



最近几年中,自从全连接(fully-connected)DNN-HMM[67,68,109,161,257,258,308,309,324,429]混合系统的巨大成功之后,研究者们提出了许多新架构和非线性单元,并评估了它们在语音识别中的功效。这里,我们将对这些工作的发展进行综述,作为对文献[89]中综述的扩充。
Yu等人[421,422]介绍了DNN的张量(tensor)版本,对传统的DNN进行了扩展,使用双投影层和张量层替代DNN中的一层或多层。在双投影层,任一输入向量投影到两个非线性的子空间。在张量层,两个子空间投影相互作用,在整个深度架构中共同预测下一层。一种方法是将张量层映射到传统的sigmoid函数层,因此前者就可以像后者一样进行处理和训练。由于这种映射,张量型的DNN可以看成是对DNN使用双投影层进行扩充,这样后向传播学习算法便可以清晰地推导,也相对容易实现。
和上述相关的一个架构是第6节介绍的张量型DSN,它可以有效地应用到语音分类和识别领域[180,181]。采用同样的方法将张量层(即DSN上下文的许多模块的顶层)映射到传统的sigmoid函数层。这种映射再一次简化了训练算法,使其并不偏离DSN。
如3.2节的讨论,时域卷积的概念源于延时神经网络(time-delay neural network,TDNN),并作为一种浅层神经网络[202,382]在早期语音识别中得到了发展。最近,研究者发现应用深层架构(如深度卷积神经网络CNN)后,在高性能音素识别任务中,当HMM用来处理时间可变性时,频率域权值共享比之前类似TDNN中的时域权值共享更为有效(TDNN不使用HMM)[1,2,3,81]。这些研究也说明合理的设计池化(pooling)策略,并结合“dropout”正则化技术[166],可以对声道长度不变性和语音发音之间的区分性进行有效折中,从而达到更好的识别结果。这些工作进一步指出:使用池化和卷积在混合的时域和频域里,对贯穿整个语音动态特性的轨迹区分性和不变性进行折中,是一个重要的研究方向。此外,最近的研究报告[306,307,312]也显示,大词汇量连续语音识别也可以从CNN中受益。这些研究进一步说明:使用多个卷积层,且卷积层使用大量卷积核或特征映射时,会有更大的性能提升。Sainath[306]广泛探索了许多深度CNN的变种。在和许多新方法的结合下,深度CNN在一些大词汇量语音识别任务上取得了领先的结果。
除了DNN、CNN、DSN和它们对应的张量版,许多其他深度模型在语音识别领域也得到了应用和发展。比如,深度结构的CRF,它具有很多堆叠的CRF层,也有效地应用到了语种识别[429]、音素识别[410]、自然语言处理中的序列标注[428]、语音识别中的置信度校正[423]等许多任务。最近,Demuynck和Triefenbach[70]发展了深度GMM(deep GMM)架构,DNN强大的性能得到借鉴并应用到构建分层的GMM。他们的研究表明,结构“变深与变宽”,同时将底层GMM的加窗概率输入到高层GMM中,深度GMM系统的性能足以与DNN相比。GMM空间的一个优点是:数年以来在GMM上的自适应和判别式学习方法仍然适用。
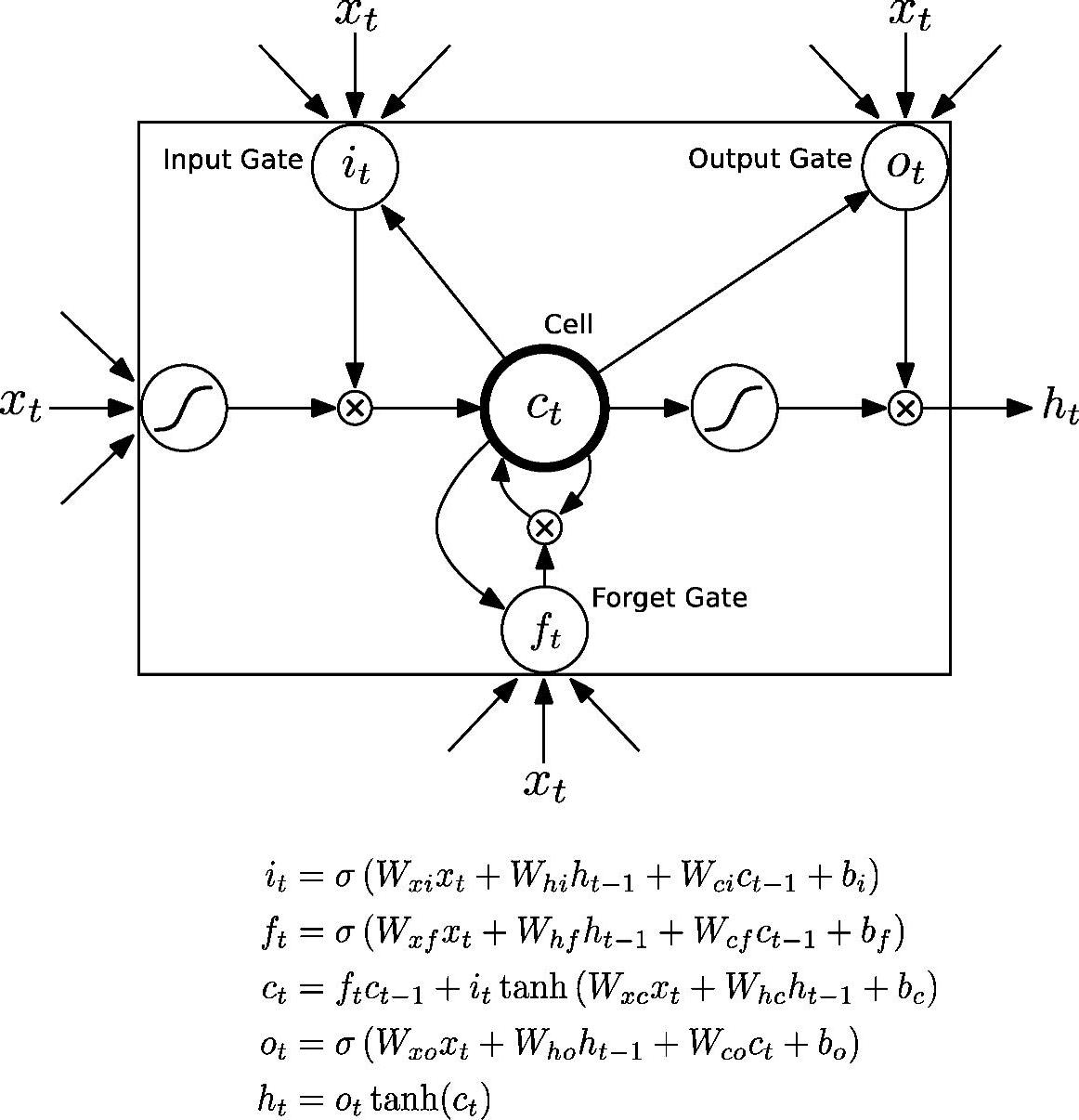
或许最值得注意的深度结构是回归神经网络(RNN)及其堆叠或深度版本[135,136,153,279,377]。尽管RNN最早在音素识别[304]中取得成功,但由于其训练的错综复杂性,很难推广,更不用说应用在大规模的语音识别任务上了。此后,RNN的学习算法得到很大的提升,也获得了更好的结果,特别是双向长短时记忆(Bi-directional Long Short-Term Memory,BLSTM)单元的使用。双向RNN的信息流和LSTM的基本单元分别如图7.3和7.4所示。
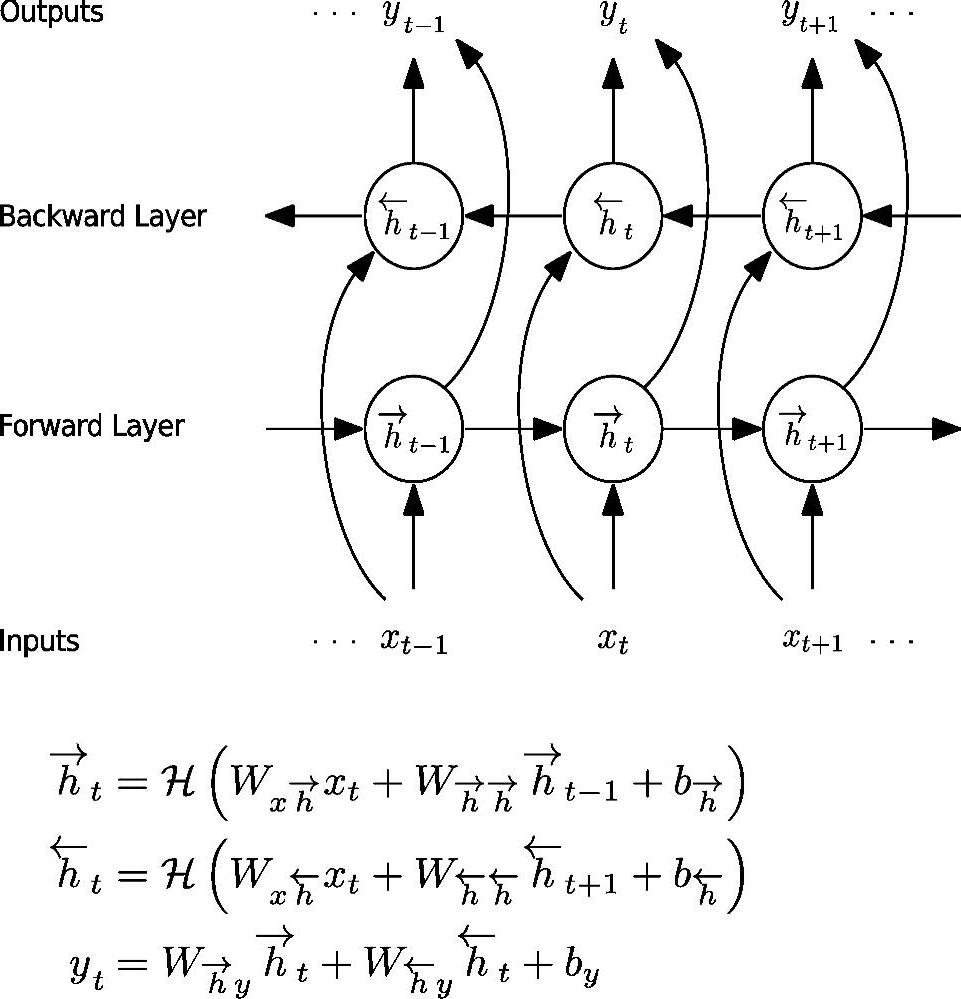
图7.3 双向RNN的信息流,给出了示意图和数学公式。W是权值矩阵,图中没有标注出来(参考文献[136],@IEEE)
图中词语翻译对照表

 (https://www.xing528.com)
(https://www.xing528.com)
图7.4 RNN中LSTM单元的信息流,给出了示意图和数学公式。W是权值矩阵,图中没有标注出来(参考文献[136],@IEEE)
图中词语翻译对照表

众所周知,由于梯度消失或者爆炸的问题[280],学习RNN的参数十分困难。Chen和Deng[48,85]开发了一种原始-对偶(primal-dual)的训练方法,它将RNN的学习问题抽象为标准的优化问题,通过最大化交叉熵,限制RNN的循环矩阵小于固定的值,从而保证动态RNN的稳定性。在音素识别的实验结果如下:(1)原始-对偶技术对训练RNN非常有效,优于早先限制梯度的启发式方法。(2)使用DNN计算的高层语音特征作为RNN的输入,相比没有使用DNN,其识别精度更高。(3)当从高层到低层提取DNN特征时,识别精度逐渐下降。
RNN的一种特殊形式是储藏模型(reservoir models)或回响状态网络(echo state network),其中将普通RNN中的输出层非线性单元改为固定的线性单元,权值矩阵是精心设计而非训练学习所得。由于参数学习的困难性,输入矩阵也是固定的,并非学习而来。只有隐层和输出层之间的权值矩阵是通过学习而来。由于输出是线性的,全局优化有封闭形式的解,所以参数学习非常高效。但是因为许多参数并非学习得到,所以隐层必须足够大才能获得足够好的结果。Triefenbach[365]将这种模型应用到音素识别,获得了不错的识别精度。
Palangi等人[276]提出了一个上述储藏模型的改进版。在该模型中,之前固定的输入和回归矩阵都是通过学习得到的。之前模型使用线性输出(或“读出”readout)去简化RNN输出矩阵的学习。而且,他们提出了一种利用储藏模型的线性输出学习输入矩阵和回归矩阵的特殊技术。与训练一般RNN的时间误差反向传播算法(backpropagation through time,BPTT)相比,这个技术给利用线性输出单元特性给RNN中不同的矩阵增加了限制,替换BPTT的递归梯度,以可分析的形式学习信号来计算梯度。
除了上面介绍的最近用于语音识别的深度学习模型之外,近来在设计和实现更好的非线性单元上也不断涌现出新的研究工作。尽管sigmoid和tanh是DNN最常用的非线性单元,但它们的缺点也很明显。例如,当网络单元在两个方向都接近饱和时,梯度变化很小,整个网络的学习变得很慢。Jaitly和Hinton[183]为了克服sigmoid单元的缺点,最先在DNN语音识别中使用整流线性单元(Rectified Linear Units,ReLU)。ReLU是指在网络中使用形如f(x)=max(0,x)的激活函数。Dahl[65]和Mass[234]成功地在大词汇量语音识别上应用ReLU,当结合ReLU和正则化技术dropout时获得最好的识别精度。
最近提出的另一种在语音识别上有用的DNN单元是“最大输出”(max-out)单元,它用于构建深度最大输出网络,如文献[244]所述。一个深度最大输出网络由多层以maxout为激活函数的单元组成,在一组固定输入权值上进行最大化(或称maxout)操作。这与之前讨论的语音识别和计算机视觉中的最大池化(max pooling)类似。每一组最大值作为前一层的输出。最近,Zhang等人[441]将maxout单元推广为两类,第一种soft-maxout将原来的最大化操作替换为soft-max函数;第二种p-norm单元使用非线性的y=‖x‖p。实验表明,p-norm单元使用p=2时,比maxout、tanh和ReLU单元效果都好。Gulcehre等人[138]提出了自动学习p-norm的方法。
最后,Srivastava等人[350]提出另一类新的非线性单元,称作winner-take-all单元。他将临近的神经元之间的竞争纳入前向网络结构,之后使用不同的梯度进行反向传播训练。Winner-take-all是一种非常有趣的非线性单元的形式,它建立了神经元组(通常为2个),在一组之中,除了最大值神经元,其他所有神经元都为0值。实验表明,使用这种非线性单元的网络比标准的sig-moid非线性网络具有更好的记忆性。这种新型非线性单元还有待于在语音识别任务上评测。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。