



下面我们将对一系列工作进行回顾。一些发表于文献[100]中的工作利用无监督的方法(例如,没有语音分类标签)设计一个自编码器,用于从原始语音的语谱图数据中提取二进制的语音编码,这种依据该模型提取的二进制编码而得到的离散表示可以用于语音信息检索或者作为瓶颈特征(bottleneck features)用于语音识别。
图4.1描绘的是文献[100]中的深度自编码器框架,从高分辨率语谱图中提取二值化语音编码。该图描述了一个深度生成模型,对包含256个频带和1,3,9或13帧数据的语谱图进行建模。该图建立了一个被称为高斯-伯努利受限玻尔兹曼机(Gaussian-Bernoulli RBM)的模型,该模型具有一个由线性变量组成并含高斯噪声的可见层和一个有500~3000个二值化隐变量的隐层。在训练完这个高斯-伯努利受限玻尔兹曼机后,将其隐层单元的激活概率作为输入数据来训练另一个伯努利-伯努利受限玻尔兹曼机(Bernoulli-Bernoulli RBM)。之后可以将这两个受限玻尔兹曼机组合成深度置信网络(DBN),通过单次前向传递很容易地从输入数据中推断出深度置信网络中第二层的节点状态,即第二层各个二值化隐单元的状态。图4.1中左侧的图描述了该工作中的DBN,其中两个受限玻尔兹曼机分别在两个矩形框中展示(关于RBM和DBN更详细的讨论参见第5章)。
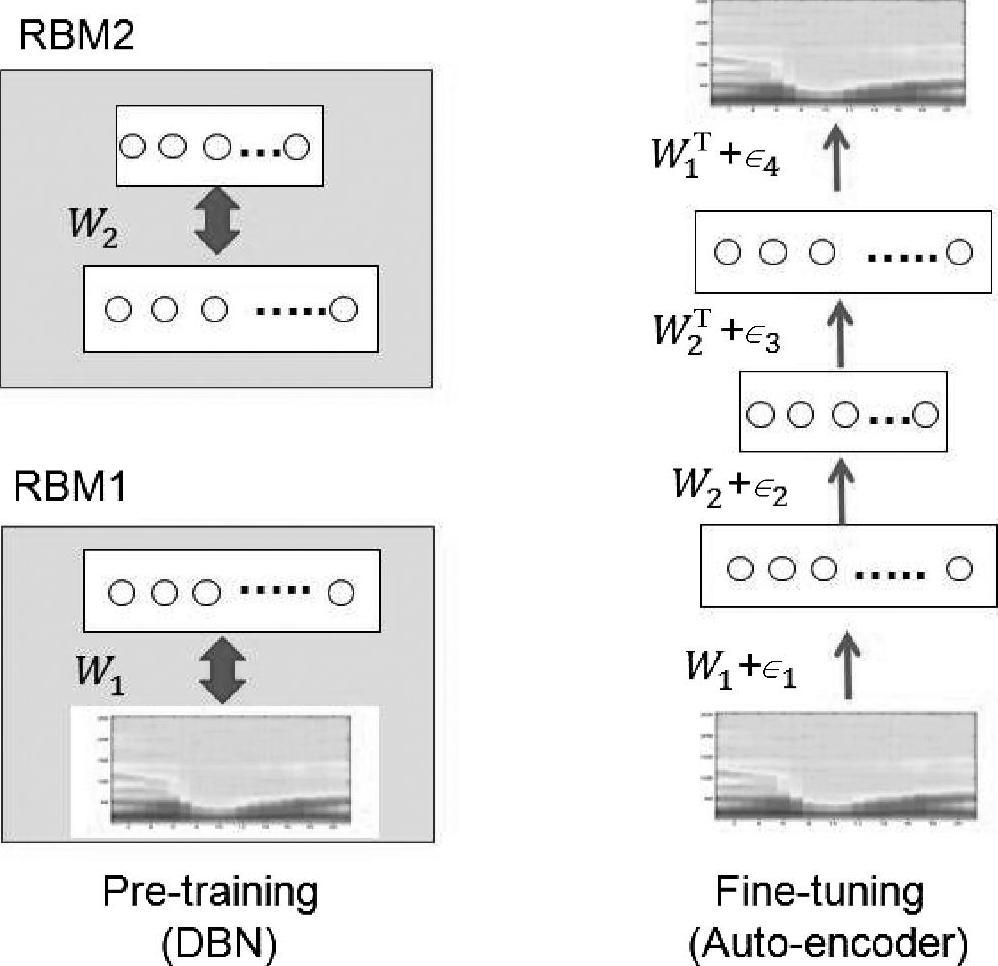
图4.1
图中词语翻译对照表
有三个隐层的深度自编码器可以通过“展开(unrolling)”DBN的权值矩阵来形成。这个深度自编码器下面的层利用矩阵对输入进行编码,而上面的层用矩阵对输入进行解码。之后,这个深度自编码器利用误差反向传播的方法来进行微调以最小化重构误差,该过程参见图4.1的右侧。当学习过程完成后,任何长度可变的语谱图可以按以下步骤进行编码和重构。首先,N个来自对数能量谱的连续交叠帧(各帧含256个点),在按特征的每一维在所有样本上进行零均值单位方差归一化后,以提供给深度自编码器作为输入。然后,第一个隐层利用逻辑函数(logistic function)计算得到实值激励,这些实值激励被送入下一编码层来计算“编码”。在编码层,隐层单元的激励以0.5为阈值量化为0或1,将这些二进制编码应用于重构原始语谱图,利用最前面的两层网络权值重构每个单独的固定帧语谱块。最后,对每个连续的N帧数据构成的窗,利用深度自编码器来产生输出,用信号处理中标准的叠加法(overlap-and-add)对输出数据进行处理,然后利用处理后的数据来重构整个语谱图。下面,我们以图示的方式来举例说明编码和重构。
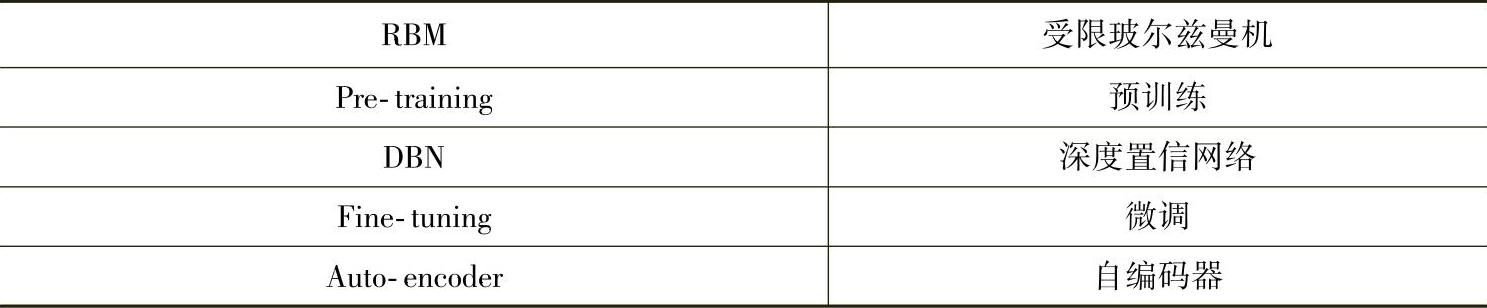
图4.2自上而下依次为:原始的语谱图;分别用大小为N=1,3,9和13的输入窗且强制编码单元采用0,1两种数值(即二进制编码)而得到的各种重构结果图。

图4.2
图中词语翻译对照表

图4.2的顶部为原始的、未编码的语音;下面分别是含312个节点的瓶颈编码层(bottleneck code layer)对窗长为N=1,3,9,13的情况进行二进制编码(0和1)后重构得到的语音句子。可以清楚地发现,N=9和N=13这两种情况的重构误差很低。
我们可以将深度自编码器的编码误差与矢量量化(Vector Quantization,VQ)这种更传统的编码方式进行定性的比较。图4.3展示了不同方法的编码误差。最上面的是句子原始的语谱图。紧接着下面的两个语谱图,一个由312位矢量量化方法重构而来,相对模糊;另一个由312位深度自编码器重构而来,看起来相对可靠。按时间顺序描述的两种编码方法带来的编码误差的函数图像绘制在语谱图的下方。它证明了由自编码器重构的结果在整个语句上的错误率均低于矢量量化(VQ)重构而来的结果。最下面的两个图在时-频坐标下显示了详细的编码错误分布。

图4.3
图4.3中自上而下依次为:来自测试集的一段语音的原始语谱图;由312位矢量量化方法重构的语谱图;由312位自编码器重构的语谱图;时域上矢量量化编码方法和自编码器编码方式的编码误差;矢量量化方法语谱图残差;深度自编码器方法语谱图残差。参考文献([100],@Elsevier)
图4.4~图4.10显示了其他的一些示例,对比了原始未编码的语音语谱和用深度自编码器重构的结果。它们展示了在给定不同的二进制编码位数的情况下,对语谱图中单独的一帧或连续的三帧数据进行编码的情况。

图4.4(https://www.xing528.com)
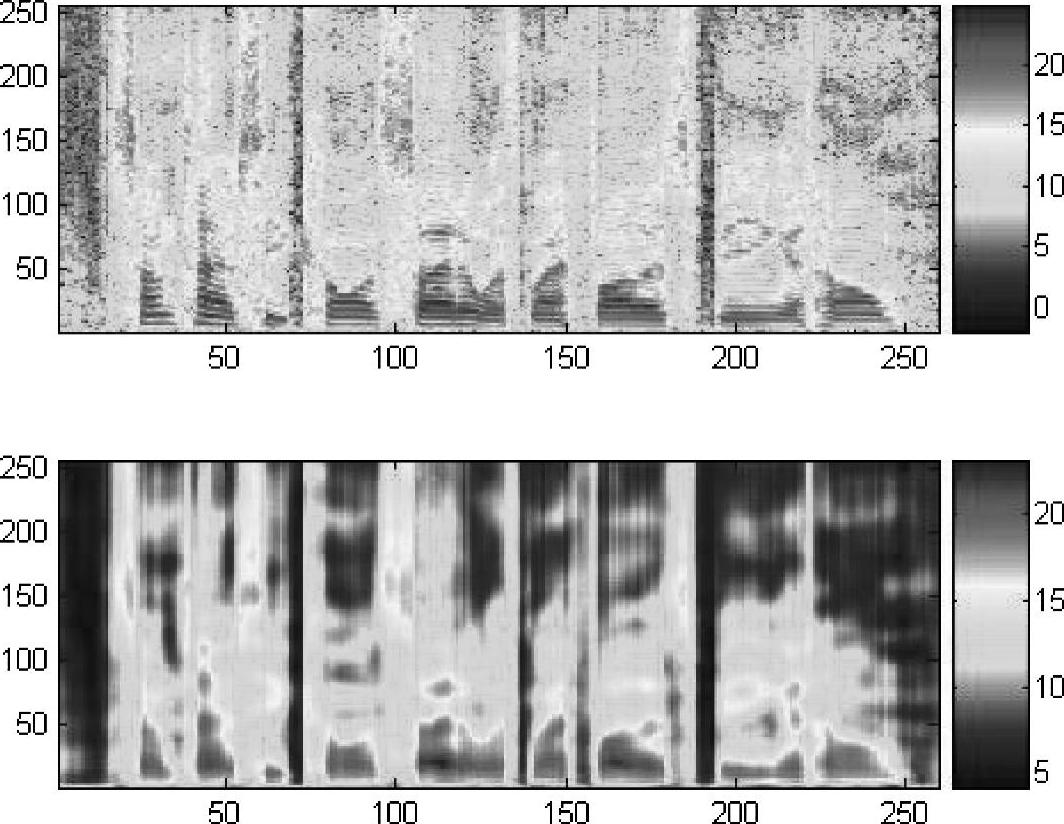
图4.5
图4.4为原始语音的语谱图和对应的重构结果。共采用312个二进制码对单独的每一帧编码。
图4.5与图4.4的方法相同,但语音来自TIMIT集合中的另一个语句。
图4.6为原始语音的语谱图和对应的重构结果。共采用936个二进制码对连续的三帧数据进行编码。
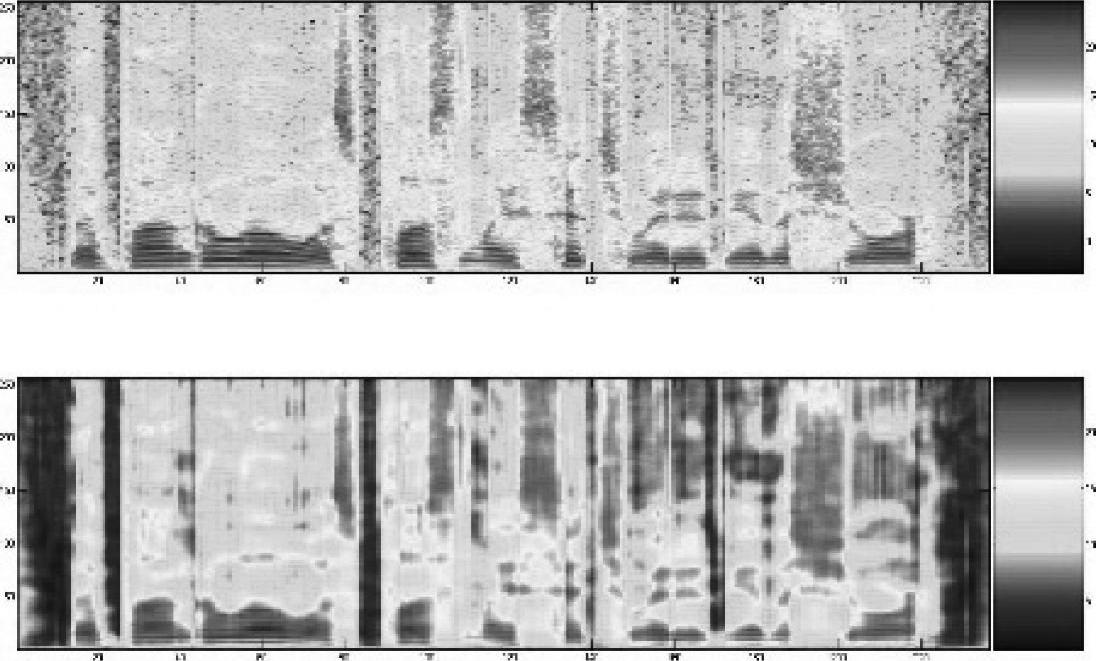
图4.6
图4.7与图4.6的方法相同,但语音来自TIMIT集合中另一个语句。
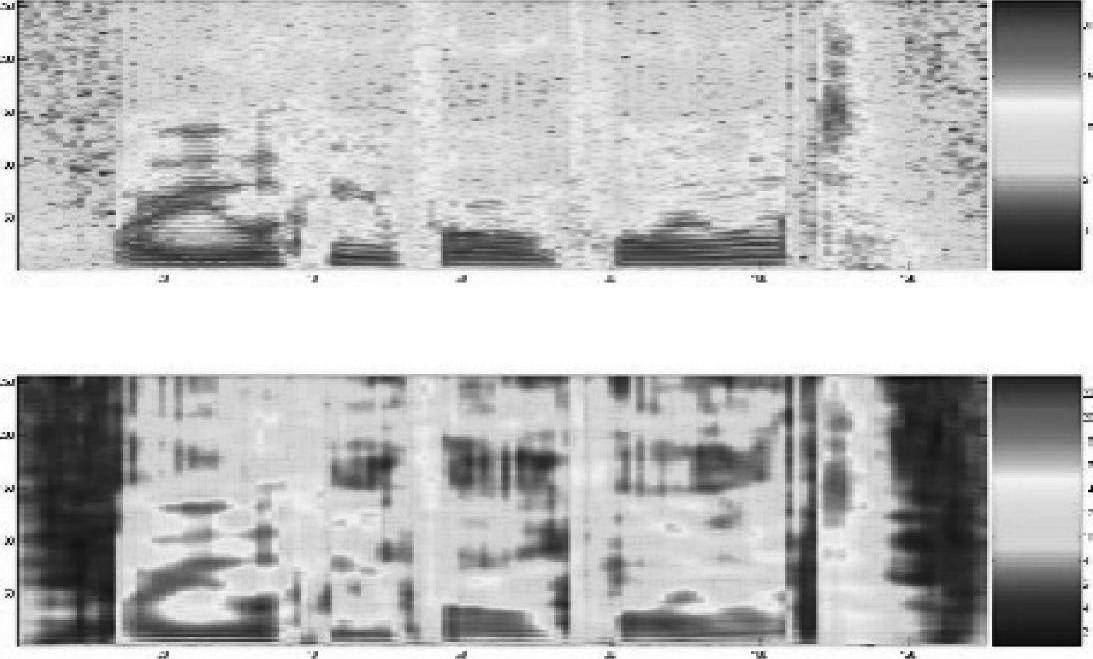
图4.7
图4.8与图4.6的方法相同,但语音来自TIMIT集合中另一个不同语句(即不同于图4.6和图4.7)。
图4.9为原始语音的语谱图和对应的重构结果。共采用2000个二进制码对单独的每一帧进行编码。
图4.10与图4.9的方法相同,但语音来自TIMIT集合中的另一个语句。
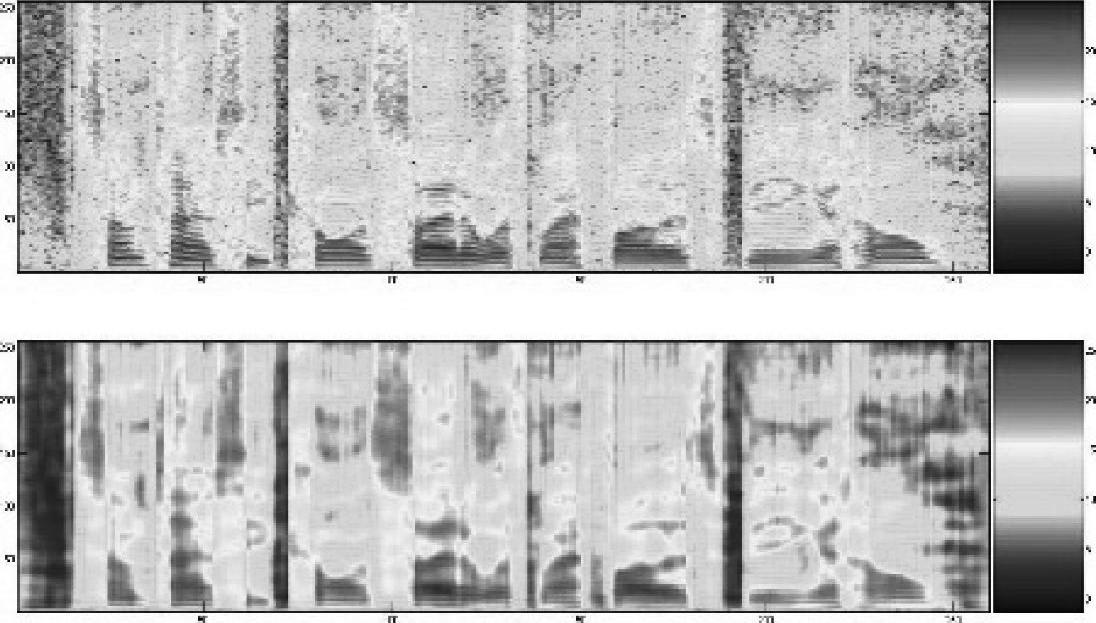
图4.8
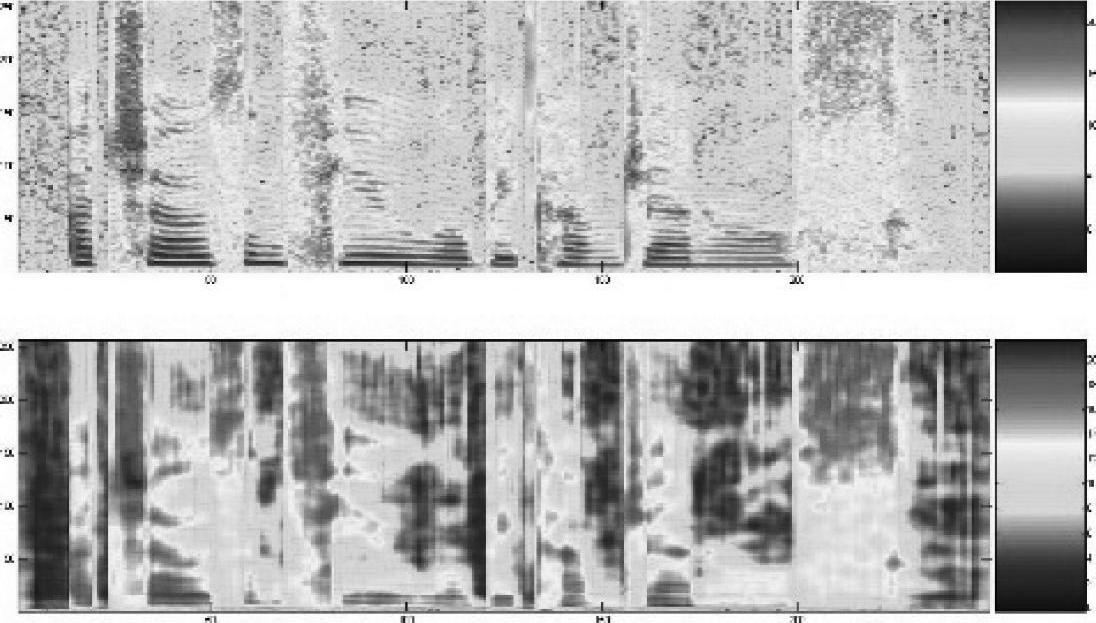
图4.9
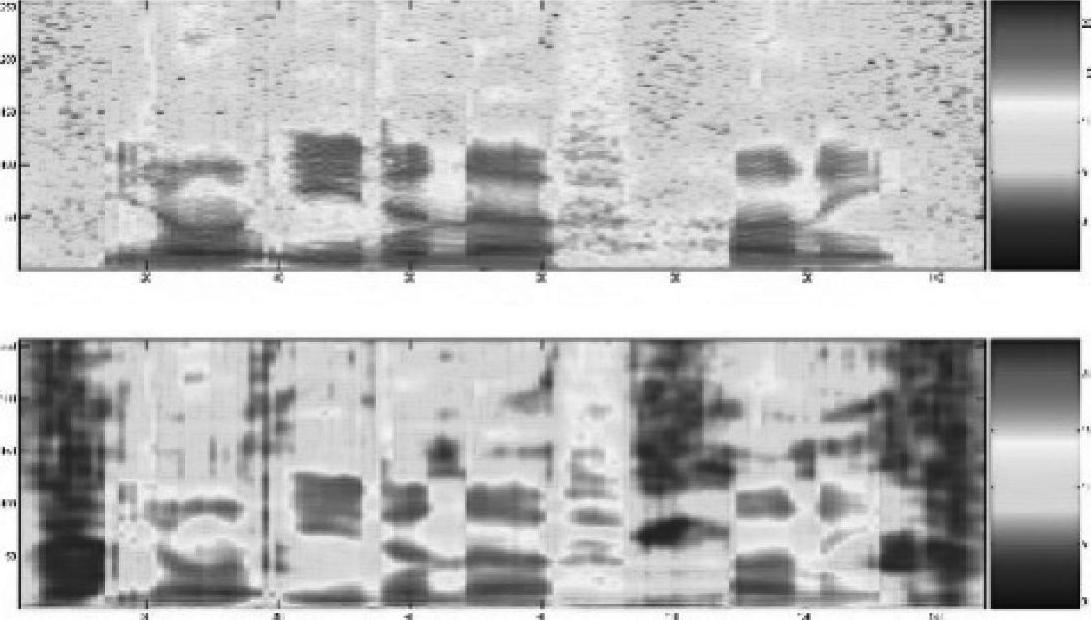
图4.10
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。