



Ngiam等人[268,269]提出并评估了用神经网络来学习音频/语音和图像/视频模态特征的应用。他们论述了两感交叉(cross-modality)特征学习,指出在特征学习阶段,多模态(例如,语音和图像)会比只有一个模态(例如,图像)学到更好的特征。图11.3展示了一个用来分离音频/语音和视频/图像输入通道的双模深度自编码器(bi-modal deep autoencoder)架构。这个架构的本质是利用一个共享的中间层来表示两种模态。这是对第4章中图4.1单模态深度语音自编码器的一个直接推广。作者更进一步说明了如何去学习语音和视频的共同表示,并且在一个固定的任务中去评估它,分类器用语音数据进行训练,但是测试的时候用的是视频数据,反之亦然。这项工作的结论是:深度学习的架构通常对从无标注的数据中学习多模态特征以及通过两感交
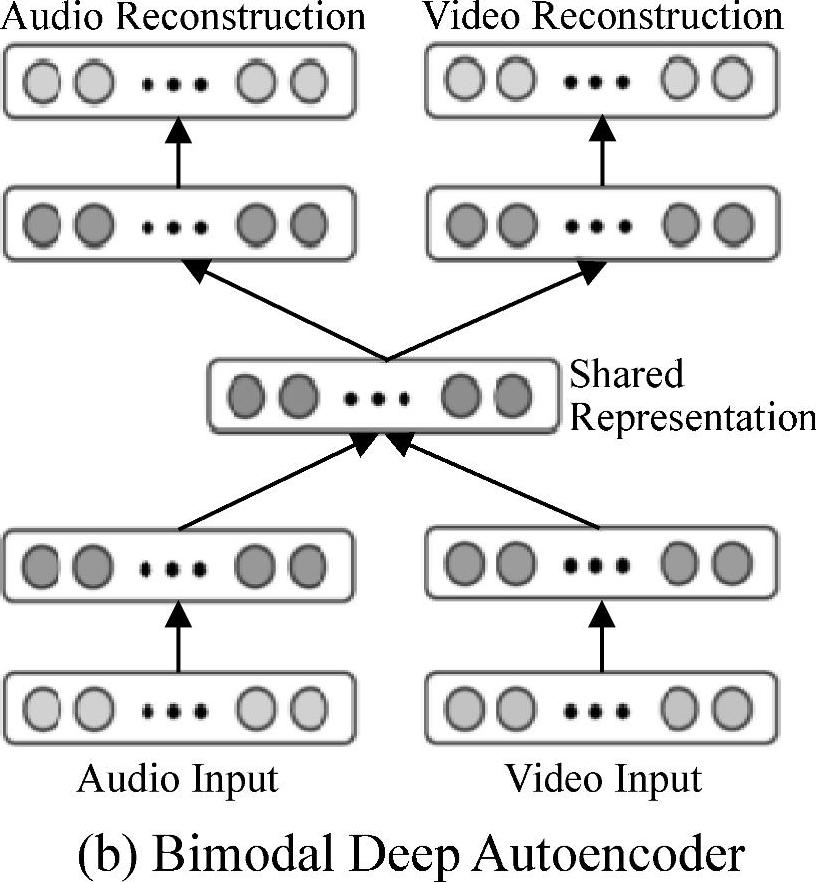
图11.3 用于多模态音频/语音和视觉特征的深度除噪自编码器的体系结构(参考文献[269],@ICML)
图中词语翻译对照表

叉信息传递来提高单个模态特征的情况是很有效的。但是这个方法在CUAVE数据库上出现了例外。文献[269,268]中的结果表明通过视频和音频去学习视频特征的效果优于仅用视频特征。然而,这篇论文同时指出文献[278]中用复杂信号处理技术提取的视觉特征,外加从鲁棒语音识别中提出的非确定性补偿方法,最终得到的模型在两感交叉学习任务上可以达到最好的分类精度,超越了深度结构的效果。
文献[268,269]中描述的用深度生成式架构来进行多模态学习的方法是基于非概率的自编码器,然而近来在相同的多模态应用中也出现了基于深度玻尔兹曼机(DBM)的概率型自编码器。在文献[348]中,一个DBM用来提取整合了不同模态的统一表示,这一表示对分类和信息检索任务来说都是很有帮助的。与为了表示多模态输入而在深度自编码器中采用的“瓶颈”层不同的是,这里我们首先在多模态输入的联合空间中定义一个概率密度,然后用定义的潜在变量的状态作为表示。DBM的概率公式在传统的深度自编码器中是没有的,因此这里概率形式的优势在于丢失的模态信息可以通过从它的条件概率中采样来弥补。最近自编码器的许多工作中表明[22,30],推广的降噪自编码器的采样能力使得填补缺失模态信息的问题看到了曙光。对于包含图像和文本的双模态数据,研究表明,多模态DBM比传统的深度多模态自编码器以及在分类和信息检索任务中的多模态DBN效果稍好。目前与推广的深度自编码器还没有比较的结果,但是相信结果可能很快就会出来。(https://www.xing528.com)
本章前面所讨论的多模态处理以及学习的若干架构可以看作是多任务学习(multi-task learning)和转化学习(transfer learning)的特例[22,47]。转化学习包含适应性和多任务学习,指的是一种学习架构或技术,可以发掘不同学习任务中隐藏的共同的解释性因素。这种方式允许不同的输入数据集进行一定的共享,因此是允许在看似不同的学习任务中进行知识传递的。文献[22]中认为,图11.4的学习架构和关联的学习算法对该类任务是有优势的,这是因为它能够学习捕捉潜在因素的表示,这些因素的子集和某个特定任务相关。我们将会在本章剩余的部分讨论语音、自然语言处理或者图像领域中若干多任务学习的应用。
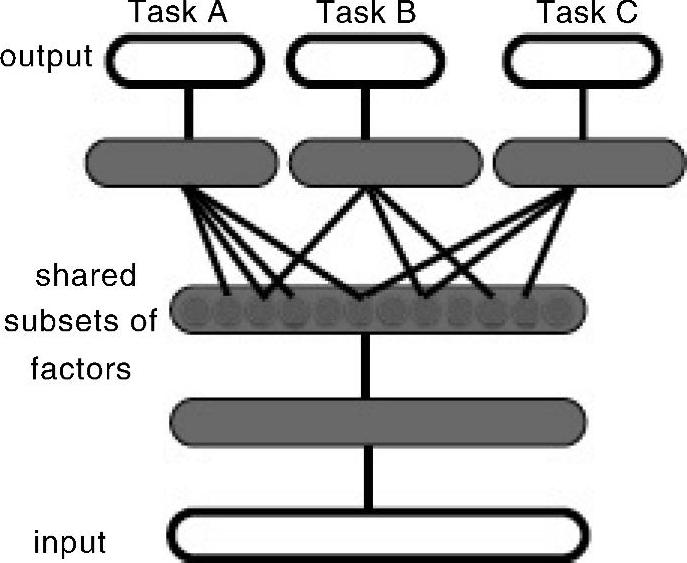
图11.4 在多任务学习中的一个DNN架构,旨在从三个任务A、B和C中发掘它们共享的隐藏解释因素。(参考文献[22]@IEEE)
图中词语翻译对照表
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。