



为了适应网络带宽的动态变化和终端的多样性,MPEG-2标准首次引入了可分级视频编码(Scalable Video Coding,SVC)的思想。可分级视频编码也叫可分级视频编码或可扩展视频编码。
可分级视频编码(SVC)的基本思想是将视频信号编码成一个可以单独解码的基本层(Base Layer,BL)码流和一个(或多个)增强层(Enhancement Layer,EL)码流。其中基本层码流包含视频信号中最基本的也是最重要的信息,接收端只需接收到基本层码流就可以重建基本质量的图像。增强层码流包含视频信号的细节信息,接收端可将增强层码流和基本层码流一起解码,以重建更高质量的图像。基本层码流可以单独解码,而增强层码流不能单独解码,必须在基本层码流正确解码的基础之上进行解码。传输时可视基本层和增强层重要性的不同,对其赋予不同的传输优先级和误码保护机制。解码器可在多个图像质量级别上进行解码,用户可根据需要进行解码,即使增强层的数据丢失或者被抛弃,也能够使恢复的图像质量达到一个可以接受的水平。所以,基本层码流适应最低的网络带宽,而增强层码流用来覆盖动态变化范围的网络带宽。在信道传输方面,可以将不同层的数据以多个逻辑信道或物理信道进行独立传输,接收端可以根据具体信道条件、接收器性能等诸多因素,在确保基本层码流的接收后,选择性地接收其他增强层码流,从而达到充分利用信道资源的目的。当视频码流在网络中传输时,如果网络拥挤,可以只传输和解码基本层或部分增强层码流,接收端仍然可以保证可接受的视频质量。所以,编码端只做一次高质量编码,不管信道和接收条件如何,在实际传输和解码时都可根据网络的可用带宽资源和拥堵情况自动调整数码率。解码端可以根据终端处理能力及显示分辨能力,对编码比特流的部分或全部码流进行解码,得到不同时间/空间分辨率或不同质量等级的视频信号,以适应网络的带宽及终端能力。可分级编解码器的一般结构框图如图5-13所示。
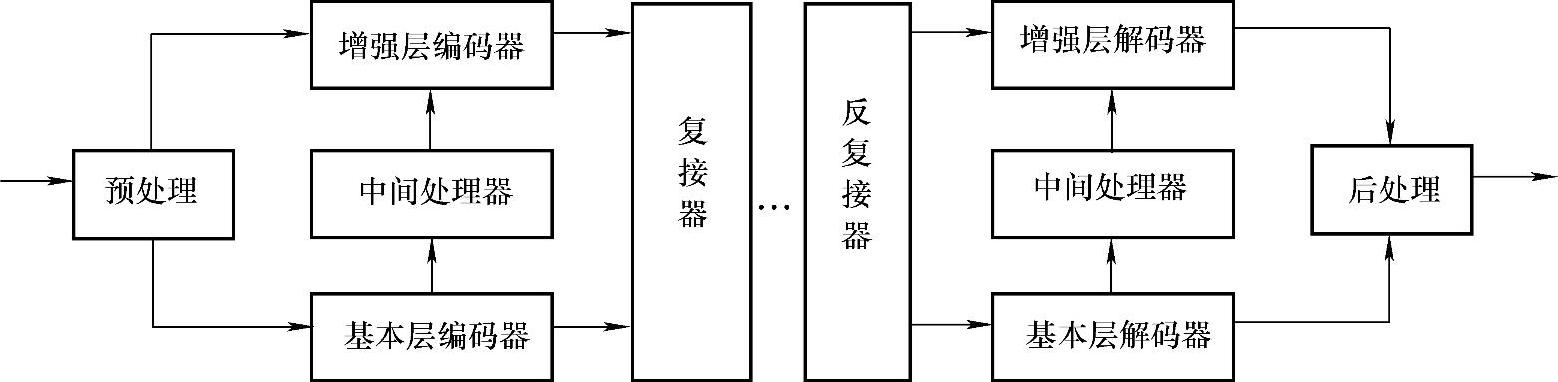
图5-13 可分级编解码器的一般结构框图
可分级性编码有三种基本类型:时间域可分级性(Temporal Scalability)、空间域可分级性(Spatial Scalability)和信噪比可分级性(Signal-Noise Ratio Scalability)。其中信噪比可分级性又称为质量可分级性,因为视频质量通常用峰值信噪比(Peak Signal-Noise Ratio,PSNR)来衡量。这三种可分级性分别对应了视频的帧频、图像分辨率、PSNR等几个基本参数,它们都能在基本层外提供一个或几个增强层,实现初步的可分级性。时间域可分级意味着基本层的码流具有较低的帧频,而增强层码流具有提高帧频的作用。空间域可分级意味着基本层码流是原始视频信号的低分辨率部分,增强层码流则包含了提高分辨率所需要的附加信息。信噪比可分级性中的基本层码流是利用较粗糙的量化器得到的,增强层码流则包含了提高量化精度后的额外信息。
时间域可分级性、信噪比可分级性和空间域可分级性相结合可组合成多层混合可分级编码。
1.信噪比可分级性视频编码
基本层仍是典型的基于块的编码方式,而增强层是将原始图像和基本层的解码重建图像之间的误差图像也进行编码,即通过反量化重建基本层DCT系数,从原DCT系数中减去基本层的DCT系数得到残差,用更小量化步长对残差进行量化,最后用VLC编码量化比特。相应的解码端基本层和增强层相结合可提供主观质量较好的重建图像。增强层图像由基本层图像预测得到。
信噪比可分级性主要利用了视频的峰值信噪比(PSNR)这个参数提供可分级性。信噪比可分级性编码以相同的帧频和空间分辨率把原始视频数据压缩成一个基本层码流和多个增强层码流,各层编码时采用不同的量化精度,基本上是由粗到细。通过解码基本层码流,用户可得到一个低质量的图像。通过解码基本层码流和不同的增强层码流,图像质量不断提高,如图5-14所示。

图5-14 信噪比可分级性视频编解码示意图
视频的每帧图像在编码过程中都要经过在DCT变换后进行量化这一步骤,量化是一种有损压缩方法,通过改变量化步长,可以得到不同质量和压缩比的图像。若量化步长较小,则视频图像丢失的信息比较少,视频质量的损失就比较少,但压缩率就会偏低;若量化步长较大,则视频图像丢失的信息比较多,视频压缩率较高,但图像质量损失比较大。信噪比可分级性就是利用视频编码过程中的量化这一步骤实现的。
信噪比可分级性是在DCT域中进行的分级编码模式,通过不同的量化器,对DCT系数进行不同步长的量化,实现不同的图像质量。其中基本层编码采用粗量化器对DCT系数进行量化,而SNR增强层编码器则是通过将基本层中量化误差进行更为细致的量化和熵编码形成增强层码流。如果有多个增强层码流,则重复上面的过程。在解码端,系统可以通过基本层解码图像与增强层解码的量化误差图像进行叠加,以提高重建图像的质量。具有两个增强层的信噪比可分级性编码器如图5-15所示。
2.空间域可分级视频编码
空间域可分级模式是通过对不同空间分辨率的图像进行编码,形成基本层与增强层码流。当接收端接收到基本层码流,解码重建得到的是低分辨率或小尺寸的图像。若同时再解码增强层的码流,则重建得到的是较高分辨率或较大尺寸的图像,如图5-16所示。(https://www.xing528.com)
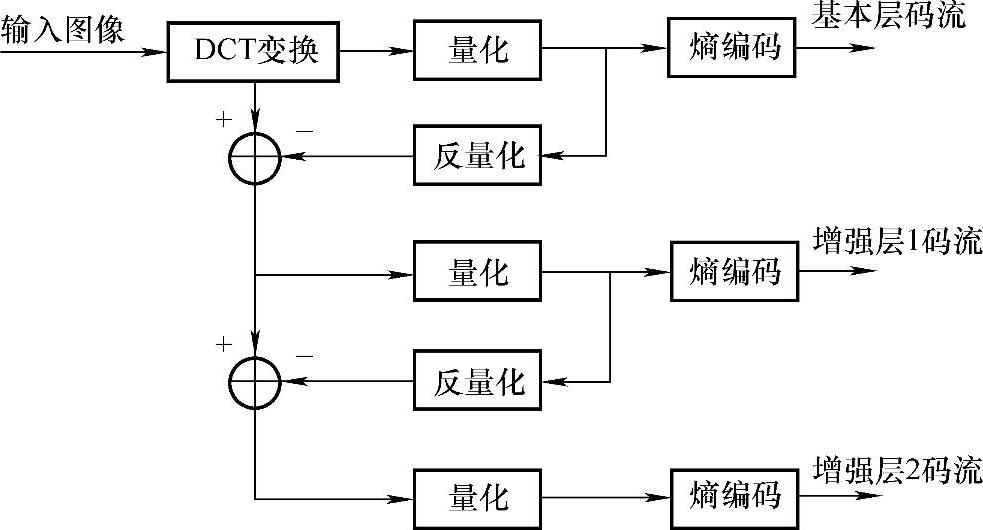
图5-15 具有两个增强层的信噪比可分级性编码器的原理图

图5-16 空间域可分级视频编解码示意图
当进行空间域可分级编码时,预处理器对输入的原始图像进行下采样得到低分辨率的基本层图像,由基本层编码器输出基本层码流。中间处理器对基本层码流进行解码,得到重建的基本层图像,并对其进行上采样插值处理后,用做对原始输入视频信号进行编码的预测参考,然后对预测误差进行编码,形成高分辨率的增强层码流。图5-17说明了空间域可分级编码的一种实现方案。
空间域可分级性主要应用于接收端设备显示屏幕分辨率不同的情况下。作为一个视频流服务器,其发送视频信息的目标可能是不同种类的设备。对每种设备都单独编码显然是非常浪费资源的,所以由视频流服务器提供统一的具有可分级性的视频码流顺理成章地成为此类问题的解决方案。
3.时间域可分级视频编码
时间域可分级编码是通过提高帧频来改善视频质量的一种编码方法。将各个码流层定义为同一视频的不同的时间分辨率下的表示,对不同的层使用不同的帧频。其基本层帧频较低,随着选用的增强层越来越多,帧频越来越高。时间域可分级编码通常是通过插入双向预测帧(B帧)来实现的。B帧是用与其在时间上相邻的前后两帧(I帧或P帧)双向预测得到,如图5-18所示。在同样的量化级数条件下,B帧具有更好的压缩性能,它使得在压缩码率增加不大的情况下,达到使帧频倍增的效果。另外,B帧本身不作为其他任何帧的预测参考图像,因此在传输中丢失或抛弃B帧,并不影响后续图像的重建质量,而仅仅降低帧频,但会影响整体视频质量,主观感觉视频流畅度较低。如果采用增强层的码流信息,在原来基本层解码图像的基础上,适当地插入B帧解码重建的图像,提高帧频,从而改善视频质量。
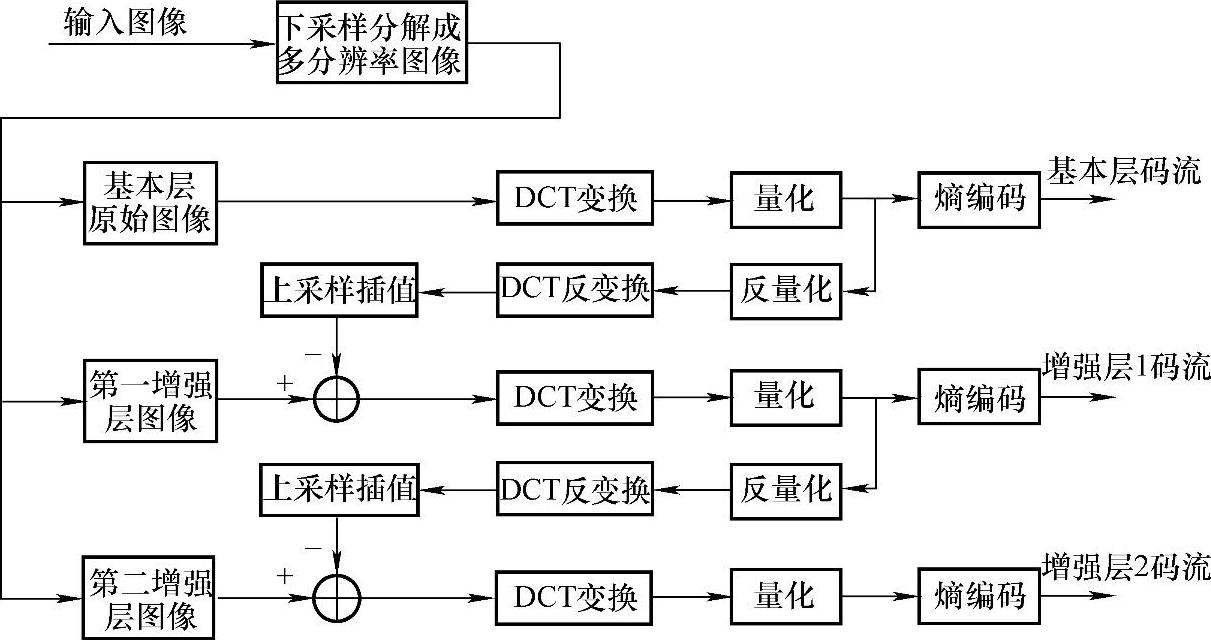
图5-17 具有两个增强层的空间域可分级编码器的原理图
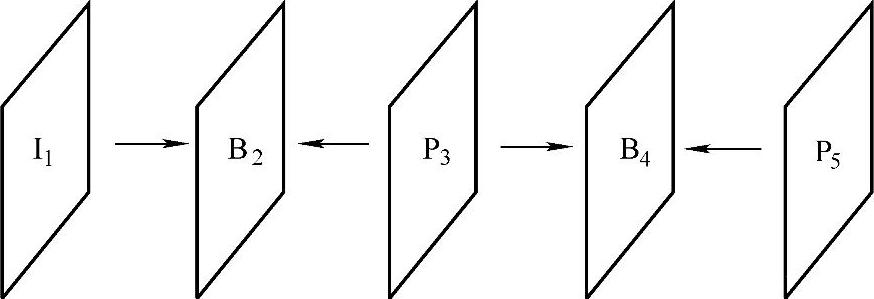
图5-18 B帧的位置
需要注意的是,B帧在码流中的位置并不是按照时间顺序排列的。例如,如果一段视频序列的显示顺序为I1,B2,P3,B4,P5,…,则在码流中传输的顺序应为I1,P3,B2,P5,B4,…,下标是视频序列按显示顺序排列的序号。原因在于B2是由I1和P3双向预测得到的,实际编码时为解码方便,先编码用于预测的I1和P3,再编码B2,即用做B帧预测的参考帧要在B帧之前编码。其中B帧的最大个数一般在视频编码标准之外规定。B帧的分辨率和其参考帧相同。B帧的引入可以使压缩性能得到改善,但是由于图像序列的显示顺序和编码传输顺序变得不一致,加大了编解码器的复杂度,引入了额外的时延。另外,由于B帧编码时需要参考前后两帧,从而需要增加存储开销。
时间域可分级编码器的结构类似于空间域可分级编码器,对原始视频序列进行时间域下采样,如跳帧方法,得到基本层要编码的图像序列;利用较低层的时间上采样图像作为较高层的预测。将空间域可分级编码框图中的空间上采样和空间下采样改为时间上采样和时间下采样,即为时间域可分级编码框图。图5-19是基于运动补偿的时间域可分级编码原理框图。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。