



高级语言编译器一般都支持许多的算术运算。编译器保证结果正确。然而,在实时软件中我们做这个计算将要花费很长时间。对于在处理器中支持的运算(如加法),编译器将产生代码,利用该硬件完成计算。对于处理器硬件中不支持的运算,编译器会生成软件来完成计算。总地来说,软件计算要比硬件计算慢得多。
TMS320C6x DSP没有硬件除法器,所以应尽可能避免除法。在下面的代码中,计算结果在数值上是相等的。
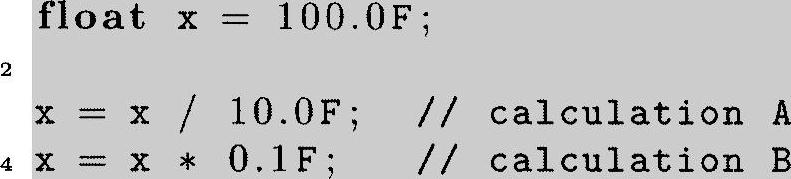
计算A指除法,在软件上,编译器会插入一段子程序调用来完成这一计算。因为处理器有硬件乘法器,因而计算B能被很快地完成。注意,数字上的后缀“F”指出它们浮点型常数,否则它们会被译为double型。执行这个双精度运算之前需要将“x”变为双精度类型。
当用一个数组变量来执行环形缓存存储时,当到达缓存的末尾时,索引值需要是“回环”。在下面的代码例子中,一个缓存和索引变量是分配好的。
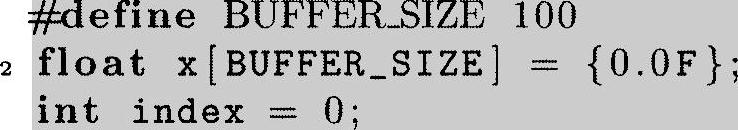
在下面的例子中,我们将假设索引值递增。递减的索引值将以类似的方式处理。也许实现循环索引看起来最直接的方法是仅仅检查索引值,当索引值达到缓存末尾时将其设为0。
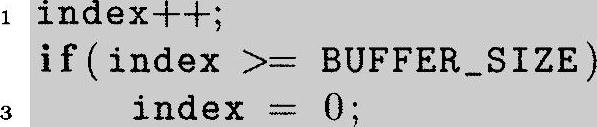 (https://www.xing528.com)
(https://www.xing528.com)
注意,这需要作一个比较,并且只限于index增加1。如果需要任意的增量值,我们需要使用另一种方法。取模运算提供了一种看来似乎较简单的解决办法。
然而,取模运算计算索引值除以缓存长度的余数,所以我们隐含地调用一个除法运算。作为一个选择,注意到如果增量比BUFFER_SIZE小,每当索引值大于或等于BUFFER_SIZE值的时候,我们能通过减去BUFFER_SIZE获得余数。

这使取模运算简化为有硬件支持的简单减法运算。然而,依然需要一个比较来判断是否索引值需要回环。在实时代码中,我们可以发现即使是这个运算依然是开销过多的。为了彻底消除比较运算,缓存大小设为2n。于是,循环寻址只需索引值index与2n-1的逻辑与操作即可完成。当index比BUFFER_SIZE小时,逻辑与使其保持不变。如果index大于或者等于BUFFER_SIZE,逻辑与运算的结果与取模运算的结果相同。

在应用中,在这个应用中缓存大小必须是2的幂。这是一个典型的软件在长度与速度之间的折中,这经常在产品化的代码中见到。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。