



多年以来,机器学习一直都是自然语言处理(NLP)的主要工具。然而在NLP中,机器学习的使用大多数都仅限于从文本数据中人为设计的表示(和特征)权重的数值优化。深度学习或表征学习的目的是自动从原始文本中学习能广泛适用于各种NLP任务的特征或表征。
最近,基于深度学习方法的神经网络在很多NLP任务上都取得了不错的效果,比如语言模型、机器翻译、词性标注、命名实体识别、情感分析和复述检测(paraphrase detection)。深度学习方法最吸引人的方面是它们能够出色地完成这些任务,而不用额外的人为设计的资源和耗时的特征工程。为此,深度学习开发和使用了一个重要的概念——“嵌入”(embedding),指用连续实值向量来表示自然语言文本中词级、短语级甚至是句子级的符号信息。
早期的一些工作[62,63,367]已经凸显了词嵌入的重要性,虽然这起先只是文献[26]中语言模型的副产品。原始的基于符号的词表示可以通过神经网络从高维的1/V编码稀疏向量(例如,V是词表的大小或者其二次方甚至三次方)转化为低维实值向量,由随后的神经网络层进行处理。连续空间表示词或者短语的主要优点是其分布特性,这可以对相同含义的词语表示进行共享或聚类。这种共享是不可能在用高维1/V编码来表示词语的原始符号空间进行的。词的上下文作为神经网络中的学习信号,并使用无监督学习方法进行训练。Socher等人[338,340]提供了一些不错的教程,解释了神经网络是如何训练来得到词嵌入的。最近一些研究工作提出了训练词嵌入的新方法,它结合了局部或全局的上下文文档,可以更好地获取词的语义信息;同时通过学习每个词的不同嵌入方式,很好地解释了同音异义和一词多义现象。文献[245]同样证明了RNN可以在词嵌入的训练中获得更好的性能。NNLM主要目的是为了预测上下文中的下一个词,并产生了词嵌入这样的副产品,这是一种获得词嵌入更简单的方法,而且不用进行词预测。Collobert and Weston[62]等人的研究证实,和NNLM中通常需要的规模庞大的输出节点不同,训练词嵌入的神经网络需要的输出节点要少得多。
在词嵌入早期的工作中,Collobert和Weston等人将卷积神经网络作为一个通用模型同时去解决一系列经典的问题,包括词性标注、断句、命名实体识别、语义角色识别以及相似词识别。在最近的文献[61]中,基于深层递归卷积结构,研究者提出了一种更快、区分性更强的方法来做语义分析。Col-lobert等人[63]对统一神经网络结构和相关的深度学习算法在解决“从零开始做NLP”的问题上的应用做了详细的综述,摒弃了传统NLP的特征提取方法。这一系列工作的目的是尽量避免与特定任务相关的人工特征工程,同时提供自动从深度学习中获取灵活统一的特征,而这些特征适用于所有的自然语言处理任务。文献[63]中汇报的系统,在多种NLP任务中,可以从大量无标注的训练数据中学习到内在表征或词嵌入。
Mikolov等人最近的工作简化了8.1节中NNLM获取词嵌入的过程。NNLM可以通过两个步骤进行训练。首先使用一个简单模型学习到连续词向量,模型消除了神经网络上层的非线性误差,所有词共享投影层。其次,在词向量之上训练一个N元文法NNLM。这样,去掉NNLM的第二步后,使用一个简单的模型去学习词嵌入,这样就可以使用大量的数据了。因此产生了一个称为连续词袋模型(Continuous Bag-Of-Words,CBOW)的词嵌入模型,如图8.3左所示。由于在语言模型中目标不再是计算词序列的概率,词嵌入系统可以更有效,不仅仅能够基于上下文预测当前词,而且能够进行反演预测(inverse predic-tion),这称为跳跃文法模型(skip-gram),如图8.3右所示。作者后续的工作[250]中,将跳跃文法模型的词嵌入系统扩展成一种更快的学习方法,称为负采样(negative sampling),与8.1节中讨论的NCE相似。
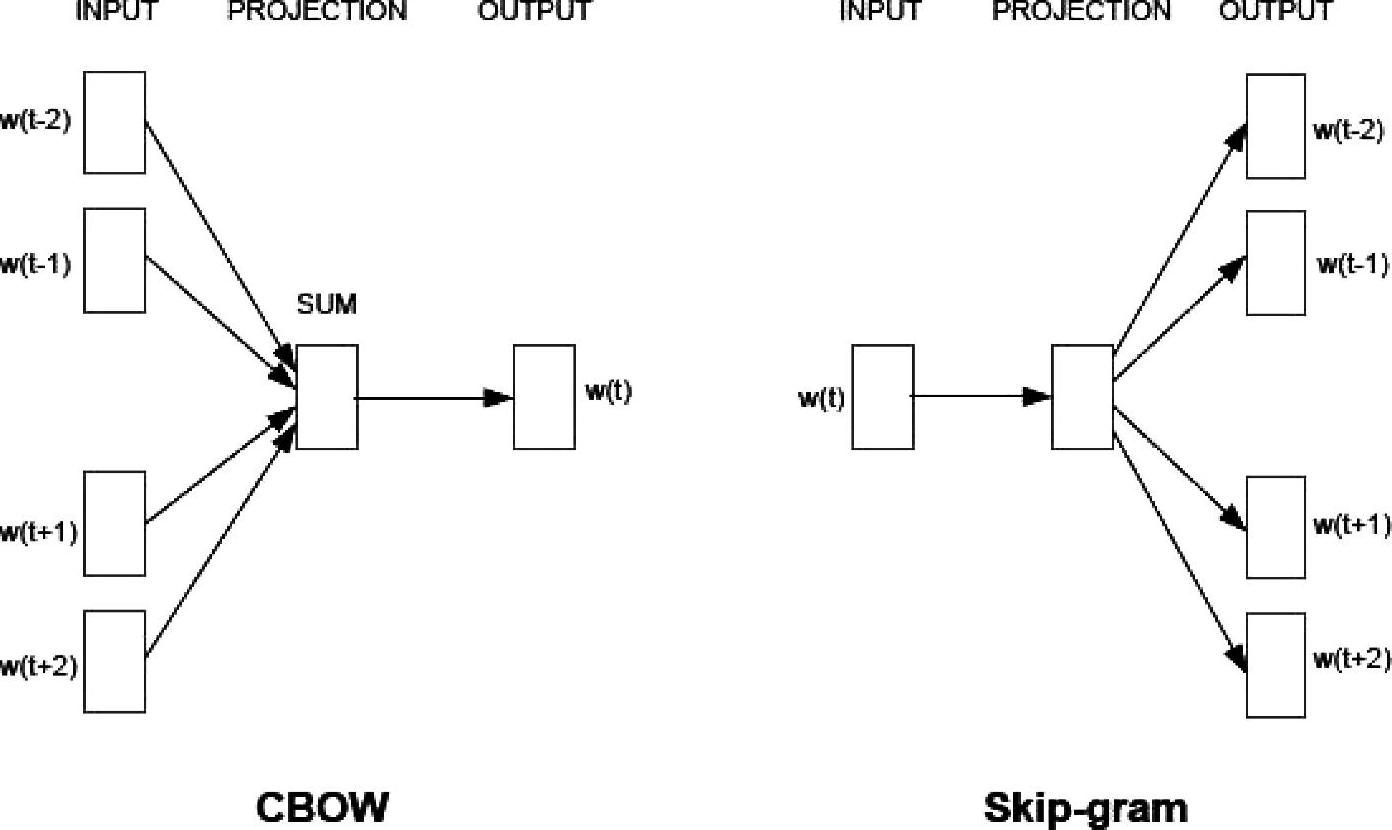
图8.3 左图为CBOW架构;右图为Skip-gram构架(参考文献[246],@ICLR)
图中词语翻译对照表
与此同时,Mnih和Kavukcuoglu等人[254]证实了轻量级词嵌入NCE训练是一种更高效、词表征质量更好的训练方法,这与8.1节中Mnih和Teh等人提出的轻量语言模型有些相似。因此,过去依赖大量硬件和软件架构才能得到的结果,现在可以在单台桌面计算机上用很少的编程工作和更少的时间和数据来获得。最近的工作也表明,在表征学习上,NCE只需五个噪声样本就足够了,比语言模型中要求的少很多。作者也用了一种“反演语言模型”(inversed lan-guage model)去计算词嵌入,与在文献[250]中跳跃文法模型使用的方法相似。
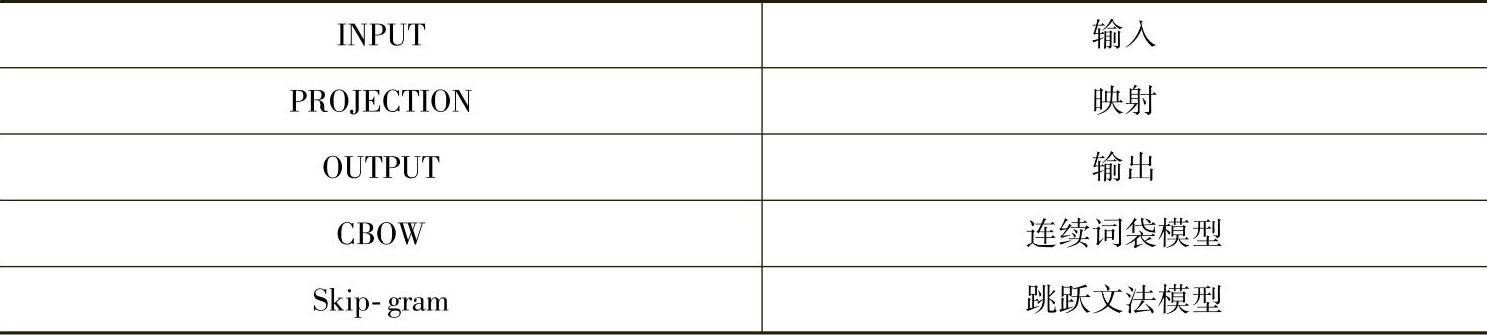
Huang等人意识到早期词嵌入工作的局限性,即这些模型只是使用了局部上下文,而且每个词采用一种表示。为此,他们扩展了局部上下文模型,使得模型可以结合整句或者整个文档的全局上下文。这些扩展模型可以通过学习每个词的多种嵌入方式,解决同音异义和一词多义问题,如图8.4所示。该研究组早期的工作[344]使用局部上下文的递归神经网络去建立一个深层结构。尽管缺少全局上下文,基于从原始特征学习到的语义信息,这个网络仍然具有合并自然语言的词语的能力。这种深度学习的方法在自然语言句法分析应用上的效果很好。在自然场景图像解析任务上,这种方法的效果也取得了成功。其他相关的研究,比如在复述检测(paraphrase detection)[346]和从文本预测情感分布中也使用了类似的递归深层结构[345]。

图8.4
图8.4展示了扩展的词嵌入模型,使用了递归神经网络,同时考虑了局部和全局上下文。全局上下文从文档中提取出来,并放到全局语义向量中,作为原始局部上下文词嵌入模型输入的一部分。本图来自于文献[169]中图1。(参考文献[169]@ACL)
图中词语翻译对照表
现在我们讨论深度学习方法(包括神经网络结构和词嵌入)应用在实际NLP任务上的工作。机器翻译是研究人员多年以来一直探索的一个典型的NLP任务,多年的研究集中在浅层统计模型上。文献[320]的工作或许是第一个全面的基于词嵌入的神经网络语言模型的成功应用,该工作针对大型机器翻译任务,可以在GPU上进行训练,解决了计算复杂度高的问题,可以在20小时内训练5亿个词。该工作获得了很好的结果:词嵌入神经网络语言模型与最好的回退语言模型(back-off LM)相比,困惑度从71下降到60,对应的BLEU分数提高了1.8%。
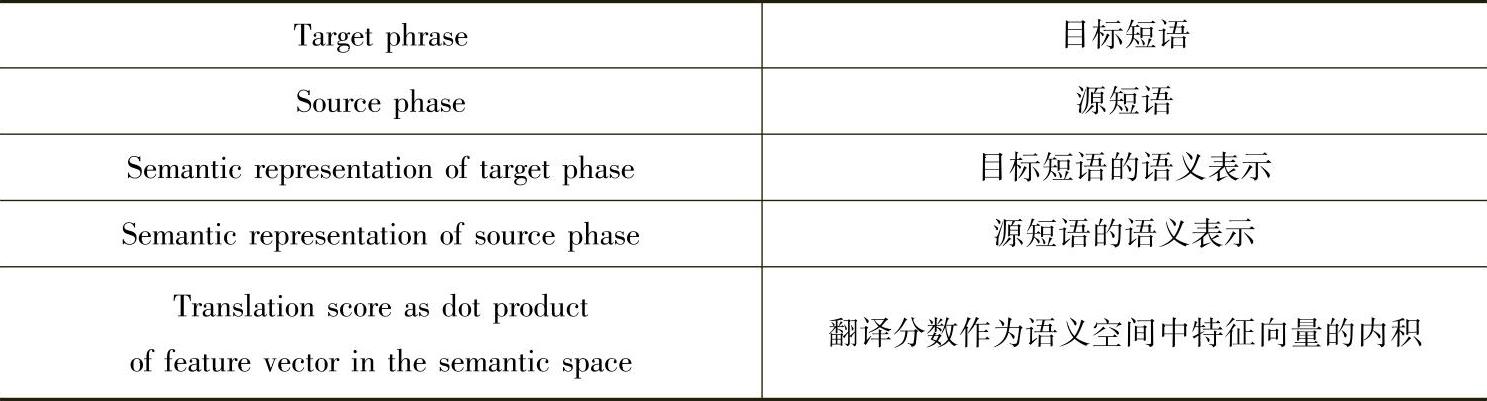
文献[121,123]是将深度学习方法应用在机器翻译上的最近的研究工作。在该工作中,短语翻译模块(而不是机器翻译系统中的语言模型模块)被具有语义词嵌入的神经网络模型所替换。图8.5为这种方法中的结构,成对的源短语(标注为f)和目标短语(标注为e)被映射到低维潜在语义空间的连续实值向量表示上(标注为两个y向量)。翻译分数可以通过在这个新的空间中的计算向量对的距离获得。通过两个深度神经网络进行映射,网络权重可以从平行训练语料训练得到。学习的目标是直接最大化端对端的机器翻译质量。在两个标准的Europarl翻译任务上(英语-法语和德语-英语)的实验评测结果表明,新的基于语义短语的翻译模型大大的提高了基于短语的统计机器翻译系统的性能,在BLEU上提高了1%。(https://www.xing528.com)
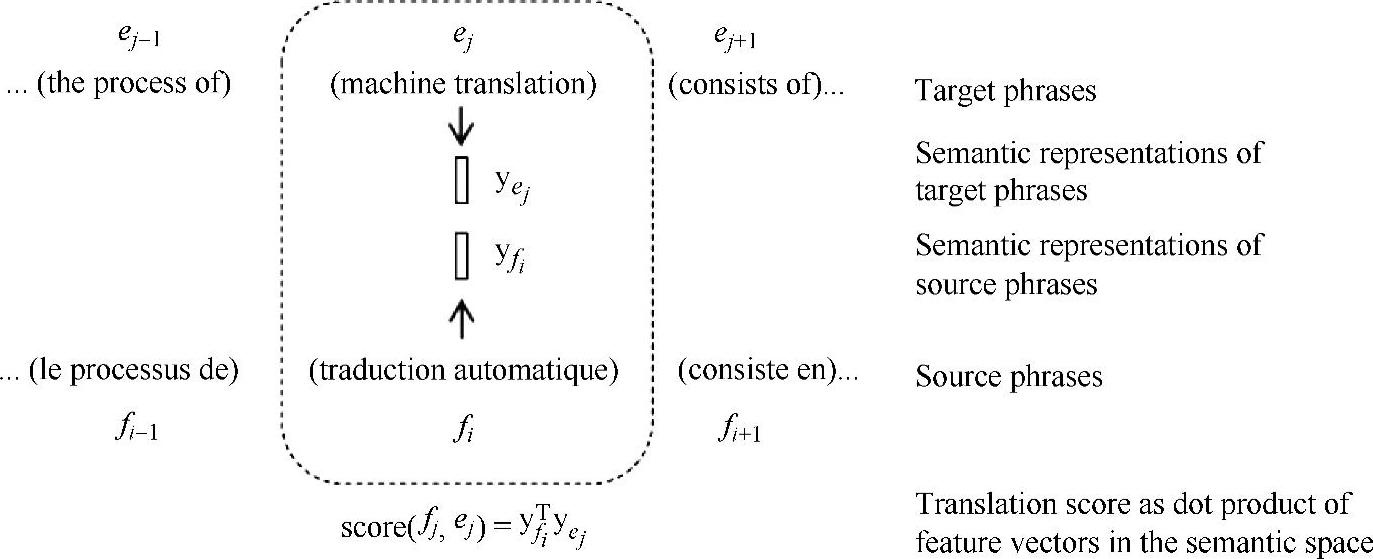
图8.5
图8.5为文献[122]中的机器翻译系统示意图。源(标注为f)和目标(标注为e)平行短语被映射为连续实值向量表示(标注为两个向量y)。翻译分数通过在这个连续空间上的向量距离来计算。通过两个深度神经网络(标注为两个箭头)进行映射,网络权重可以从平行训练语料训练得到。
图中词语翻译对照表
Schwenk[320]提出了另外一种和上述方法相关的机器翻译方法。在该方法中,基于短语的机器翻译系统中的翻译模型概率估计通过神经网络进行计算。短语对的翻译概率可以通过神经网络生成的连续空间表示学习得到。该方法做了一个简化:一个短语或句子的翻译概率被分解成N元文法语言模型中N元文法概率的乘积。相比之下,Gao[122,123]等人的方法则不使用原始语言和目标翻译语言短语间的联合表示。
文献[249]提出了另外一种基于深度学习的机器翻译方法。在其他方法中,一种语言的语料库中的词与同一语料库另外一种语言的词相比,双语数据中具有相似统计特征的词和短语认为是对等的。而文献[249]提出了一种新的方法,可以自动生成从一种语言转换成另外一种语言的词典和短语列表。它不依赖于不同语言相同文档的语料,相反,它用数据挖掘技术去建模源语言的结构,然后与目标语言的结构进行比较。通过学习大规模单语数据的语言结构对缺失单词和短语进行翻译,然后把他们映射到少量双语数据语言之间。这是基于前面讨论的基于向量的词嵌入,它能学到源和目标语言向量空间之间的一个线性映射关系。
文献[111]是早期应用基于DBN的深度学习技术去解决机器音译(transliteration)问题的研究,这是一个比机器翻译简单得多的任务。这种深层结构及其学习应该可以推广到更困难的机器翻译问题上,但是目前还没有此类后续的工作。作为另外一个早期的NLP应用,Sarikaya等人[318]应用DNN(论文中称作DBN)去处理基于自然语言的呼叫路由(call-routing)任务。DNN使用无监督学习方法发现多层的特征,然后用来最大化区分性。与随机初始化权重的神经网络相比,无监督特征使得DBN很少出现过拟合,无监督学习可以使多层神经网络的训练更容易。研究表明,与其他广泛应用的学习技术(如最大熵和基于Boosting的分类器)相比,DBN可以获得更好的分类结果。
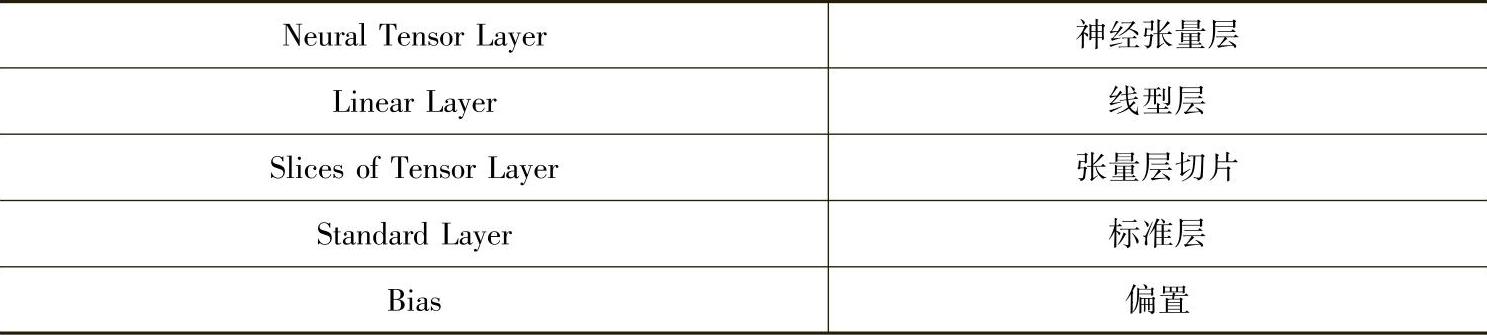
深度学习方法在NLP中最有趣的应用之一是知识库(本体)补全(knowleage based(ontology)completion),该任务在问答(question-answering)和其他NLP应用中起着举足轻重的作用。文献[37]是这方面早期的工作,它引入了自动学习知识库结构化分布式嵌入(structured distributed embeddings)的方法。连续值向量空间的表示是紧凑的,并且可以从大量实体和关系数据中有效学习到。它使用了一种专门的神经网络结构,即一种生成式“连接”(Si-amese)网络的推广。接下来的工作[36]集中在多关系数据的学习中,提出了一种语义匹配能量模型,可以同时学习实体和关系共同的向量表示。文献[340]中使用了另外一种方法,基于神经张量网络(neural tensor network),解决关系分类任务中的大型联合知识图谱的推理问题。知识图谱表示为两个实体之间的三元组关系,在这一基础上,作者提出了一种适合在这些关系上做推断的神经网络结构。他们提出的是一种神经张量网络,只有一层。网络用固定维度的向量表示实体,可以通过平均预训练的词嵌入向量获得。图8.6是神经张量网络的图例,用虚线框表示两个张量模型。文献[340]的实验结果表明,这种张量模型可以有效的区分WordNet和FreeBase中一些不可见(unseen)的关系。

图8.6
图8.6为文献[340]中的神经张量网络,两种关系表示为两个张量层。张量层标记为W[1∶2];网络包含双线性张量层,直接与两个实体向量(标记为e1,e2)相关联。一个虚线框表示一个张量层。(参考文献[340],@NIPS)
图中词语翻译对照表
最后我们要介绍的是深度学习在NLP上另外一个成功的应用:Socher提出的将递归生成模型应用于情感分析[347]。在这里,情感分析是指通过一个算法从输入文本信息中推断积极或者消极的情绪。正如我们本章之前讨论的,由神经网络获得的语义空间中的词嵌入很有用,但是很难用一种有原则的方法来表达长短语的含义。情感分析的输入通常是很多词和短语,嵌入模型需要组合(compositionality)属性。为了做到这一点,Socher[347]等人提出递归神经张量网络,每一层的建立与文献[340]中描述的神经张量网络模型一样,如图8.6所示。整个网络具有组合属性的递归的构建,依据了文献[344]中介绍的常规非张量网络。在一个精心设计的情感分析数据库上进行训练后,递归神经张量网络在多个指标上都比以前的方法要好。新模型将目前在单句上正/负情绪分类的精度从80%提升到85.4%。对所有短语预测的精细粒度的情感标签(fine-grained accuracy labels)正确率达到了80.7%,比特征袋(bag-of-features)基线系统提高了9.7%。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。