



文本和图像可以进行多模态学习的根本原因是它们在语义层面是相互联系的。我们可以通过对图像进行文本标注来建立二者之间的关系(作为文本和图像多模态学习系统的训练数据)。如果相互关联的文本和图像在同一语义空间共享同一表示,那么系统可以推广到不可见(unseen)的情况;不管是文本还是图像缺失,我们都可以用共享的表示去填补缺失的信息,因此可以自然地应用于图像或文本的零样本学习。换言之,多模态学习可以使用文本信息来帮助图像/视觉识别,反之亦然。当然,这个领域的绝大多数研究集中在通过文本信息来进行图像/视觉识别中,我们将在下面进行讨论。
由Frome等人[117]提出的深层体系结构DeViSE(深度视觉—语义嵌入)是利用文本信息来提高图像识别系统性能的多模态学习的典型示例,这种体系结构尤其适合零样本学习(zero-shot learning)。当物体的类别太多时,很多图像识别系统是不能正常运转的,部分原因是由于随着图像的类别个数增加,获取足量带有文本标签的训练数据也越来越难。DeViSE系统旨在利用文本数据去训练图像模型。通过带有标注的图像数据以及从没有标注的文本中学习到的语义信息来训练一个联合模型,然后利用训练好的模型对图像进行分类。图11.1中间部分是对DeViSE体系结构的一个图解。用较低层的两个模型预训练得到的参数对DeViSE进行初始化,这两个模型分别是:图中左侧部分用于图像分类的深度卷积神经网络和图中右侧部分的文本嵌入模型。图11.1中标记为“核心视觉模型”的深度卷积神经网络部分通过标记为“转换”的投影层和一个相似度度量来进一步学习如何去预测词嵌入向量。训练阶段所采用的损失函数是内积相似度以及最大边界的结合体,即铰链排名损失。如9.3节所述,内积相似度是余弦损失函数的非归一化形式,目的是为了训练文献[170]中描述的DSSM模型。最大边界类似于较早的图像—文本模型WSABIE(由Weston等人[388,389]提出的运用图像嵌入进行大批量网络标注的方法)。结果表明,由文本提供的信息提高了零样本预测的准确性,使得成千上万在模型中未曾出现过的标签的命中率达到了比较好的水平(接近15%)。
文献[388,389]中描述了早期的WSABIE系统,它用浅层结构来训练图像和标注之间的联合嵌入向量模型。WSABIE使用简单的图像特征和线性映射实现联合嵌入向量空间,并非在DeViSE中利用深层结构来得到高度非线性的图像(文本向量也一样)特征向量。这样,每一个可能的标签都对应一个向量。因此,相比DeViSE来说,WSABIE不能泛化新的类别。
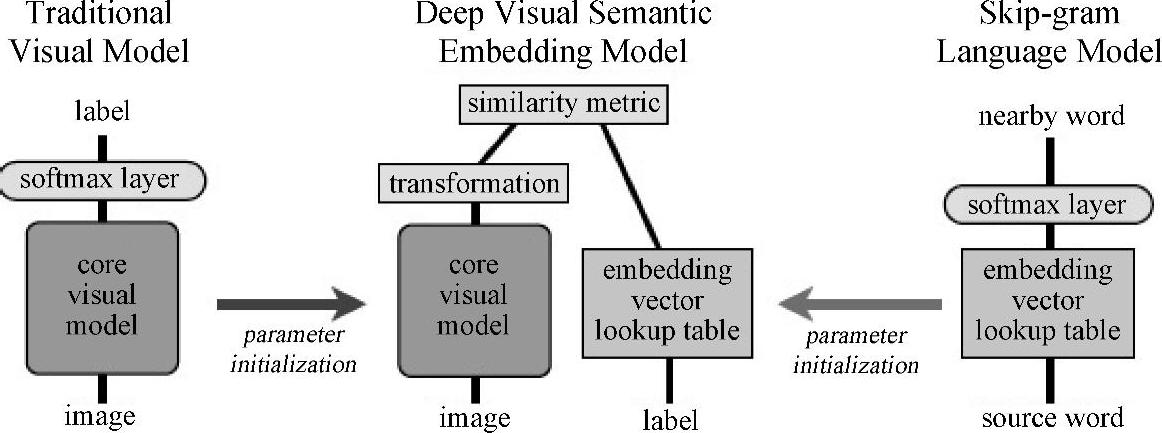
图11.1 多模态DeViSE架构图解。左侧部分是激活函数为softmax的输出层的图像识别神经网络;右侧部分是用来提供词嵌入向量的skip-gram模型,详见8.2节和图8.3;中间是带有两个在softmax层下用图像和词嵌入模型初始化的连接(Siamese)分支DeViSE的联合深度图像—文本模型,标记为“转化”层,将图像(左侧)和文本(右侧)分支的输出映射到同一语义空间(参考文献[117]@NIPS)。
图中词语翻译对照表
对比图11.1的DeViSE架构以及第9章中图9.2的DSSM体系结构,我们会看到一些很有意思的不同点。DSSM中的“查询”和“文档”分支类似于DeViSE中的“图像”和“文本—标注”分支。为了训练端对端的网络权重,DeViSE和DSSM所采用的目标函数都是和向量间余弦距离相关的。一个关键的不同点在于DSSM的两个输入集都是文本(例如,为信息检索设计的“查询”和“文档”),因此,相比DeViSE中从一个模态(图像)到另一个模态(文本)而言,DSSM中将“查询”和“文档”映射到同一语义空间在概念上显得更加直接。而另外一个关键的区别在于DeViSE对未知图像类别的泛化能力来源于许多无监督文本资源的文本向量(即没有对应的图像),这些资源包含未知图像类别的文本标注。而DSSM对于未知单词的泛化能力来源于一种特殊的编码策略,这种策略依据单词的不同字母组合来进行编码。(https://www.xing528.com)
最近,有一种方法受到DeViSE架构的启发,通过对文本标注和图像类别的向量进行凸组合来将图像映射到一个语义向量空间[270]。这种方法和DeViSE的主要区别在于,DeViSE用一个线性的转换层代替最后激活函数为softmax的卷积神经网络图像分类器。新的转换层进而和卷积神经网络的较低层一起训练。文献[270]中的方法更为简单——保留卷积神经网络softmax层而不对卷积神经网络进行训练。对于测试图像,卷积神经网络首先产生N个最佳候选项。然后,计算这N个向量在语义空间的凸组合。即得到softmax分类器的输出到向量空间的确定性转化。这种简单的多模态学习方法在ImageNet的零样本学习任务上效果很好。
另一个不同于上述工作但又与其相关的研究主要集中在多模态嵌入向量的使用上,来源于不同模态的数据(文本和图像)被映射到同一向量空间。例如,Socher和Fei-Fei[341]利用核典型相关性分析(kernlized canonical cor-relation)将词和图像映射到同一空间。Socher等人[342]将图像映射到单个词向量,这样构建的多模态系统可以对没有任何个例的图像类别进行分类,类似于DeViSE中的零样本学习。Socher等人的最新工作[343]将单个词的嵌入拓展为短语和完整句子的嵌入。这种从词到句子的拓展能力,来源于递归神经网络和对依存树的扩展。8.2节对Socher等人[347]的递归神经网络进行了概述。
除了将文本到图像(反之亦然)映射为同一向量空间或者创建一个联合的图像/文本嵌入空间,文本和图像的多模态学习也同样适用于语言模型的框架。在文献[196]中,研究着眼于建立一种自然语言模型,这个模型依赖于其他模态,例如图像模态。这类多模态的语言模型被用于(1)对于给定的复杂描述的查询来检索图像;(2)对于给定的图像查询检索出相应的短语描述;(3)给出图像相关文本的概率。通过训练多模态语言模型和卷积神经网络的组合来联合学习词表示和图像特征。图11.2是多模态语言模型的一个图解。
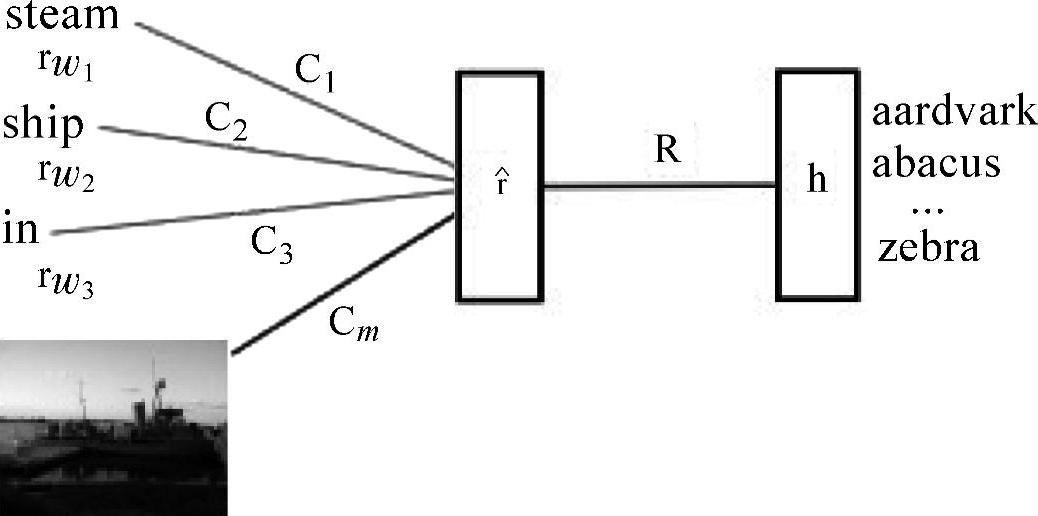
图11.2 多模态语言模型。预测所得的下一个单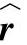 是由图像特征x偏差引出的词特征rw1,rw2,rw3,的线性预测(参考文献[196],@ICML)
是由图像特征x偏差引出的词特征rw1,rw2,rw3,的线性预测(参考文献[196],@ICML)
图中词语翻译对照表
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。