



1.声音压缩的依据是什么?MPEG-1音频编码利用了听觉系统的什么特性?
解:声音压缩的依据是心理声学模型以及声音样本数据的相关性。心理声学模型是对人类听觉心理声学测量所做大量测试的统计结果,主要反映听觉阈值特性和掩蔽效应。
MPEG-1音频编码利用了听觉系统的阈值特性和掩蔽效应。
听觉阈值特性主要反映了只有声压高于阈值的声音才可为听觉感受,而阈值又随音频频率改变,通常1~5kHz范围内阈值最低,即听觉对此频率范围的声音最敏感。依据听觉的阈值特性,声音信号中声压低于阈值的音频分量可舍弃,低于阈值的编码损失也可不必理会。
掩蔽效应指强音能抑制其邻近弱音的听觉特性。掩蔽效应表明,声音信号中,可被掩蔽的信号可以不传,也不用担心那些可被掩蔽的量化噪声。
心理声学模型对音频压缩编码的意义在于:听觉系统像一组多信道实时分析器,各自具有不同的带宽和敏感度。不能被人感知的声音信号不必传输,压缩音频带来的损伤,只要不会被感受,也不必去担心。
2.MPEG-1音频比特流数据帧中的比例因子起什么作用?
解:比例因子的作用是充分利用量化器的动态范围,通过比特分配和比例因子相配合,可以相对降低量化噪声电平。
3.什么叫做5.1声道环绕立体声?
解:杜比AC-3环绕声系统最多可有6个完全独立的声道:左声道(L)、右声道(R)、中置声道(C)、左环绕声道(LS)、右环绕声道(RS),以及一个低频音效增强(Low Fre-quency Enhancement,LFE)声道。其中前5个声道的频带范围为20Hz~20kHz,称为主声道;而LFE信道的频带限于20~120Hz,所以将此超低音声道称为“0.1”声道,加上前面5个声道,就构成杜比数字(AC-3)的5.1声道。
4.简述杜比AC-3的音频编码原理,并画出编码器原理框图。
解:杜比AC-3编码器原理框图如图5-22所示。
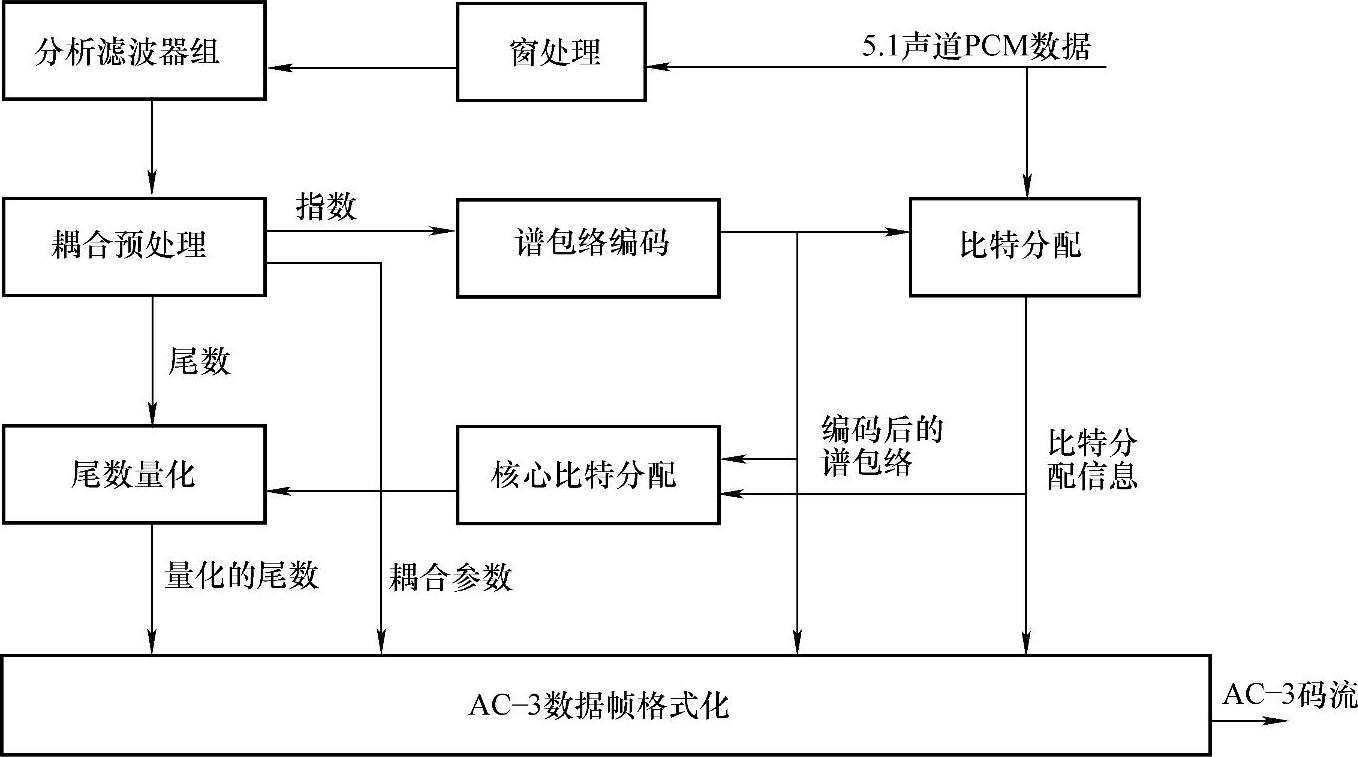
图5-22 AC-3编码器原理框图
AC-3编码器接收声音PCM数据,输出的是压缩后的码流。AC-3算法通过对声音信号频域表示的粗量化,可以达到很高的编码增益。首先把时间域内的PCM数据值变换为频域内成块的一系列变换系数。每个块有512个数据值,其中256个数据值在连续的两块中是重叠的,重叠的块被一个时间窗相乘,以提高频率选择性,然后被变换到频域内。由于前后两块重叠,每一个输入数据值出现在连续两个变换块内,因此,变换后的变换系数可以去掉一半而变成每个块包含256个变换系数,每个变换系数以二进制指数形式表示,即一个二进制指数和一个尾数。指数集反映了信号的频谱包络,对其进行编码后,可以粗略地代表信号的频谱。同时,用此频谱包络决定分配给每个尾数多少比特数。如果最终输出码流的数码率很高,而导致AC-3编码器溢出,此时要采用高频系数耦合技术,以进一步减少数码率。此后把6块(1536个声音数据值)频谱包络、粗量化的尾数以及相应的参数组成AC-3数据帧格式。
5.怎样理解AC-3的音频编码中的“指数”、“尾数”、“指数策略”?
解:从变换得到的频域变换系数被转换成浮点数,所有变换系数的值都定标为小于1.0。例如,对于16bit精度的二进制数0.0000000010101100,其前导“0”的个数为8,就成了原始指数;该数的小数点后移8位,即10101100,成了被粗量化的归一化尾数。分析滤波器输出的是指数和被粗量化的尾数,两者被编码后都进入码流。指数值的允许范围从0(对应于系数的最大值,没有前导“0”)到24,产生的动态范围接近144dB。系数的指数凡大于24的,都固定为24,这时对应的尾数允许有前导“0”。
由于每个变换系数都有一个指数,设法减小指数编码所需的比特数是值得重视的。减小指数的数码率有两种方法。第一种方法是AC-3指数的发送采用差分编码。每个音频块的第一个指数总是用4bit的绝对值,范围为0~15。这个值指明第一个(直流项)变换系数的前导“0”的个数。后续的(频率升高方向)指数的发送采用差分值。第二种方法是尽量在一个帧内的6个音频块共用一个指数集。这在各个块的指数集相差不大时可以采用。这样,只在第1块传送该指数集,后面的第2~6块共享第1块的指数集,使得指数集编码的数码率减小为原来的1/6。
AC-3将上述两种方法结合在一起,并且将差分指数在音频块中联合成组。联合方式有三种:4个差分指数联合成一组,称为D45模式;两个差分指数联合成一组,称为D25模式;单个差分指数为一组,称为D15模式。这三种模式统称为AC-3的指数策略。
这三种指数编码策略在指数所需的数码率和频率分辨率之间提供了一种折中。D15模式提供最精细的频率分辨率,D45模式所需的数据量最少。某个声道在音频块的差分指数组的组数取决于指数策略和这个声道的频带宽度信息。在各个组内的指数数目仅仅取决于指数策略。
由上所述,对指数编码的结果就是根据频率分辨率的需要选择一种频谱包络。其中D15模式为高分辨率的频谱包络,D45模式为低分辨率的频谱包络。
6.数字电视信源编码遵循什么标准?
解:在数字电视的视频压缩编码方面,各国基本上都采用了MPEG-2标准的第2部分(ISO/IEC 13818-2)。由于近年来视频压缩技术的新发展,压缩效率更高的MPEG-4以及MPEG-4 AVC/H.264标准和产品推出,使一个HDTV节目的数码率从MPEG-2的15Mbit/s下降到6~7Mbit/s,为此,欧洲广播联盟正考虑采用H.264标准实施HDTV广播。美国Di-recTV的卫星直播数字电视业务计划采用H.264编码标准。
在数字电视的伴音信号压缩编码方面,国际上存在的三大数字电视标准体系则采用了不同的音频压缩方式。美国开展地面数字电视广播时,以HDTV视频业务为主,图像质量的提高,需要有相应的高质量声音与之相配,所以美国高级电视制式委员会(Advanced Tele-vision System Committee,ATSC)采纳了5.1声道的环绕声压缩Dolby AC-3作为音频压缩标准。日本地面广播也以HDTV为主要的播出业务,音频方面则采用了MPEG-2 AAC标准,以适应高质量电视广播提出的音频压缩新标准,支持多声道的环绕声。欧洲在早期以SDTV为主开展数字电视广播,对音频质量没提出更高的要求,所以选择了早期成熟的MPEG-1标准的第3部分(ISO/IEC 11172-3)中的层2(Layer 2)算法。
压缩编码后的音视频码流复用均遵循MPEG-2标准的第1部分(ISO/IEC 13818-1)复用在同一传输流(TS)内。ISO/IEC 13818-1是MPEG-2的系统层标准,规范如何将音视频数据流、数据、管理和同步等信息打包传送。
7.我国数字电视信源编码采用什么标准?
解:目前,不同国家或地区数字电视标准的差别主要是传输标准不同,特别是地面传输标准差异较大,而信源编码标准虽然在具体规定上不尽相同,但视频编码绝大多数都遵循MPEG-2标准的第2部分(ISO/IEC 13818-2),音频编码采用MPEG-1标准的第3部分(ISO/IEC 11172-3)中的层2,或杜比AC-3标准(ATSC中的A/52),或MPEG-2的AAC(ISO/IEC 13818-7)。MPEG-2标准的第3部分(ISO/IEC 13818-3)兼容MPEG-1的第3部分(ISO/IEC11172-3),又扩展了多声道编码,我国国家标准GB/T 17975.3—2002《信息技术 运动图像及其伴音信号的通用编码第3部分:音频》与之兼容。编码后的音视频流及其他数据流复用则都执行MPEG-2标准的第1部分(ISO/IEC 13818-1,ITU-T的H.222.0共用,MPEG-4、H.264/AVC和AVS等也采用)。
MPEG-2标准的先进性是相对的。在数字音视频编码技术需求的推动下,ISO/IEC和ITU-T于2001年成立了联合视频工作组(JVT),2002年12月形成了新标准的最终草案。该标准在ITU-T标准系列中称为H.264,在ISO/IEC标准系列中为MPEG-4的第10部分(ISO/IEC 14496-10),并称之为先进视频编码标准(AVC)。JVT的这个视频编码标准通常记为H.264/AVC。
我国目前正在运行的中央和各地方卫视SDTV节目的视频编码基本上都采用MPEG-2标准,与其主类主级(MP@ML)对应。我国国家标准GB/T 17975.2—2000《信息技术 运动图像及其伴音信号的通用编码第2部分:视频》与之等同。
我国目前试播的HDTV卫视节目的视频编码也采用MPEG-2标准,与其主类高级(MP@HL)对应。一个卫星转发器或一个有线电视频点最大传输码率为38Mbit/s,其净数据率可传1路HDTV加3路SDTV,或两路HDTV节目。
我国数字电视声音信号信源编码国家标准尚未确定。目前,中央电视台的SDTV节目用MPEG-1第3部分的层2音频编码标准播出,HDTV用Dolby AC-3音频编码标准试播。我国国家标准GB/T 17191.3—1997《信息技术 具有1.5Mbit/s数据传输率的数字存储媒体运动图像及其伴音的编码第3部分:音频》与ISO/IEC 11172-3即MPEG-1第3部分等同。我国信息产业部2007年初发布并实施电子行业标准SJ/T 11368—2006《多声道数字音频编解码技术规范》,该规范的文本指出适用范围包括数字电视伴音。
我国数字电视系统中的各种编码码流、系统管理和控制信息等则都按MPEG-2标准的第1部分(ISO/IEC 13818-1)复用在一起,我国国家标准GB/T 17975.1—2000《信息技术 运动图像及其伴音信息的通用编码第1部分:系统》与之等效。
8.国际上主要有哪些数字音视频编码标准?
解:在国际电信联盟(International Telecommunication Union,ITU)、国际标准化组织(International Standardization Organization,ISO)和国际电工委员会(International Electrotech-nic Committee,IEC)等几大标准化组织的推动下,先后形成了针对不同应用目的的多个系列的音视频压缩编码国际标准,其中最具代表性的两大系列是:ITU-T推出的H.26x系列视频编码标准,包括H.261、H.262、H.263、H.263+、H.263++和H.264,主要应用于实时视频通信领域,如会议电视、可视电话等;ISO/IEC推出的MPEG系列音视频压缩编码标准,包括MPEG-1、MPEG-2和MPEG-4等,主要应用于音视频存储(如VCD、DVD)、数字音视频广播、因特网或无线网上的流媒体等。这些标准已在数字电视、多媒体通信领域得到广泛应用,极大地推动了数字电视技术及多媒体技术的发展。
AVS是我国具备自主知识产权的信源编码标准,是《信息技术——先进音视频编码》系列标准的简称。AVS包括系统、视频、音频、数字版权管理等9个部分。其中,AVS第2部分于2006年3月1日被国家标准化管理委员会正式批准为国家标准,标准号为GB/T20090.2—2006。
9.压缩数字视频数据量的基本原理是什么?
解:数据压缩的理论基础是信息论。从信息论的角度来看,压缩就是去掉数据中的冗余,即保留不确定的信息,去掉确定的信息(可推知的),也就是用一种更接近信息本质的描述来代替原有冗余的描述。
视频信号压缩主要依据视觉特性、图像本身的特点及信号的统计规律。在扫描标准和原始图像数据精度等参数确定的情况下,一帧图像的有效像素数越多,需要处理的数据量就越大,在有限带宽信道中传输需要的压缩比就越高。
数字电视仍基于三基色原理工作,各像素对应红(R)、绿(G)、蓝(B)三个基色信号。由于视觉对彩色细节不如对亮度细节敏感,为减少色信号数据量,在水平和垂直方向,色信号取样的数据量只能是亮度信号的一半,这就是4∶2∶0信号格式。这样,利用视觉特性,把需处理的两个色信号分量数据量均减少到亮度信号的1/4。
在绝大多数图像或一幅图像的绝大部分中,一小块内通常没有或很少有变化,即这些像素的数据彼此相同或变化很平稳,这反映了图像在空间域存在冗余信息。图像的这一特点,在频率域表现为直流和低频成分较大,高频成分很少或高频成分值很小,而视觉对高频成分又不敏感,将图像和视觉这两种特性结合在一起,可有效地去除图像空间冗余度。
实际上,电视视频图像序列相邻帧通常很相似,或当前编码帧中的一块图像与已编码帧中的某块图像很相似。由于各帧间隔一个帧周期,所以这种相似表明视频序列存在时间冗余度。消除时间冗余度,可极大地压缩数据量。
目前数字视频编码技术一直在发展,各个新的编码标准采用了更加高效、更加复杂的技术,以此来提高压缩效率,使得能通过更窄带宽的信道传送视频信息,但基本原理都是充分利用视觉特性,最大限度地去除视频图像序列的空间、时间冗余度和编码数据流的统计冗余度。
10.MPEG-1/2视频编码标准中定义了哪几种编码图像类型?哪种类型图像的压缩比最高?哪种类型图像的压缩比最低?
解:MPEG-1/2视频编码标准中,将编码图像分为三种类型,分别称为I帧(Intra-co-ded Frame,帧内编码帧)、P帧(Predictive-coded Frame,前向预测编码帧)和B帧(Bi-di-rectional Predictive-coded Frame,双向预测编码帧)。
B帧图像既用源视频序列中位于前面且已编码的I帧或P帧作为参考帧,进行前向运动补偿预测,又用位于后面且已编码的I帧或P帧作为参考帧,进行后向运动补偿预测。即B帧可采用帧内编码,前向预测编码、后向预测编码,或双向预测编码4种技术,其压缩比最高。
I帧图像采用帧内DCT编码,只利用了本帧图像内的空间相关性,而没有利用时间相关性,所以I帧图像的压缩比最低。
11.帧重排的基本原理是什么?(https://www.xing528.com)
解:在MPEG编码中,为了充分利用帧间相关性,有效提高编码压缩比,定义了I帧、P帧和B帧三种类型的编码帧。由于B帧是双向预测编码帧,所以需等前、后的参考帧编码后才能编码。而MPEG视频码流的传输要有利于解码器的解码,为此,MPEG视频编码器输出码流的帧顺序,即解码器输入码流的帧顺序,应不同于输入到编码器的源图像序列的帧顺序(也就是自然次序),必须进行重新排序;同理,解码器解码这种码流,送去显示的帧顺序也必须重新排列,使之恢复源图像帧顺序,这种过程称为帧重排。例如,当图像帧显示的顺序是I1 B2 B3 P4 B5 B6 P7 B8 B9 P10…时,视频码流中帧的传输顺序则是I1 P4 B2 B3 P7 B5 B6 P10 B8 B9…。这样,在编码时利用帧重排过程将待预测编码B帧所用到后面的I帧或P帧“挪到”该B帧的前面去,或者说待预测编码的B帧被“挪到”相应I帧或P帧的后面去,而后再进行预测与运动补偿。
12.请解释MPEG-2视频编码中的“类”和“级”的概念。
解:MPEG-2标准适用范围广,具有较强的通用性,也就是说充分考虑到各种应用的不同要求,制定了一种统一的语法。在具体实现时,如果要求编/解码器满足压缩算法规定的全部语法,那么编/解码器就会很复杂,这会增加实现成本,甚至很难实现。而事实上,一个编/解码器也没必要实现MPEG-2的全部功能。因此,要求MPEG-2具有针对不同应用场合的特殊性。为了解决通用性和特殊性的矛盾,支持灵活的性能价格比,MPEG-2在单一语法的基础上,针对不同的应用,规定了不同的压缩处理方法,即不同的语法子集。这样的语法子集称为“类”(Profile)。MPEG-2定义了6种类:简单(Simple)类、主(Main)类、4∶2∶2类、信噪比可分级(SNR Scalable)类、空间可分级(Spatial Scalable)类和高级(High)类。然而,在同一语法子集中(即同一“类”中)需要处理的输入图像格式(如分辨率)可能有很大的差别,于是MPEG-2又提出了“级”(Level)的概念。按编码图像的分辨率分成4个“级”,即高级(High)、1440-高级(High-1440)、主级(Main)、低级(Low)。
同一“类”中的各个“级”遵循该类的语法,只是参数不同而已。因此,可以这么理解:“类”规定了可以使用哪些语法元素,以及如何使用这些语法元素,而“级”则规定了这些语法元素的取值范围。“级”与“类”的组合构成了MPEG-2视频编码标准在某种特定应用下的子集,对某一输入格式的图像,采用特定集合的压缩编码工具,产生规定速率范围内的编码码流。
13.MPEG-2与MPEG-1相比,在哪些方面作了扩展和改进?
解:与MPEG-1相比,MPEG-2对MPEG-1作了重要的改进和扩展,主要表现在以下几个方面。
(1)MPEG-2有“按帧编码”和“按场编码”两种模式
在MPEG-1中,没有电视帧的概念,只支持逐行扫描,不支持隔行扫描。在MPEG-2中,允许逐行扫描和隔行扫描两种扫描方式,针对隔行扫描的常规电视图像专门设置了“按帧编码”和“按场编码”两种模式。相应地,运动补偿预测和DCT算法也有扩充,可进行“基于帧”或“基于场”的运动补偿预测和DCT编码,从而显著提高压缩编码效率。
(2)MPEG-2增加了可分级编码模式
可分级视频编码(Scalable Video Coding)是一种能够适应网络带宽动态变化的信源编码解决方案。视频编码的可分级性是指视频码流数码率的可调整性,即视频数据只压缩一次,却能以多种不同的时间分辨率(帧频)、空间分辨率(清晰度)或视频质量进行解码,从而可支持多种类型用户的各种不同的应用要求。
(3)MPEG-2定义了“类”与“级”的概念
MPEG-2标准适用范围广,具有较强的通用性,也就是说充分考虑到各种应用的不同要求,制定了一种统一的语法。在具体实现时,如果要求编/解码器满足压缩算法规定的全部语法,那么编/解码器就会很复杂,这会增加实现成本,甚至很难实现。而事实上,一个编/解码器也没必要实现MPEG-2的全部功能。因此,要求MPEG-2具有针对不同应用场合的特殊性。为了解决通用性和特殊性的矛盾,支持灵活的性能价格比,MPEG-2在单一语法的基础上,针对不同的应用,规定了不同的压缩处理方法,即不同的语法子集。这样的语法子集称为“类”(Profile)。MPEG-2定义了6种类:简单(Simple)类、主(Main)类、4∶2∶2类、信噪比可分级(SNR Scalable)类、空间可分级(Spatial Scalable)类和高级(High)类。然而,在同一语法子集中(即同一“类”中)需要处理的输入图像格式(如分辨率)可能有很大的差别,于是MPEG-2又提出了“级”(Level)的概念。按编码图像的分辨率分成4个“级”,即高级(High)、1440-高级(High-1440)、主级(Main)、低级(Low)。
14.MPEG-2中的MP@ML图像格式是DVD视频信号的标准,若不采取压缩技术,一张容量为4.7GB的单面光盘,存储的图像信息能够连续播放多少时间(忽略伴音信号占有的容量)?
解:MPEG-2中的MP@ML图像格式为720×576×25,设8bit量化,则每秒数据量为
(720×576×8+360×576×8+360×576×8)×25bit=165.888Mbit=0.0193736GB
一张容量为4.7GB的单面光盘,存储的图像信息能够连续播放的时间为
4.7/0.0193736s=243s
15.请画出MPEG-4基于内容的视频编/解码器结构框图。
解:MPEG-4基于内容的视频编/解码器结构框图如图5-23所示。首先从原始序列图像中分割出VO,然后由编码控制单元为不同VO的形状、运动、纹理信息分配数码率,对各个VO分别独立编码,最后将各个VO的码流复合成一个输出码流。其中,在编码控制和复用单元可以加入用户的交互控制或由智能化的算法进行控制,用不同的参数、不同的编码方法来选择不同的VO进行编码,甚至也可以选择某些VO不进行编码。这个编码器最重要的特征是基于VO的本征表示来定义一个景物。接收端经解复用,将各个VO分别解码,然后将解码后的VO合成场景输出。解复用和VO合成时也可以加入用户交互控制。
16.H.264标准有哪些主要特性?
解:H.264标准的主要特性如下:
1)H.264视频编码结构从功能和算法上分为两层设计,即视频编码层(VCL)和网络抽象层(NAL)。VCL负责高效的视频编码压缩,是视频编码的核心,其中包含许多实现差错恢复的工具,并采用了大量先进的视频编码技术以提高编码效率。NAL将经过VCL编码的视频流进行进一步分割和打包封装,提供对不同网络性能匹配的自适应处理能力,负责网络的适配,提供“网络友好性”。
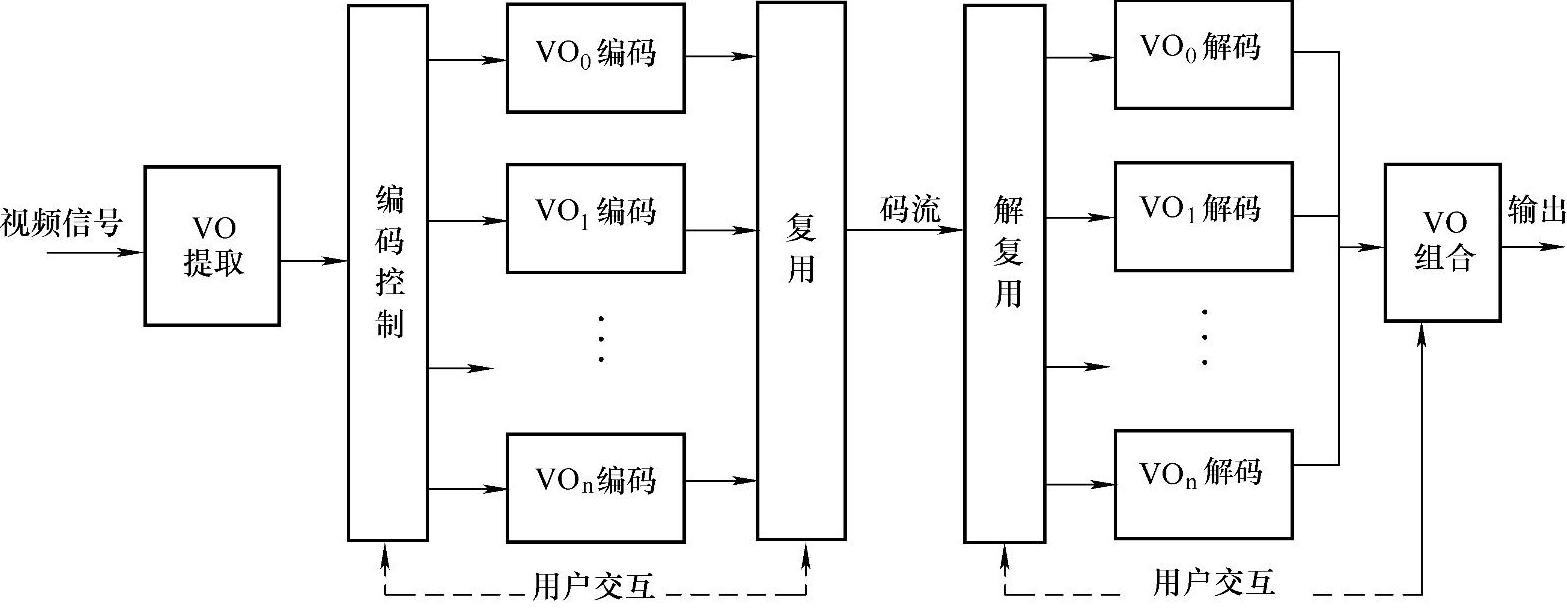
图5-23 MPEG-4基于内容的视频编/解码器结构框图
2)采用基于空间域的帧内预测编码,将相邻块边沿的已编码重建的像素值直接进行外推,作为对当前块帧内编码图像的预测值,更有效地去除相邻块之间的相关性,极大地提高了帧内编码的效率。
3)支持可变的块尺寸及更小尺寸块的运动补偿预测。在H.264/AVC中,可灵活选择块大小进行运动补偿,支持16×16、16×8、8×16、8×8、8×4、4×8和4×4等7种宏块划分模式。
4)支持高精度的亚像素运动估计。在H.264中,对于亮度分量,采用1/4像素精度的运动估计;对于色度分量,采用1/8像素精度的运动估计。
5)采用多参考帧的运动补偿预测。在MPEG-2、H.263等标准中,P帧只采用前一帧进行预测,B帧只采用相邻的两帧进行预测。而H.264采用更为有效的多帧运动估计,即在编码器的缓存中存有多个刚刚编码好的参考帧(最多5帧),编码器从其中选择一个预测效果最好的参考帧,并指出是哪一帧被用于预测的,这样就可获得比只用上一个刚刚编码好的帧作为预测帧更好的编码效果。多参考帧预测对周期性运动和背景切换来说能够提供更好的预测效果,而且有助于比特流的恢复。
6)加权预测。H.264允许对P或B条带中宏块运动补偿预测像素值进行加权修改,在运动补偿预测前,使用加权因子来缩放每个预测样点值。
7)H.264引入了去块效应环路滤波器,可有效消除块效应。
8)整数变换与量化。H.264标准在变换编码上做了较大的改进,它摒弃了在多个标准中普遍采用的8×8 DCT,而采用一种4×4整数变换来对帧内预测和帧间预测的差值数据进行变换编码。选择4×4整数编码,一方面是为了配合帧间预测中所采用的变尺寸块匹配算法,以及帧内预测编码算法中的最小预测单元的大小;另一方面,这种变换是基于整数运算的变换,其算法中只需要加法和移位运算,因此运算速度快,并且在反变换过程中不会出现失配问题。同时,H.264标准根据这种整数变换运算上的特点,将更为精细的量化过程与变换过程相结合,可以进一步减少运算复杂度,从而提高该编码环节的整体性能。
9)H.264提供了两种改进的熵编码方案:基于上下文的自适应变长编码(CAVLC)和基于上下文的自适应二进制算术编码(CABAC)。
10)在H.264标准中,根据编码方式和作用的不同,定义了以下的片(Slice)类型:
●I片:I片内的所有宏块均使用帧内编码模式。
●P片:除了可以采用帧内编码模式外,P片中的宏块还可以采用帧间预测编码模式,但只能采用一个前向运动矢量。
●B片:除了可以采用P片的所有编码模式外,B片的宏块还可以采用具有两个运动矢量的双向预测编码模式。
●SP片:切换的P片。目的是在不引起类似插入I片所带来的数码率开销的情况下,实现码流间的切换。SP片采用了运动补偿技术,适用于同一内容不同质量的视频码流间的切换。
●SI片:切换的I片。SI片采用了帧内预测技术代替SP片的运动补偿技术,用于不同内容的视频码流间的切换。
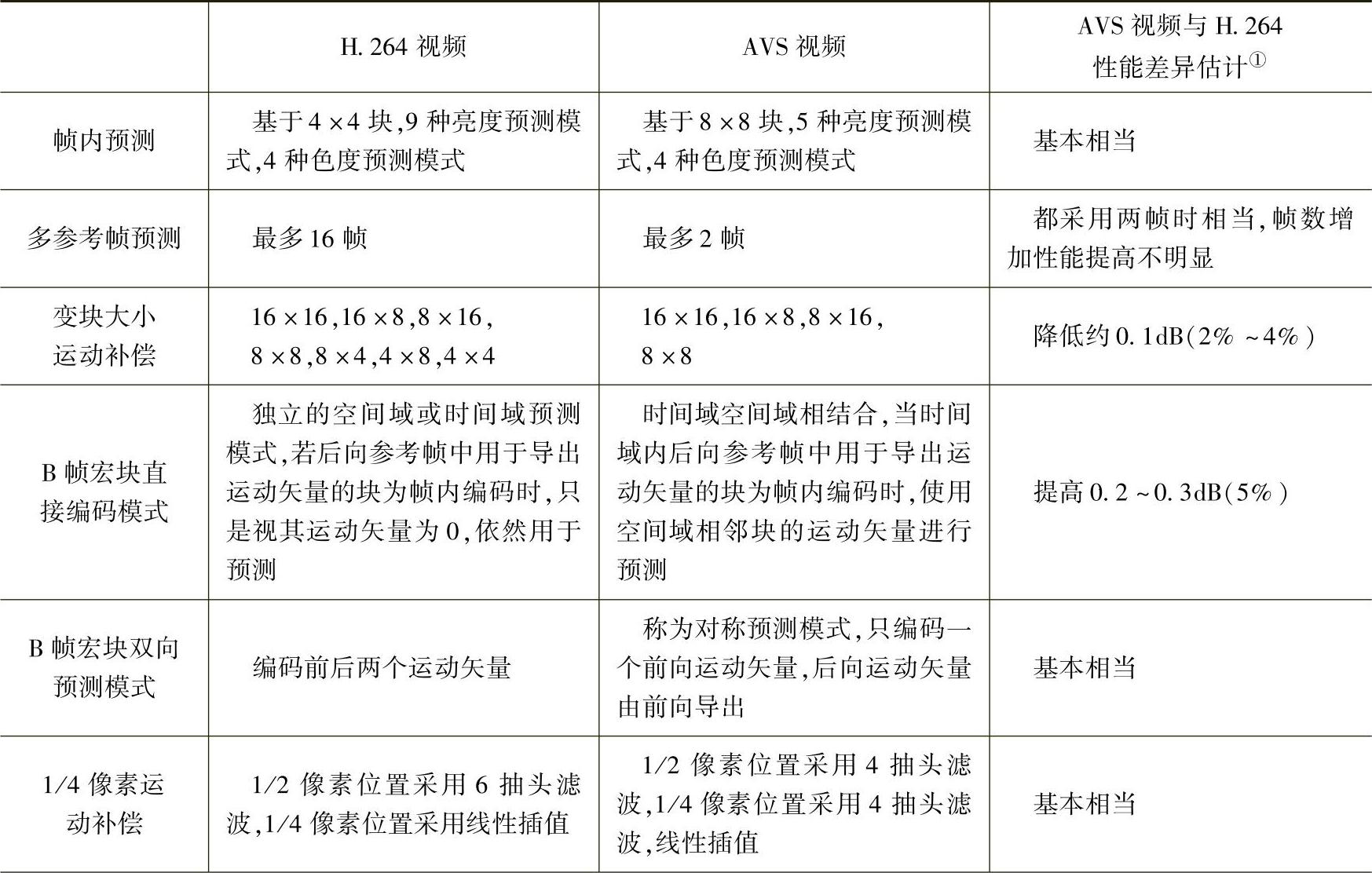
17.AVS视频编码标准与H.264标准相比,其性能怎样?有何优势?
解:AVS视频与H.264都采用了混合编码框架。AVS的主要创新在于提出了一批具体的优化技术,在较低的复杂度下(大致估算,AVS解码复杂度相当于H.264的30%,AVS编码复杂度相当于H.264的70%)实现了与国际标准相当的技术性能,但并未使用国际标准背后的大量复杂的专利。AVS视频当中具有特征性的核心技术包括:8×8整数变换、量化、帧内预测、1/4精度像素插值、特殊的帧间预测运动补偿、二维熵编码、去块效应环内滤波等。AVS与H.264使用的技术对比和性能差异如表5-5所示。
表5-5 AVS与H.264使用的技术对比和性能差异估计
(续)
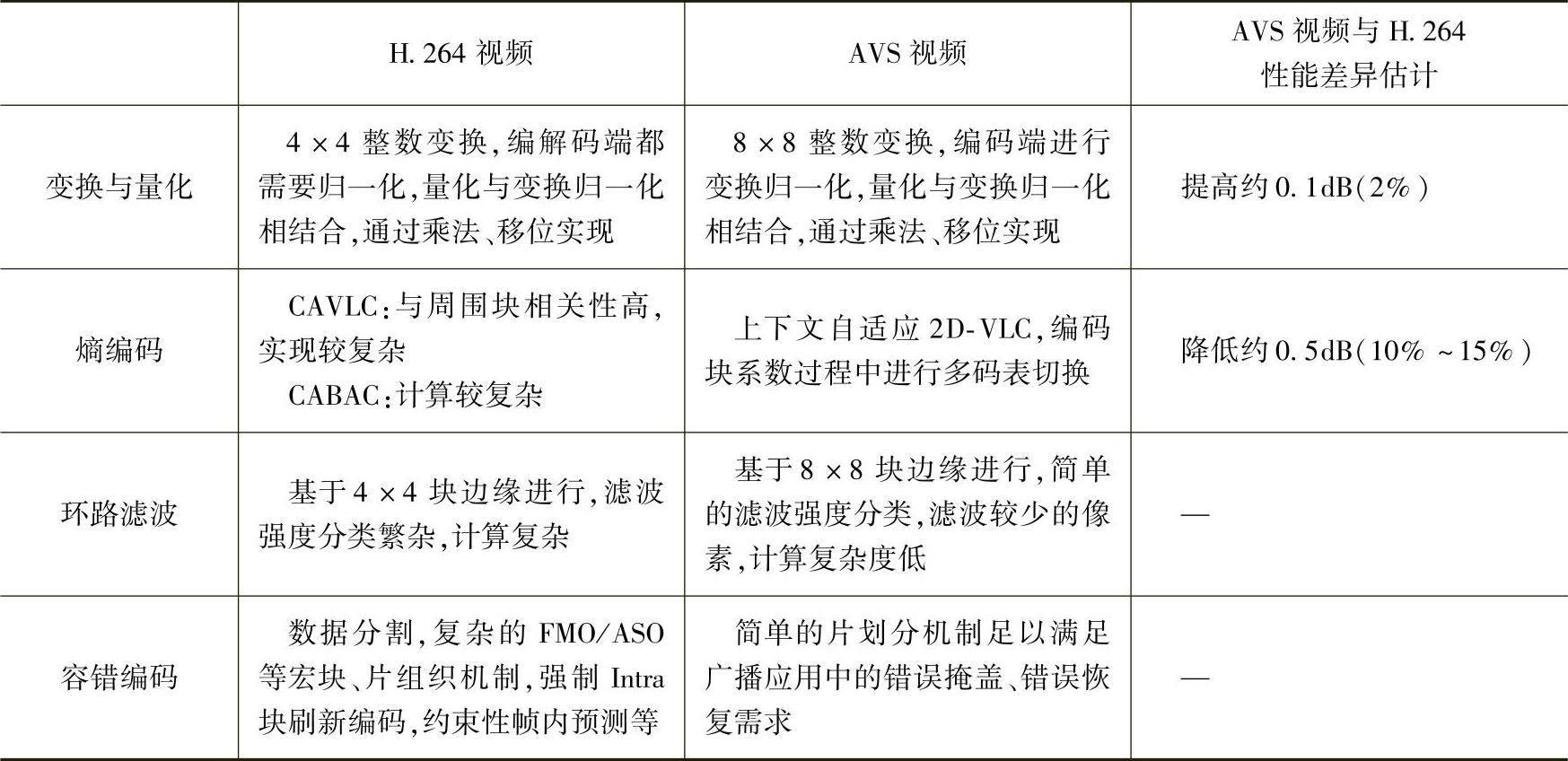
① 采用信噪比dB估算,括号内的百分比为数码率差异。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。