



1.霍夫曼编码
霍夫曼编码是针对无记忆信源进行压缩的。所谓无记忆信源就是指信源字符的出现是独立的,也就是说连续的信源字符不存在相关性,不能从前面出现的字符推断后续字符的信息,而只是知道字符出现的概率。用A:{ai,i=1,2,…,N}表示信源,ai为信源A中的符号。若ai的出现概率为P(ai),则定义ai的信息量为
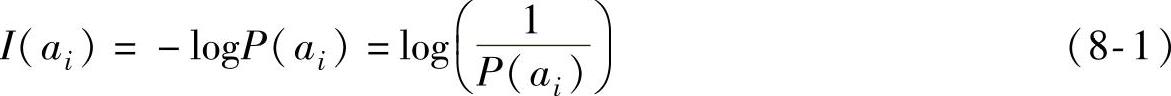
将信源A中所有可能字符的信息量进行平均,就得到信源的信息熵。信息熵定义了信源的平均信息量,其定义为
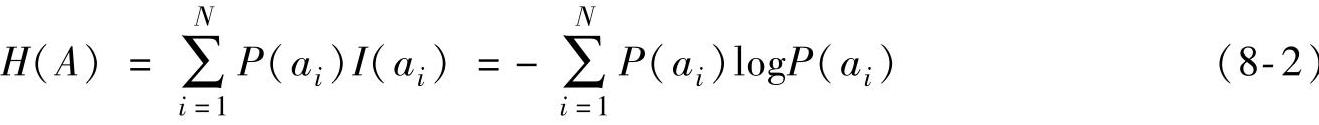
由信息熵的定义可知,0≤H(A)≤logN。当信源字符等概率分布时,信源信息最大。而只要信源字符不是等概率分布,就存在压缩的可能。
霍夫曼编码是一种非常直观、简单的压缩方法。其基本思想可以用一个简单的例子说明。设有一个只包含4个字符A、B、C、D的信源,它产生这4个字符的概率分别为1/2、1/4、1/8、1/8。直接对这4个字符分配2位的编码00、01、10、11,码长为2。通过对频率高的字符分配较短的编码,对频率低的字符分配较长一些的编码,可以在综合效果上得到一个较短的平均码长。采用霍夫曼二叉树编码的方法,从概率最小的字符开始编码可以得到新的编码:1,01,001,000。此时的平均码长为1×1/2+2×1/4+3×1/8×2=1.75。采用二叉树编码可以使每个压缩后的编码都不会是别的编码的前缀,这样在解码时就可以唯一地恢复原来的数据。霍夫曼编码是一种立即码,输入端不需要缓冲,编码延时最小。但由于输出为变长码,因此输出端需要缓冲区,将变长码转换为定长码输出。
霍夫曼编码也存在一些缺点。首先是误码扩散问题。与定长编码不同,如果一组经霍夫曼压缩的数据中出现了误码,就会导致其后一大段数据都无法正确译码,而防误码扩散措施又会降低霍夫曼编码本来就不高的压缩率。其次,较大的信源还需要霍夫曼码表。编码8位精度的漏磁检测数据,则需要一个长256,宽16位的码表,用硬件实现时需占用较多的硬件资源。因此,在实际应用中,还需要进行针对性的改进。
2.预测编码
预测编码是通过预测来改变信源字符的分布及其出现概率,从而减小互信息熵冗余的。我们平时所熟悉的GSM、CDMA技术等都是采用预测编码作为语音压缩编码核心的;电视信号压缩也采用了二维和三维预测编码。
差分脉冲编码调制(differential pulse code modulation,DPCM)是一种典型的预测编码方法,它输出当前信号的实际值和信号预测值之间的差值,其组成如图8-11所示。
预测器可分为线性预测器和非线性预测器两种,由于非线性预测器的设计和实现都比较复杂,实际应用中一般使用线性预测器。tN时刻的预测值和此前各时刻的采样值的线性预测关系可表达为
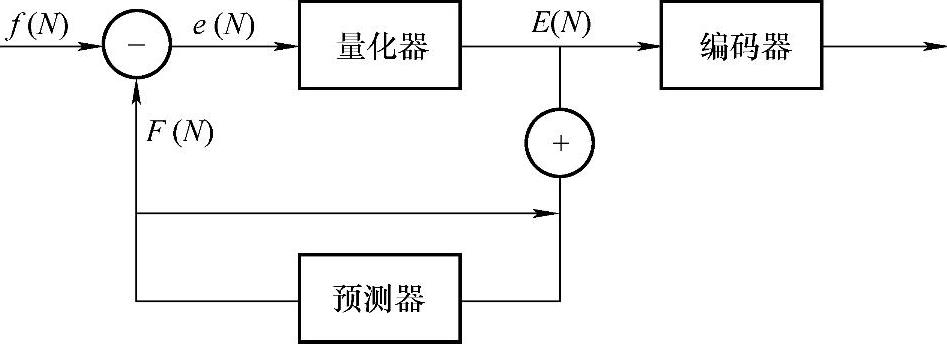
图8-11 DPCM预测编码器的组成

图8-11中f(N)是tN时刻的输入信号,F(N)是预测器根据某一预测规律从tN以前各时刻数据中得出的预测值,e(N)是输入值和预测值的差值。式(8-3)中a1,a2,…,aN-1称为预测系数。由于e(N)一般要比原输入数据小,而且e(N)的分布要比原数据更为集中,因此可以用较小的比特数进行编码。根据量化器的有无,预测器可以分为有损预测器和无损预测器。一般的DPCM系统都采用有损编码。由于需要保留一些数据用来预测,预测编码需要一定的输入缓冲区,编码延时较小;同霍夫曼编码一样,预测编码由于输出为变长码,需要输出缓冲区。
DPCM的一个缺点是抗误码能力较差,信道噪声或误码可能对整个编码过程产生影响,在实际应用中,需要一定的防误码扩散措施。
3.小波编码
小波编码既是一种特殊的变换编码方法,也是一种特殊的子带编码方法。
(1)变换编码 变换编码是以字符序列为处理对象,去除字符序列间的相关性。变换系数之间通常只具有较小的相关性,而且原信号的能量一般都集中于较小数目的大系数上,这些大系数的分布符合一定的规律,从而就可以通过后续的量化和编码来获得较大的压缩比。根据变换基函数的不同,有基于特征矢量的SVD变换、K-L变换,基于正弦型基函数的离散傅里叶变换、离散余弦(正弦)变换和基于方波型基函数的哈达玛变换、斜变换、哈尔变换等。基于特征矢量的变换方法具有最好的去相关效果,但其缺点也非常明显:不但计算协方差矩阵、协方差矩阵的特征值和特征矢量都需要很大的运算量,而且对于不同的数据块,会有不同的变换矩阵。在数据压缩中,应用较多的是离散余弦变换。
1)线性变换的基本理论。如果x是一个N×1的矢量,T是一个N×N的矩阵,则y=Tx定义了矢量x的一个线性变换(这个变换被称为线性变换,是因为y由输入元素的一阶和构成)。每个元素yi是T的第i行和输入矢量x的内积。由线性变换的概念可以看出,变换和信号分析是紧密联系在一起的。信号分析就是通过把信号由一个域变换到另一个域,如傅里叶分析就是把信号从时域变换到复频域,来对信号进行分析和处理的。函数的内积定义如下:

对于二维情况,将一个N×N矩阵X变换为另一个N×N矩阵Y的线性变换一般形式为
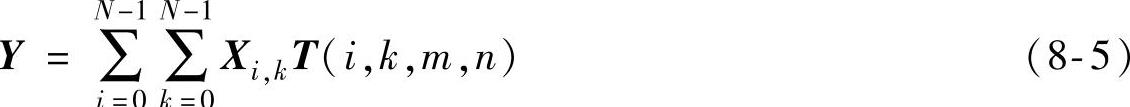
T(i,k,m,n)可以看作是一个N2×N2的块矩阵,每行有N个块,共有N行,每个块是一个N×N的矩阵。对于式(8-5),可以仿照一维的情况来理解:N×N矩阵X可以通过行堆积成为一个N2维的矢量,T(i,k,m,n)则是一个包含N2个N2维空间基矢量的矩阵。如果T(i,k,m,n)能被分解为行方向的分量函数和列方向的分量函数的乘积,即如果T(i,k,m,n)=Tr(i,m)Tc(k,n),则这个变换就是可分离的,即这个变换可以分成两步来完成:先进行行向变换,再进行列向变换(反过来也可)。当这两个分量函数相同时,T(i,k,m,n)=T(i,m)T(k,n),则原变换就可以写为Y=TXT。
2)基于余弦型基函数的变换方法。离散傅里叶变换(discrete fourier transform,DFT)和离散余弦变换(discrete cosine transform,DCT)是最主要的基于余弦型基函数的变换方法。由于DFT包含复数运算,在数据压缩领域一般并不采用。DCT变换在数据压缩领域应用非常广泛,JPEG、MPEG等国际标准的主要环节都是DCT变换。设{x(m),m=[0,M-1]}是M个有限值的一维实数信号序列集合,一维DCT变换的正交归一基函数系为
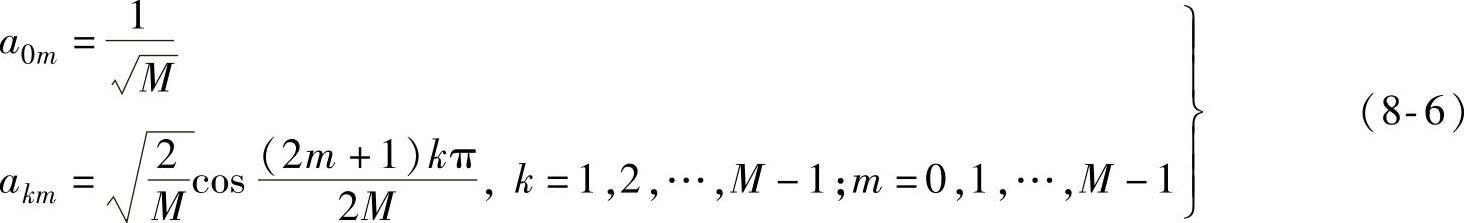
一维DCT的形式为

当被变换的序列接近于某一余弦成分时,会在与对应频率的变换基函数相内积时得到最大的变换系数。由于基函数都是正交的,这个序列与其他基函数的内积结果就会是些小得多的量。逆变换时是对以变换系数为权重的基函数加权求和来重构原信号,如原信号由少量与基函数相似的分量组成,则只需对较大的项求和,其他较小的量在变换后可以忽略而不再存储,这样信号在变换域就得到了压缩。
DFT和DCT使用正弦类的曲线波作为它们的基函数,这些基函数在整个变换域中非零。但在很多情况下,被变换的信号含有一些瞬态成分,如图像中的很多重要信息(例如边缘、纹理等)就是在空间位置中高度局部化的。由于这些瞬态信号并不类似于任何正弦成分的变换基函数,因此得到的变换系数不是呈紧凑分布。例如对单周期信号的傅里叶变换,它把一个瞬态信号分解成无数正弦信号的和,但是,这是通过错综复杂的安排,以相互抵消的方式消去一些正弦波,从而构造出在大部分区间都为零的瞬态函数,因此,瞬态信号的傅里叶变换的频谱呈现一幅相当复杂的构成。也就是说,对于瞬态成分,使用DFT、DCT等变换是得不到最佳表示的。如果使用有限宽度的基函数进行变换,这种问题就可以得到很好的解决。这些有限宽度的基函数不但在频率上而且在位置上都是变化的,基于它们的变换称为小波变换。
(2)子带编码 子带编码(sub-band coding,SBC)是设法用一组带通滤波器(band pass filter,BPF)将输入信号分割成若干个“波段”(称为子频带或子带)信号,这样就可望在这些子带内分别针对所要求的频率特性进行更加有效的处理。子带编码的一般原理功能图如图8-12所示。
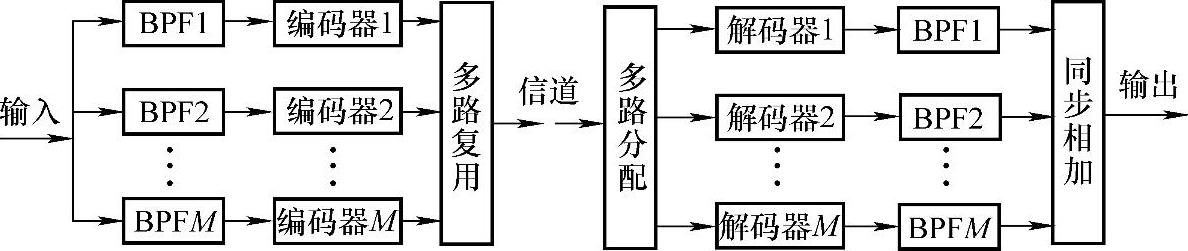
图8-12 子带编码的一般原理功能图
子带编码的主要特点是:利用M个带通滤波器把信号频带分解成若干子带,通过移频将各子带信号转到基带后按奈奎斯特速率重新取样,再对取样值进行通常的数字编码并复合成一个统一的传输码流。接收端首先将总码流分解成子带码流,然后解码并将信号从基带重新“搬移”回原来的子带频率位置,再将所有子带的滤波输出相加就可合成接近于原始信号的重建信号。
整数半带数字滤波器组分析与综合系统的原理功能图如图8-13所示。一维信号x(n)分别通过两个冲击响应为h0(n)和h1(n)的半带滤波器,分解成低频分量x0(n)和高频分量x1(n)后,都经2∶1抽取器重新取样,使得抽样后两个子带信号x0(n)和x1(n)的总数据量与原全带信号x(n)的相同。这意味着将这上、下(或高、低)两个子带信号频谱H0和H1均以全带信号频谱2倍的重复率进行周期重复。综合端1∶2内插器的作用是在其输入的每个取样件都插入1个零值,使每个子带信号都能与全带信号同长,频谱的重复周期也和全带信号一致,而最终的子带信号插值和频谱搬移则分别由综合滤波器g0(n)和g1(n)完成。将综合滤波器组的输出相加,便得到最后的重建信号y(n)。
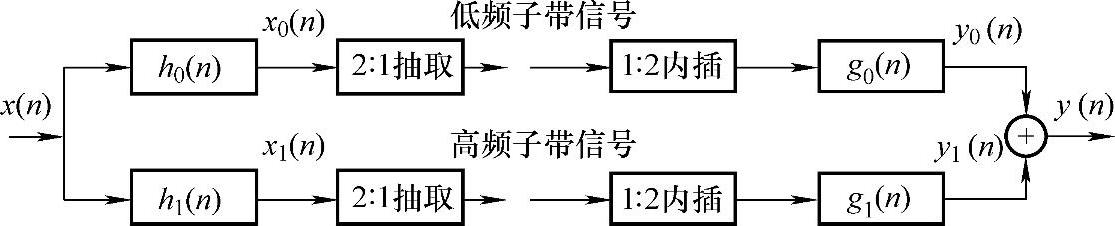
图8-13 整数半带数字滤波组分析与综合系统的原理功能图
由图8-13不难想象,利用整数半带分析滤波器组的级联,可以构成一个二叉树子带分解结构,其中以下两种情形较为典型:如果在每个子带的输出端都添加一个滤波器组形成新的一级,则利用L级总共2L-1个半带滤波器组,可实现M=2L个等宽子带的分解;如果只在每个低频子带的输出端添加新的一级,则利用L级共L个半带滤波器组可实现L个倍频程子带的分解。
利用子带编码具有很大的灵活性,其优点如下:
①码位分配灵活。由于信号的非平坦性,如果对不同子带合理分配编码位数,就有可能分别控制各子带的量化电平数及相应的重建方差,使码字更精确地与各子带的信源统计特性相匹配。
②噪声限制在带内。各子带的量化噪声都局限在本子带内,即使某子带内的信号能量较小,也不会被其他子带的量化噪声掩盖掉。
③复杂度不高。
④便于渐进编码。可先重建低频子带信号,再逐步添加高频子带信号,使恢复信号渐渐逼真。由于高频子带数据的丢失一般不至于严重影响对信号内容的本质理解,因此SBC具有“可丢包”的结构。
⑤适宜于“多分辨率”设备与系统。
(3)连续小波变换 连续小波变换(continuous wavelet transform,CWT)定义为
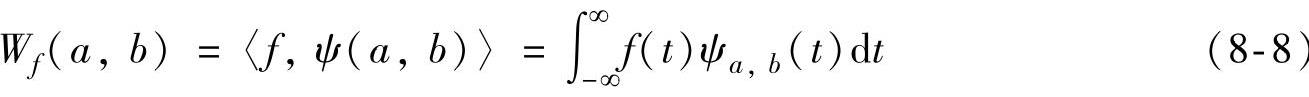
其中,函数系

称为小波函数(Wavelet Function)或称为小波(Wavelet),它是由函数ψ(t)经过不同的时间尺度伸缩(Time Scale Dilation)和不同的时间平移(Time Translation)得到的。ψ(t)是小波原型(Wavelet Prototype),并称为母小波(Mother Wavelet)或基本小波(Basic Wavelet)。a为时间轴尺度伸缩参数,大的a值对应于小的尺度,相应的小波ψa,b(t)伸展较宽;反之,小的a值对应的小波在时间轴上受到压缩。b为时间平移参数,不同b值的小波沿时间轴移动到不同位置。系数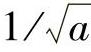 为归一化因子,它的引入是为了使不同尺度的小波保持相等的能量。值得注意的是,对于不同的母小波,同一信号的连续小波变换是不同的。
为归一化因子,它的引入是为了使不同尺度的小波保持相等的能量。值得注意的是,对于不同的母小波,同一信号的连续小波变换是不同的。
连续小波变换定量地表示了信号与小波函数系中的每个小波相关或接近的程度。如果把小波看成是L2(R)空间的基函数系,那么连续小波变换就是信号在基函数系上的分解或投影。
一个函数ψ(t)∈L2(R)能够作为母小波,必须满足允许条件:

式中,ψ(s)为ψ(t)的傅里叶变换。如果ψ(t)是一个合格的窗函数,则ψ(s)是连续函数。
因此,允许条件意味着:

式(8-11)的物理意义是ψ(t)为一个振幅衰减很快的“波”,小波由此得名。
如图8-14所示,如果把小波ψa,b(t)看成是宽度随a改变、位置随b变动的时域窗,那么,连续小波变换可以看成是连续变化的一组短时傅里叶变换的汇集,这些短时傅里叶变换对不同的信号频率使用了宽度不同的窗函数,具体来说,即高频用窄时域窗,低频用宽时域窗。小波变换具有的这一性质称为“变焦距”性质。
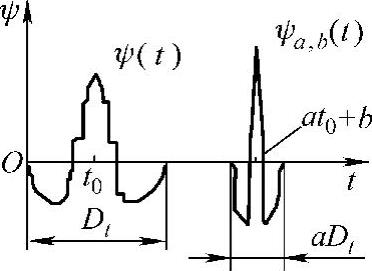
图8-14 小波与母小波
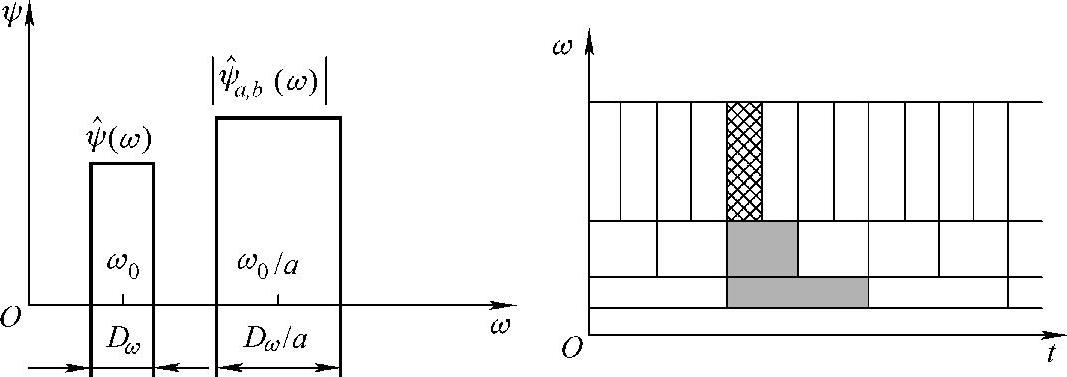
分析窗口的宽度aDt决定了时间分辨率和时间定位能力。a越小(对应于越高的频率),时间分辨率越高。因此,分析高频应采用窄的分析窗口。由于分析窗口面积恒定,当窗口变窄时,窗口高度相应增加,即频域分辨率和频率定位能力要降低。图8-15所示为从另一角度观察到的连续小波变换的“变焦距”性质。
 (https://www.xing528.com)
(https://www.xing528.com)
图8-15 小波变换的分析窗宽度随频率升高(尺度减小)而变窄
连续小波变换的重要性质如下:
性质1(线性):一个多分量信号的小波变换等于各个分量的小波变换之和。
性质2(平移不变性):若f(t)↔WTf(a,b),则f(t-τ)↔WTf(a,b-τ)。
性质3(伸缩共变性):若f(t)↔WTf(a,b),则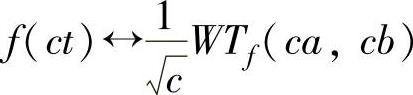 ,其中c>0。
,其中c>0。
性质4(自相似性):对应于不同的尺度参数a和不同的平移参数b的连续小波变换之间是自相似的。
性质5(冗余性):连续小波变换中存在信息表述的冗余度。
(4)离散小波变换 信号的连续小波变换是超完备的,一个一维信号f(t)的小波变换是二维函数,它代表的信息量和要求的存储量都大大增加了。在实际的数字信号处理过程中,为了计算简便,也为了减少不必要的冗余信息,可以对a、b的取值离散化,只利用离散化后保留下来的部分系数来分析信号。在大多数应用中,人们主要对二进制抽样感兴趣。二进制抽样是指利用形如a=2-j,b=k/2j(j、k为整数)的离散参数对信号进行分析和重构。类似于ψa,b(x),可以定义小波族为
ψj,k(t)=2j/2ψ(2jt-k)(j,k∈Z) (8-12)
此时的小波变换称为小波级数展开,其变换系数为
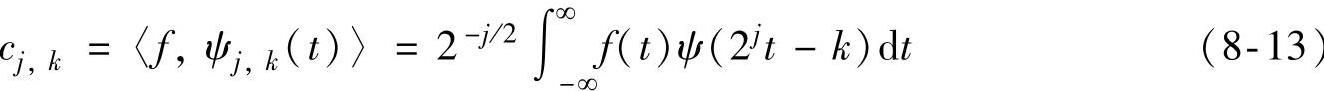
由连续小波变换的离散化还引出了用系数cj,k是否能够完全重构原信号的问题,这时的基小波在容许条件之外要有更多的限制。信号离散表示的完备性和冗余性是通过逼近论中的框架理论来描述的。满足如下条件的小波称为框架:
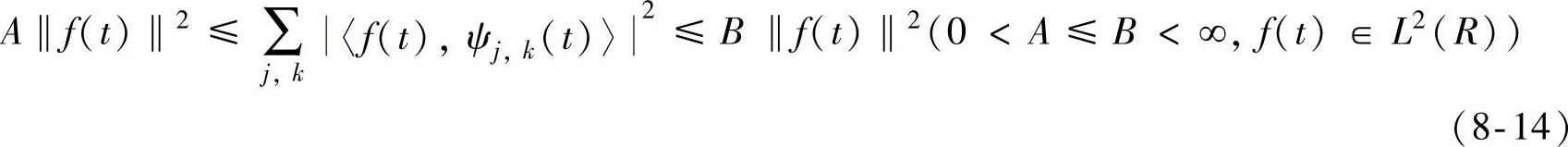
式中,A、B为框架界。
框架界的比B/A为小波表示的冗余测度,如果B/A=1,称ψj,k(t)为紧框架,紧框架的小波表示的冗余度小,具有良好的重建特性;当B/A远大于1时,称小波框架为松框架,此时的小波基也可以称为Riesz基。
如果ψj,k(t)是L2(R)的一个Riesz基,则存在L2(R)中的唯一一个Riesz基ψ~j,k(t),它的意义是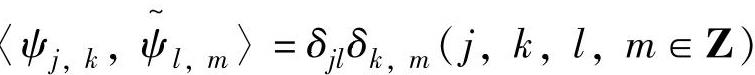 上ψj,k(t)的对偶基,
上ψj,k(t)的对偶基,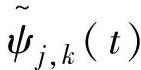 称为对偶小波。
称为对偶小波。
为了减小小波变换系数的冗余度,应尽量减小小波函数间的线性相关,因此希望小波族ψj,k(t)具有线性独立性,甚至是相互正交的。从信号重构的精度考虑,正交基又是信号重构的最理想的基函数,所以更希望小波是正交小波。根据各尺度间小波基及其对应的对偶小波基间的正交关系,小波可以分为正交小波、双正交小波、半正交小波和非正交小波。正交小波是指<ψj,k,ψl,m>=δjlδk,m(j,k,l,m∈Z)。对于正交小波,显然有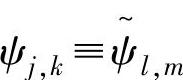 。正交小波一定是稳定的,因此获得了广泛的应用;半正交小波是指<ψj,k,ψl,m>=0(j,k,l,m∈Z,j≠l),它满足跨尺度的正交性。如果一个Reisz基小波不是半正交小波,则称非正交小波。双正交小波是指
。正交小波一定是稳定的,因此获得了广泛的应用;半正交小波是指<ψj,k,ψl,m>=0(j,k,l,m∈Z,j≠l),它满足跨尺度的正交性。如果一个Reisz基小波不是半正交小波,则称非正交小波。双正交小波是指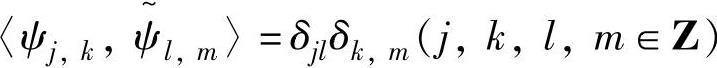 。正交小波一定是双正交小波,反之则一般不成立。双正交小波由于具有正交小波所不具有的良好对称性等特点,常用于图像压缩等应用。
。正交小波一定是双正交小波,反之则一般不成立。双正交小波由于具有正交小波所不具有的良好对称性等特点,常用于图像压缩等应用。
(5)多分辨率分析与Mallat算法 离散的小波框架其信息量仍是冗余的,因此从数据压缩的角度,仍希望减小它们的冗余度,直至得到一组正交基。解决这个问题的方法是多分辨率分析的方法。
多分辨率分析(multi-resolutionanalysis,MRA)又称为多尺度分析,它是建立在函数空间概念上的理论,但其思想的形成来源于工程。MRA不仅为正交小波基的构造提供了一种简单的方法,而且为正交小波变换的快速算法提供了理论依据。其思想又同多采样率滤波器组不谋而合,使小波理论同数字滤波器的理论结合起来。
1)多分辨率分析。设L2(R)内一个嵌套的闭子空间序列{Vj}由函数ϕ生成,即
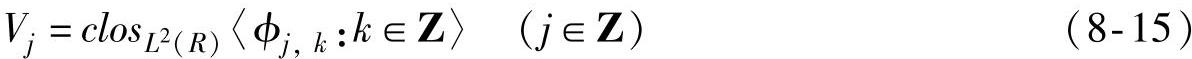
式(8-15)表示Vj是ϕj,k在平方可积空间L2(R)内线性张成的闭子空间,其中:
ϕj,k=2-j/2ϕ(2-jt-k) (8-16)
空间L2(R)的多分辨率分析是指函数ϕ(t)∈L2(R)在式(8-16)意义上生成的闭子空间序列Vj(j∈Z),并且具有以下性质:
①单调性:
Vj⊆Vj-1 ∀j∈Z (8-17)
②逼近性:
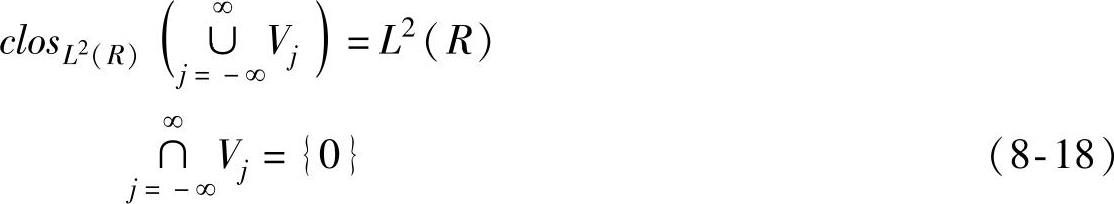
③伸缩性:
f(t)∈Vj⇔f(2t)∈Vj-1 (8-19)
④平移不变性:
f(t)∈Vj⇔f(t-2-jk)∈Vj (8-20)
⑤Riesz基存在性:存在ϕ(t)∈V0,使得{ϕ(t-k),k∈Z}构成V0的Reisz基。
从物理意义上讲,性质①描述了f(t)在分辨率2j-1上的分析包括了其在分辨率2j上分析得到的信息和更多的细节信息;性质②前半部分描述了函数f(t)能够用它在Vj上的近似fj非常接近地逼近,而后半部分保证了通过减小j,逼近fj能够具有任意小的能量;性质③和④表明了多分辨率分析具有和小波变换性质相对应的伸缩性和平移不变性;性质⑤保证了多分辨率分析和它对应的小波分析的稳定性,在Riesz基的意义上,称ϕ为Vj空间的多分辨率的生成元或尺度函数。
引入多分辨率分析的目的是建立小波分析。设小波函数ψ生成L2(R)空间中的小波子空间序列{Wj},即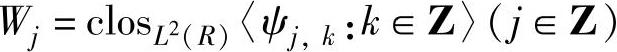 。这个序列给出L2(R)的一种直接和分解为
。这个序列给出L2(R)的一种直接和分解为
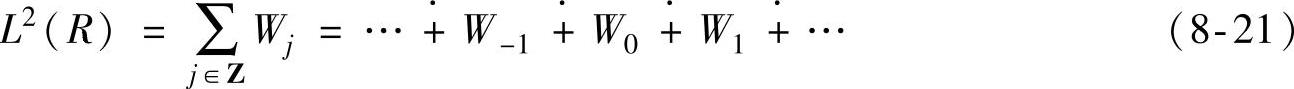
如果用gj∈Wj表示f(t)在Wj上的投影,则每个f(t)∈L2(R)可唯一分解为
f(t)=…+g-1(t)+g0(t)+g1(t)+… (8-22)
为了建立多分辨率分析与小波分析的联系,Wj要满足

式中,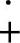 表示直接和。
表示直接和。
式(8-23)也就是说Wj是Vj在Vj-1中的补空间,同时说明f(t)在相邻分辨率上的近似fj和fj-1之间相差的细节信息是包含在空间Wj里的,即为gj。由式(8-23)还可以推出:

由式(8-21)和式(8-24)可得
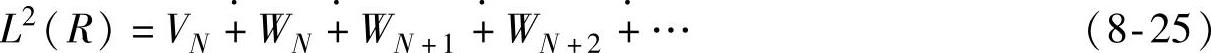
若fj∈Vj代表了函数f在分辨率2j上的近似(也称为模糊成分或粗糙成分),那么gj∈Wj就代表了逼近的误差(也称为细节成分),则式(8-23)和(8-25)就表示为
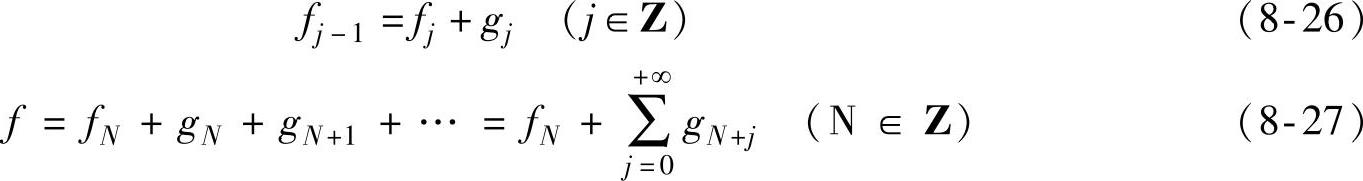
这表明,任何函数f(t)∈L2(R)都可根据它在分辨率2N上的粗糙信号和它在分辨率2N+j(j≥0)上的细节信号完全重构,这也就是Mallat算法的基本思想。
2)Mallat算法。因为尺度函数ϕ∈V0和小波函数ψ∈W0都属于V-1,而且V-1是由ϕ-1,k=21/2ϕ(2t-k)生成的,所以存在L2(R)空间中的两个序列{h1(n)}和{g1(n)},使
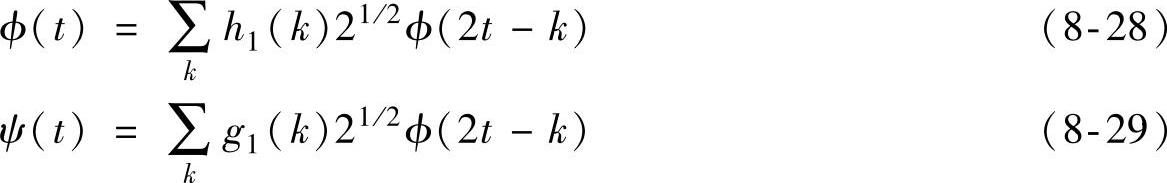
成立。式(8-28)和式(8-29)称为尺度函数和小波函数的双尺度关系。又由于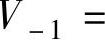
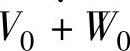 ,则V-1也可以由ϕ0,k=ϕ(t-k)和ψ0,k=ψ(t-k)共同生成,因此对ϕ-1,l∈V-1也存在L2(R)空间中的两个序列{h0(n)}和{g0(n)},使
,则V-1也可以由ϕ0,k=ϕ(t-k)和ψ0,k=ψ(t-k)共同生成,因此对ϕ-1,l∈V-1也存在L2(R)空间中的两个序列{h0(n)}和{g0(n)},使
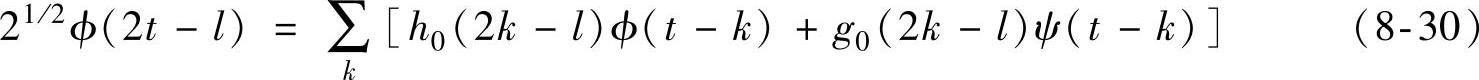
成立。与双尺度关系对应,式(8-30)称为尺度函数和小波函数的分解关系。对于一个小波函数和与它对应的尺度函数,它们之间的双尺度关系和分解关系是唯一确定的。
由于fj∈Vj、fj-1∈Vj-1和gj-1∈Wj-1,且ϕj,k、ϕj-1,k和ψj-1,k分别是Vj、Vj-1和Wj-1的基函数,所以有
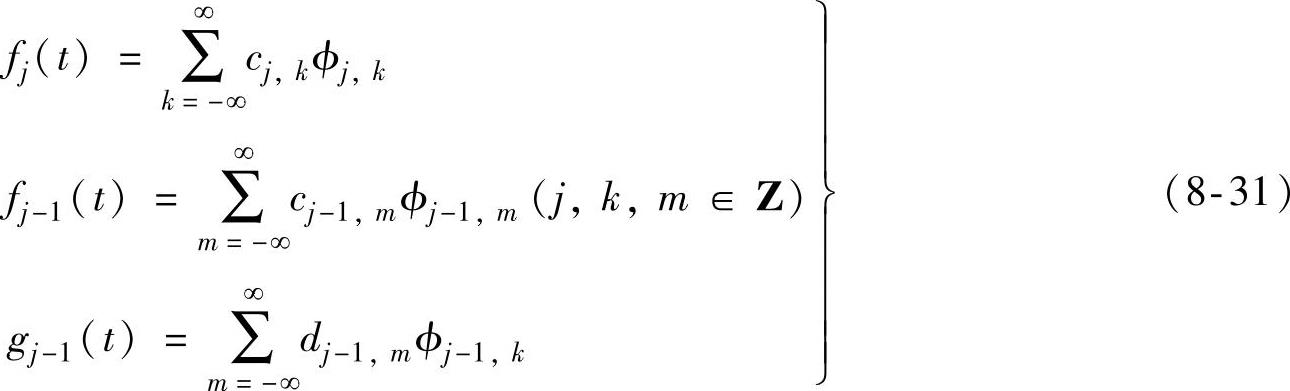
根据以上公式,可以推出{cj,k}、{cj-1,m}和{dj-1,m}的分解关系式为
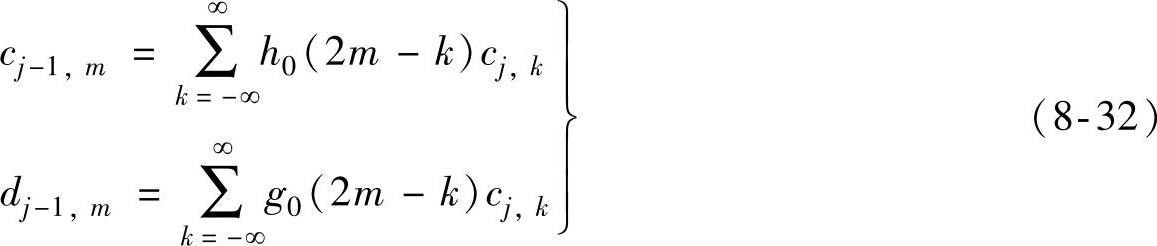
重构关系式为
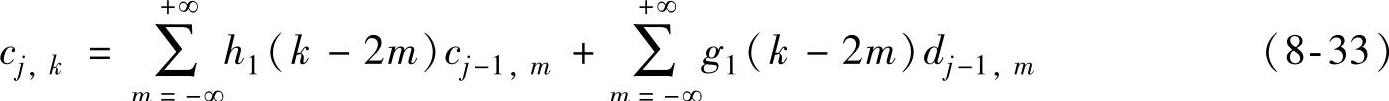
式(8-32)和式(8-33)就是离散小波变换的分解和重构关系式,也就是著名的Mallat算法。从信号处理和子带编码的角度看,Mallat分解算法的基本思想是把信号分别与一个处理信号高半带的高通滤波器g0和一个处理信号低半带的低通滤波器h0卷积后再抽样。由于低通滤波后信号频率减半,因此采样频率也可以减半;对于高通滤波后的信号,由于其带宽减半,虽然采样频率减半后会发生卷积,但此时的卷积不会造成频谱混叠。由此就可以得到一个描述原信号细节的高频成分和一个描述原信号的模糊的低频成分。重构算法是将高分辨率下的细节信号和模糊信号经补零后与重构滤波器g1和h1卷积后再求和,就得到了低分辨率下的模糊信号。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。