



IP在链路层运行,在到目的地的路由中,把包发给下一个路由器。在路由算法维护的路由表里,查找下一个路由器。为此目的开发的早期路由算法是基于距离矢量(Distance Vector)方案的。之后的路由算法使用链路状态方法。
在距离矢量方案中,每一个路由器维护一个表,表中规定下一跳路由器和一个表明通过这个路由器路由成本的度量,通过该路由器的路由到达网内的每一个其他路由器。路由的成本可以由一个参数决定,比如跳数、拥塞概率等。路由器周期地把表发送给它们的邻居。当路由器接到来自邻居的新路由表时,它将新的表和它自己的表比较,检查是否有通过发送表的邻居的更好路由。为此,该路由器把到达邻居的成本添加到接收表里的路由成本中。如果结果比它的表的值小,路由器就把下一跳的id用发送此表的邻居id替换掉,用该特定目的端的计算结果替换掉路由成本,这样就更新了路由表。
例如,假设图5-6a的节点b最初有路由表(见图5-6b),然后它收到节点e的路由表(见图5-6c)。节点b和e间的成本是1。根据节点e的路由表,节点e和d间的成本是2。因此,如果节点b通过节点e发送一个到节点d的包,总的成本是3。然而,在节点b的表中,节点b和d的成本是4,成本更高。因此,节点b就通过节点e发送一个到节点d的包,这样也就更新了节点b的表。类似地,它也更新与节点f和g有关的记录。
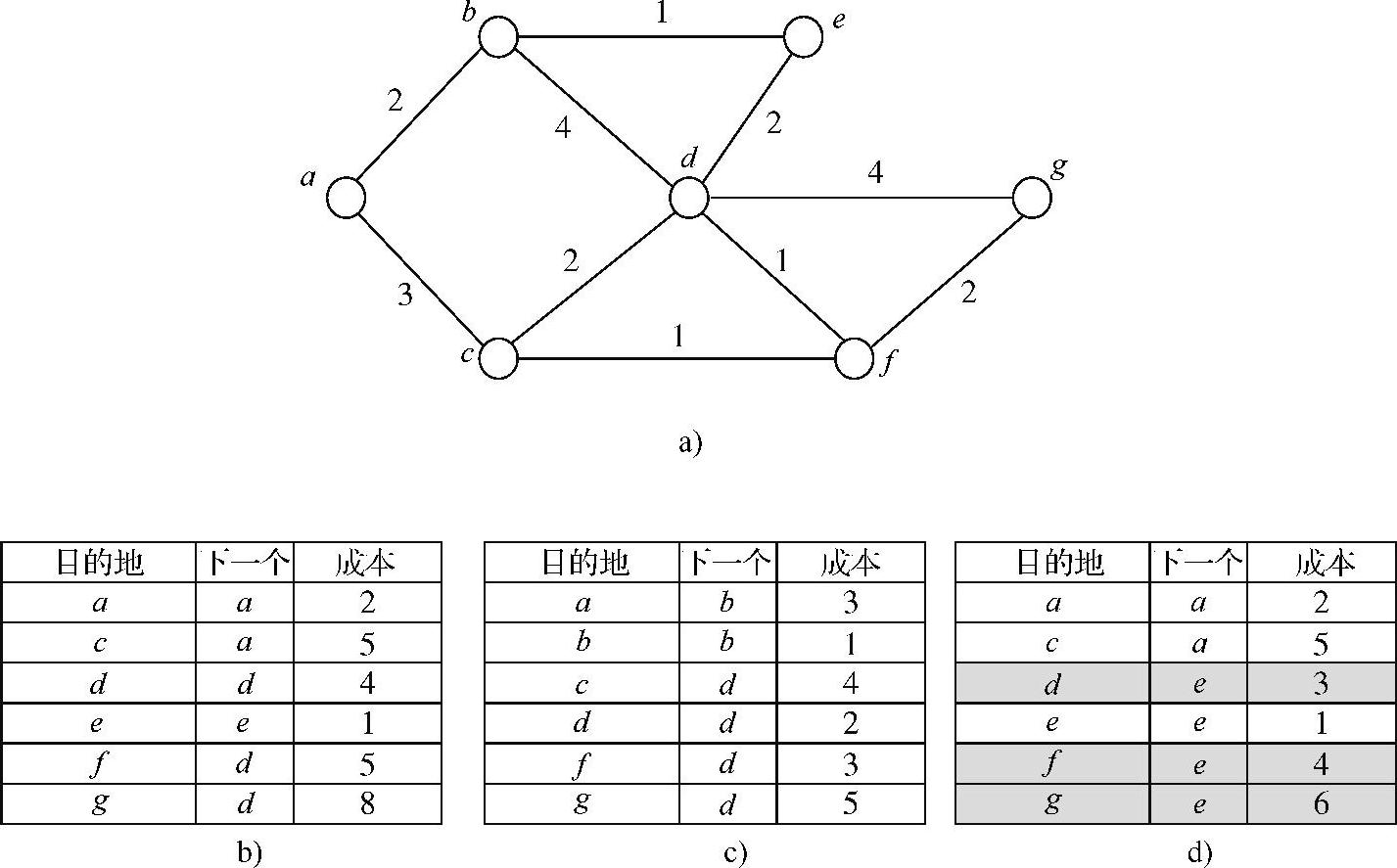
图5-6 距离矢量算法
a)示例网络 b)节点b的初始路由表 c)节点e的路由表 d)节点b的更新路由表(https://www.xing528.com)
距离矢量算法引入了一个“无限计数”(Count-to-infinity)的问题,就是路由器崩溃后,有关它的更新不能有效地扩散。为了理解这个问题,跟踪这种情况的算法,其中图5-6a中的每一个节点都有一个完美的路由表。节点d崩溃时,节点e发现这一情况,节点b和e用以下次序交换它们的路由表:b、e、b、e和b。有兴趣的读者可以参考Tannenbaum(2003)文献,了解更多“无限计数”问题。
链路状态方案不会有无限计数的问题。在该方案中,每个节点通过“ECHO”消息发现到邻居节点的延迟,并通过泛洪方式把此信息传播到网络上去。有一些与泛洪方式有关的小的挑战,比如负载邻居节点消息的循环和延迟。不过,相应地也有解决它们的办法。通过收集这些数据,每个节点对网络有一个完整的图像。然后,可以运行一种最短路径算法,决定网络中通向每一个其他路由器的最佳路由。
路由信息协议(Routing Information Protocol,RIP)是阿帕网(ARPANET)和因特网最初的路由算法,它是基于距离矢量方案的。之后的算法像开放最短路径优先(OSPF)算法和中间系统-中间系统(Intermediate System-Intermediate System,IS-IS)都是链路状态算法。
注意:各种攻击可以基于错误的更新或路由表信息设计。例如,一个恶意节点可以通过散布错误的路由表或链路数据,伪装成一个对其他路由器有吸引力的节点。这尤其对自组织网络中的路由更有威胁。我们将在以下章节和第8章中讨论对路由方案的各种类型的攻击。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。