



【摘要】:图5.3中DBN/DNN和HMM结合组成一个DNN-HMM,它是由Microsoft提出的,这种结构已经被成功地使用在文献[67,68]语音识别实验中。因此,将前馈神经网络和HMM结合,能够有效地弥合静态和序列模式识别之间的差别。语音的时间动态特殊性正如文献[45,73,76,83]中所描述的那样复杂,所以要想取得语音识别的最终成功,还需要比HMM具有更强的短时相关特性的模型。
到目前为止,本章所介绍的混合深度网络的典型例子——含预训练的DNN,实际上是一个具有固定输入维数的静态分类器。但是许多实际的模式识别和信息处理问题,包括语音识别、机器翻译、自然语言理解、视频处理以及生物信息处理等,都需要序列识别。序列识别,有时也被称为结构化输入/输出分类,输入和输出的维数都是变量。
图5.3中DBN/DNN和HMM结合组成一个DNN-HMM,它是由Microsoft提出的,这种结构已经被成功地使用在文献[67,68]语音识别实验中。(参考文献[67,68]@IEEE)
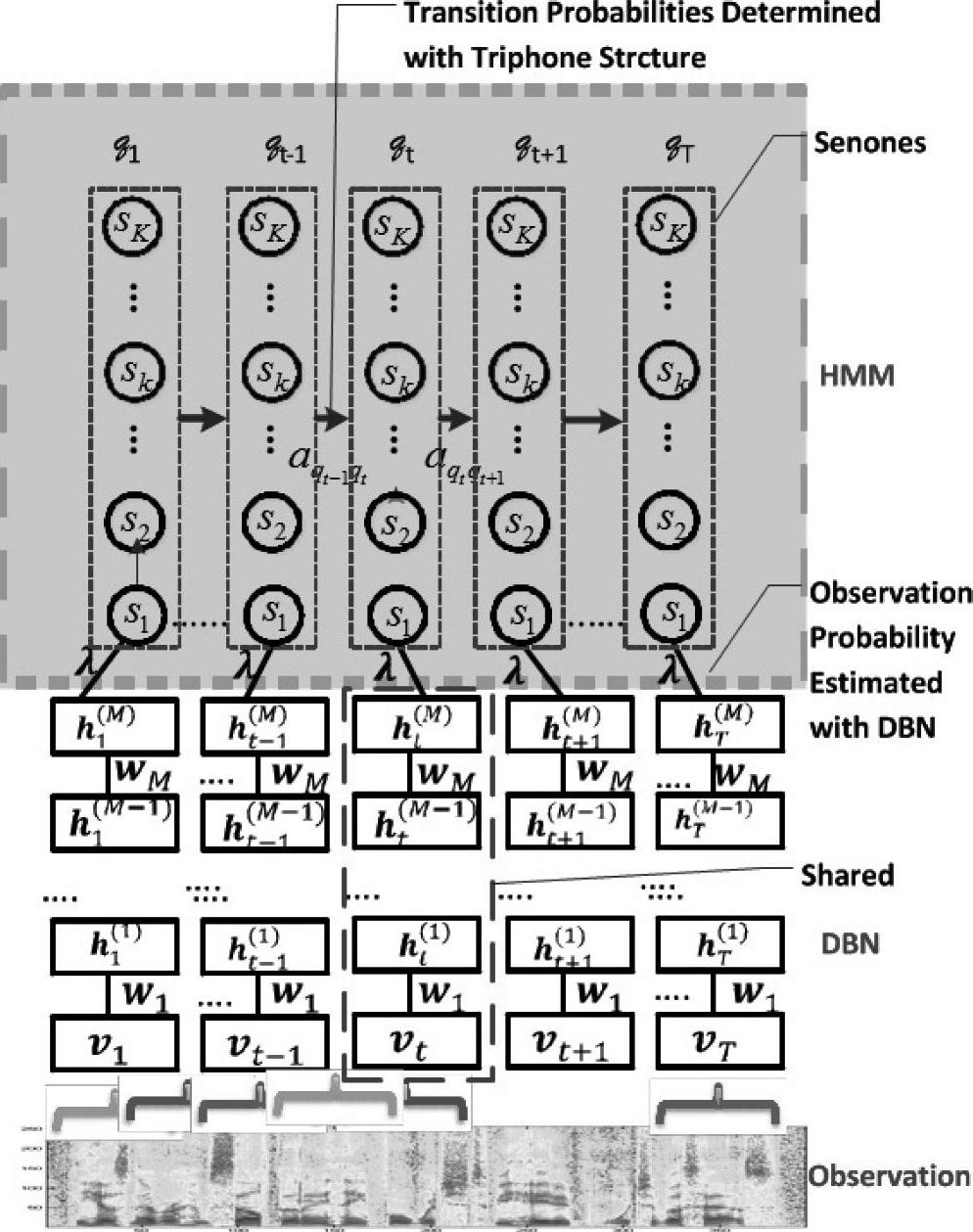
图5.3
图中词语翻译对照表(https://www.xing528.com)

基于动态规划运算的HMM,能够有效地将静态分类器的优势发挥到处理动态或者序列模式任务上。因此,将前馈神经网络和HMM结合,能够有效地弥合静态和序列模式识别之间的差别。早期的基于神经网络的语音识别[17,25,42]中就已经采用了这种方法。图5.3说明了使用DNN来实现这种结构的方法,这种结构已经在文献[67,68]中成功应用到语音识别中。
语音的时间动态特殊性正如文献[45,73,76,83]中所描述的那样复杂,所以要想取得语音识别的最终成功,还需要比HMM具有更强的短时相关特性的模型。将实际协同发音(co-articulatory)特性和DNN以及其他深度学习模型结合,组成连贯动态深度结构(coherent dynamic deep architecture),将是一个极具挑战性的新的研究方向。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。