)推出的基于科大讯飞在嵌入式中文语音合成领域的最新研究成果——InterSound4.0中文语音合成系统,而设计的一款中文语音合成模块。该模块可以通过异步串口(UART)、SPI接口及I2 C总线三种方式接收待合成的文本,直接合成为语音输出;主要面向中高端应用,为其提供一套完整的音解决方案。
该模块可合成任意的中文文本,支持英文字母的合成,支持GB2312、GBK、BIG5、UNICODE四种内码格式的文本;具有智能的文本分析处理算法,可正确识别和处理数值、号码、时间日期及一些常用的度量符号,具备多音字处理和中文姓氏处理能力。
计算机和芯片的通信方式采用的串口通信,其连接电路如图7-26所示。
3.语音交互模块实现
仅有语音识别和语音合成模块并不能实现真正的语音交互功能。交互的关键在于如何将识别和合成模块进行衔接,使其能够平滑的进行交互。而本软件平台使用的交互模块很好的实现了这方面的功能。语音交互流程如图7-27所示。
语音交互模块介于语音识别、语音合成模块和知识数据库之间。对语音识别结果进行关键词模糊查询再将结果转换为知识库匹配的格式。再通过交互模块的查询函数对数据库进行查找和调用,最终将结果发送给语音合成模块进行音频输出。

图7-26 连接电路图
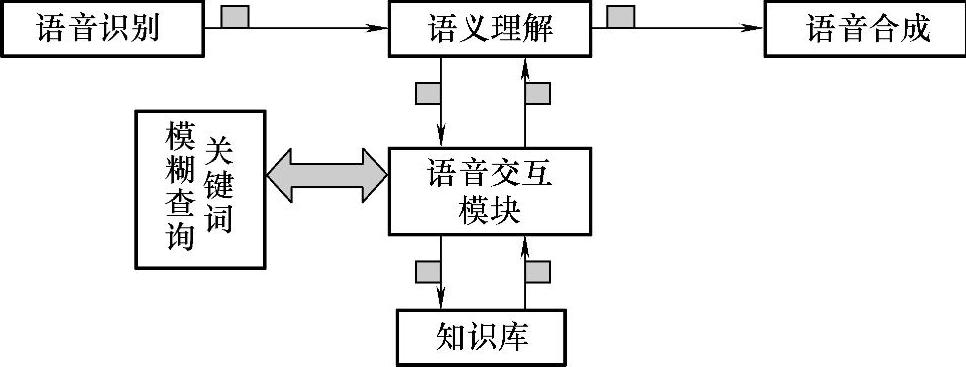
图7-27 语音交互流程图
我们通过Windows的消息机制来触发事件。机器人情感交互的流程如图7-28所示。
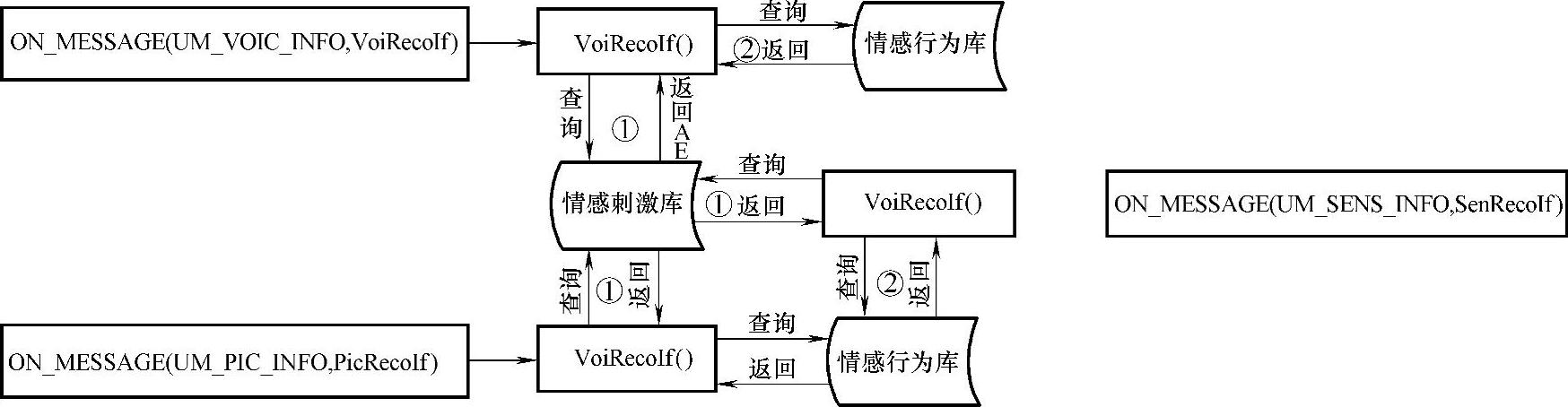
图7-28 情感交互流程
4.动作行为模块实现
机器人交互软件平台通过PC机的RS232串口与下位机中的单片机实现通信。本软件平台通过VC++的Mscomm控件编程来实现上位机PC同时向四个硬件设备发送数据,硬件设备均接收数据到缓冲区,根据ID号匹配情况来决定这帧数据的取舍。下位机通过单片机串口编程实现向上位机反馈信息和发送传感器信息。上位机通过串口向下位机发送控制指令的流程如图7-29所示。在通信过程中采用事件驱动方式来处理通信,用OnComm事件捕获并处理通信事件,还可以检查和处理通信错误,具有程序响应及时,可靠性高的特点,适合用于机器人控制。

图7-29 串口发送指令流程图
5.人脸识别模块实现
(1)算法实现
本交互平台采用Windows的VFW库以及OpenCV作为开发工具,对于摄像头采集的彩色图像,包含复杂的背景,利用VFW库将人脸检测出来,对检测出的结果利用OpenCV进行二次处理,创新性的运用隐马尔可夫算法实现最终的人脸识别。
我们采用YCb Cr颜色模型。对输入彩色图像进行颜色空间转换,将其从相关性较高的RGB空间转换到颜色分量互不相关的Y/Cb/Cr颜色空间。转换公式如式(7-2)所示。
 (https://www.xing528.com)
(https://www.xing528.com)
为检测场景中的人脸区域,建立一个有效的肤色模型是非常重要的。统计方法是一种常用的工具。在此,用一个随机变量表示像素值的变化。该随机变量的概率密度函数具有特定的统计分布形式,其参数通过训练数据来估计。为了得到这个统计分布。我们在30秒内取1000帧图像对人脸面部肤色的某一像素值进行观察。从实验中,我们发现,人的肤色在色度空间分布符合二维高斯分布N(μ,δ。),其中均值μ=E{χ},χ=(Cr,Cb)T;假设Cr、Cb颜色分量相互统计独立。则协方差δ=E{(x-μ)(x-μ)T}。根据肤色在色度空间的高斯分布,对于图像上任意一点从RGB颜色空间变换到YCbCr颜色空间,从而得到该点属于肤色区域的概率如式(7-3)所示:
P(Cr,Cb)=exp[-(x-u)T δ-1(x-u)/2]/{(2π)3/2 δ1/2}(7-3)
在实验中,属于肤色的Cr、Cb颜色分量的均值取:μ=(117.4361,156.5599)T,协方差δ如式(7-4)所示:

通过肤色模型将一副彩色图像转变为灰度图像,灰度值对应于该点属于皮肤区域的程度。然后我们采用动态平均阈值法对图像进行二值化处理,结合水平灰度投影和垂直灰度投影,找到人脸区域的上下边界,对人脸进行标记。
将人脸检测标记出的人脸区域进行二次处理,调用OpenCV算法进行人脸识别,开发包组件包括头文件:cv.h,highgui.h,ImageProcess.h,export.h动态引入时刻库和运行时刻库FaceSys.lib,ImageProcess.lib,开发中需要动态库cv099.dll,FaceSys.dll,highgui099.dll的支持。
为了使程序更加模块化,我们将以上所说的算法整体都封装在DLL库,这样可以使开发者使用起来更加方便,尤其是进行二次开发时。我们向外部提供的三个文件:头文件(FaceID.h),FaceID.lib文件,动态库文件(FaceID.dll)。
(2)程序实现
1)图像采集实现:基于算法的要求,我们所采集的人脸图像必须是BMP图片,无论是注册还是识别。这一点我们在程序主要通过微软的vfw来实现。
2)人脸注册与识别的实现:根据动态库提供的接口,我们分析出注册和识别的流程图,如图7-30所示。

图7-30 人脸注册和识别流程图
a)人脸注册流程图 b)人脸识别流程图
人脸注册界面如图7-31所示。

图7-31 人脸注册界面
图7-31主要是演示人脸注册的过程,我们在注册的时候,会向数据库中写入用户的人脸姓名,动作号以及对应的语音信息,这样做的目的是使系统可以实现根据不同的人,调整回话内容和表演动作。在注册对话框上有两个主要的按钮,代表两种不同的注册方式:一个是视频采集,另一个是照片注册。视频采集的注册方式是采用摄像头采集的bmp照片来完成人脸信息的写入以及注册;而照片注册是通过加载现有的bmp文件来实现人脸信息写入以及人脸的注册。
人脸识别结果界面如图7-32所示。

图7-32 人脸识别结果
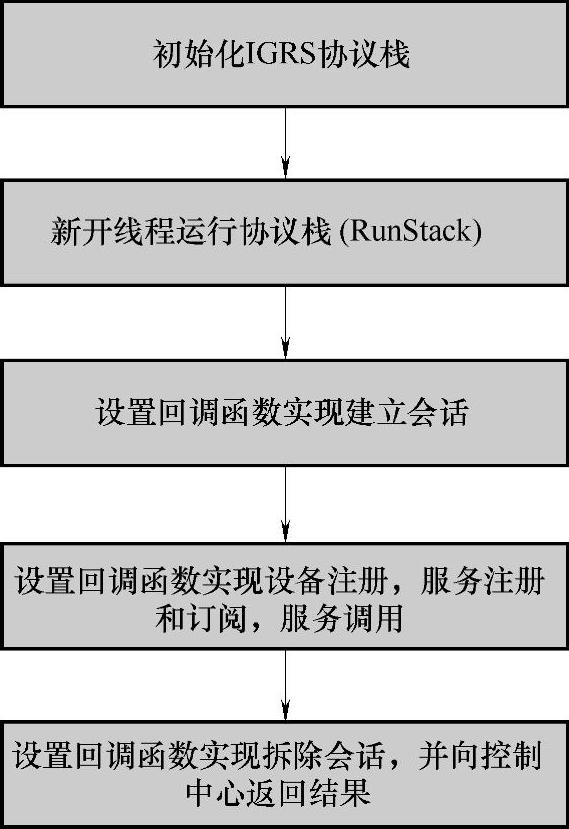
图7-33 集成IGRS功能流程图
当用户向情感机器人说:认识我吗,机器人就会让你看看他的眼睛,然后就合成我们注册时候写入的语音信息,并在姓名所对应的编辑框中写入人脸的姓名。
6.网络功能模块实现
(1)协议的实现
根据闪联的标准以及提供的文档,我们将该协议封装在库中,只向外部提供接口,在此平台上,主要利用动态库提供的接口来实现IGRS设备的功能。
(2)集成IGRS功能流程(见图7-33)
(3)代码实现
主要包括:初始化协议栈、定义和设置回调函数(全局函数)和服务调用函数。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。