



1.人耳的听觉感知特性有哪些?感知音频编码的基本思想是什么?
解:人耳能听到的声音频率在20Hz~20kHz范围之内,但是其灵敏度与频率有关,也就是说人耳听到的声音的响度与声音的频率有关。当声音强度减弱到人耳刚刚可以听见时,此时的声压级称为最小可听阈值,简称为“听阈”。一般以1kHz纯音为基准进行测量,人耳刚能听到的声压级为0dB(通常大于0.3dB即有感受)。而当声音增强到使人耳感到疼痛时,这个听觉阈值称为“痛阈”。仍以1kHz纯音为基准来进行测量,使人耳感到疼痛时的声压级为140dB左右。实验表明,人耳对不同频率的声音听阈和痛阈不一样,灵敏度也不一样。人耳的痛阈受频率的影响不大,而听阈随频率变化相当剧烈。人耳对3~4kHz声音最敏感,幅度很小的声音信号都能被人耳听到。而在低频区(如小于800Hz)和高频区(如大于5kHz),人耳对声音的灵敏度要低得多。
人耳的听觉掩蔽效应是指一个较弱的声音(被掩蔽音)的听觉感受被另一个较强的声音(掩蔽音)影响的现象,主要表现为频率域掩蔽效应和时间域掩蔽效应。所谓频率域掩蔽是指掩蔽音与被掩蔽音同时作用时发生掩蔽效应,又称同时掩蔽。通常,频率域中的一个强音会掩蔽与之同时发声的频率相近的弱音,弱音的频率与强音的频率越接近,一般越容易被掩蔽。除了同时发出的声音之间有掩蔽效应之外,在时间上相邻的声音之间也有掩蔽效应。即在一个强音信号之前或之后的弱音信号,也会被掩蔽掉。这种掩蔽效应称为时间域掩蔽,也称异时掩蔽。时间域掩蔽又分为前掩蔽和后掩蔽。在时间域内,听到强音之前的短暂时间内,已存在的弱音可以被掩蔽而听不到,这种现象称为前掩蔽;当强音消失后,经过较长的持续时间,才能重新听到弱音信号,这种现象称为后掩蔽。
心理声学模型中一个基本的概念就是听觉系统中存在一个最小可听觉阈值(听阈),强度低于这个听阈的音频信号就听不到,因此就可以把这部分信号忽略掉,不对它进行编码,也不影响听觉效果。心理声学模型中的另一个概念是听觉掩蔽效应。听觉主要是基于对音频信号的短暂频谱分析,在相邻频谱中,人的听觉系统无法感受邻近频谱上一个较强信号所掩蔽的失真,即存在所谓的掩蔽效应。在理想状态下,掩蔽阈值以下的失真是听不见的。于是人们从两方面着手研究音频编码:一是如何精确地计算出掩蔽阈值(即获得“心理声学模型”);二是如何从音频信号中仅仅提取可听信息而加以处理,将人耳不能感知的声音成分去掉,只保留人耳能感知的声音成分,在量化时也不一味追求最小的量化噪声,只要量化噪声不被人耳感知即可。理想情况下,经一个音频编码器压缩后,引入的失真恰好在掩蔽阈值之下。这样,既实现了音频数据压缩的目的,又不影响解码端重建音频信号的主观听觉质量。
2.子带编码的基本思想是什么?进行子带编码的好处是什么?
解:与变换编码相同,子带编码也在频率域上寻求压缩的途径。与前者不同之处在于,它不对信号直接进行变换,而是首先用一组带通滤波器将输入信号分成若干个在不同频段上的子带信号,然后将这些子带信号经过频率搬移转变成基带信号,再对它们在奈奎斯特速率上分别重新采样。采样后的信号经过量化编码,并合并成一个总的码流传送给接收端。在接收端,首先把码流分成与原来的各子带信号相对应的子带码流,然后解码、将频谱搬移至原来的位置,最后经带通滤波、相加,得到重建的信号。
对每个子带分别进行编码的好处是:
1)可根据每个子带信号在感知上的重要性,即利用人对声音信号的感知模型(心理声学模型),对每个子带内的采样值分配不同的比特数。例如,在低频子带中,为了保护基音和共振峰的结构,就要求用较小的量化间隔、较多的量化级数,即分配较多的比特数来表示采样值。而通常发生在高频子带中的摩擦音以及类似噪声的声音,可以分配较少的比特数。
2)由于分割为子带后,降低了各子带内信号能量分布不均匀的程度,减少了动态范围,从而可以按照每个子带内信号能量来分配量化比特数,对每个子带信号分别进行自适应控制。对具有较高能量的子带用较大的量化间隔来量化,即进行粗量化;反之,则进行细量化。使得各个子带的量化噪声都束缚在本子带内,这样就可以避免能量较小的子带信号被其他频带中的量化噪声所掩盖。
3)通过频带分割,各个子带的采样频率可以成倍下降。例如,若分成频谱面积相同的N个子带,则每个子带的采样频率可以降为原始信号采样频率的1/N,因而可以减少硬件实现的难度,并便于并行处理。
3.什么叫听阈?什么叫痛阈?什么叫频域掩蔽?什么叫时域掩蔽?
解:当声音强度减弱到人耳刚刚可以听见时,此时的声压级称为最小可听阈值,简称为“听阈”。而当声音增强到使人耳感到疼痛时,这个听觉阈值称为“痛阈”。
所谓频域掩蔽是指掩蔽音与被掩蔽音同时作用时发生掩蔽效应,又称同时掩蔽。这时,掩蔽音在掩蔽效应发生期间一直起作用,是一种较强的掩蔽效应。通常,频域中的一个强音会掩蔽与之同时发声的频率相近的弱音,弱音的频率与强音的频率越接近,一般越容易被掩蔽;反之,弱音的频率离强音的频率越远,则弱音不容易被掩蔽。
除了同时发出的声音之间有掩蔽效应之外,在时间上相邻的声音之间也有掩蔽效应。即在一个强音信号之前或之后的弱音信号,也会被掩蔽掉。这种掩蔽效应称为时间域掩蔽,也称异时掩蔽。
4.什么是临界频带?简述它在音频编码中的应用。
解:所谓临界频带是指,如果掩蔽信号覆盖一定的频率范围,它的带宽逐渐增大时,掩蔽效应并不随着带宽的增大而改变,直到带宽超过某个值,掩蔽效应才不再保持不变,这个带宽就是临界频带。
通常认为,20Hz~22kHz范围内有24个临界频带。而当某个纯音位于掩蔽音的临界频带之外时,掩蔽效应仍然存在。根据“临界频带”的概念,在掩蔽阈值相同时,低频段有较窄的临界频带,而高频段则有较宽的临界频带。这样,在按临界频带划分子带时,低频段取的带宽窄,即意味着对低频有较高的频率分辨率,在高频段时则相对有较低的分辨率。这样的分配,更符合人耳的灵敏度特性,可以改善对低频段压缩编码的失真。
5.为什么要对图像数据进行压缩?其压缩原理是什么?图像压缩编码的目的是什么?目前有哪些编码方法?
解:视频信号数字化之后所面临的一个问题是巨大的数据量给存储和传输带来的压力。单纯用扩大存储容量、增加通信信道带宽的办法是不现实的。而数据压缩技术是个行之有效的方法,以压缩编码的形式存储、传输,既节约了存储空间,又提高了通信信道的传输效率,同时也可使计算机实时处理视频信息,以保证播放出高质量的视频节目。
数据压缩的理论基础是信息论。从信息论的角度来看,压缩就是去掉数据中的冗余,即保留不确定的信息,去掉确定的信息(可推知的),也就是用一种更接近信息本质的描述来代替原有冗余的描述。数字图像和视频数据中存在着大量的数据冗余和主观视觉冗余,因此图像和视频数据压缩不仅是必要的,而且也是可能的。
图像或视频压缩编码的目的,是在保证重建图像质量一定的前提下,以尽量少的比特数来表征图像或视频信息。
从信息论的角度出发,根据解码后还原的数据是否与原始数据完全相同,可将数据压缩方法分为两大类:无失真编码和限失真编码。常用的无失真编码方法有哈夫曼(Huffman)编码、算术编码和游程编码(Run-Length Encoding,RLE)等。常见的限失真编码方法有预测编码、变换编码、矢量量化、基于模型的编码等。
6.一个无记忆信源有4种符号0、1、2、3。已知p(0)=3/8,p(1)=1/4,p(2)=1/4,p(3)=1/8。试求由6000个符号构成的符号序列所含的信息量。
解:每个符号的平均信息量为
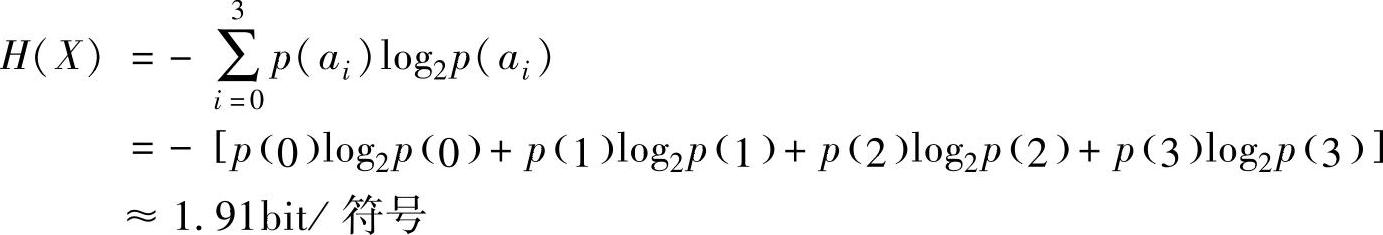
6000个符号构成的消息所含的信息量为
6000×H(X)=6000×1.91bit=11460bit
7.一个信源包含6个符号,它们的出现概率分别为0.3、0.2、0.15、0.15、0.10、0.10,试用二进制码元的哈夫曼编码方法对该信源的6个符号作信源编码,并求出码字的平均长度和编码效率。
解:
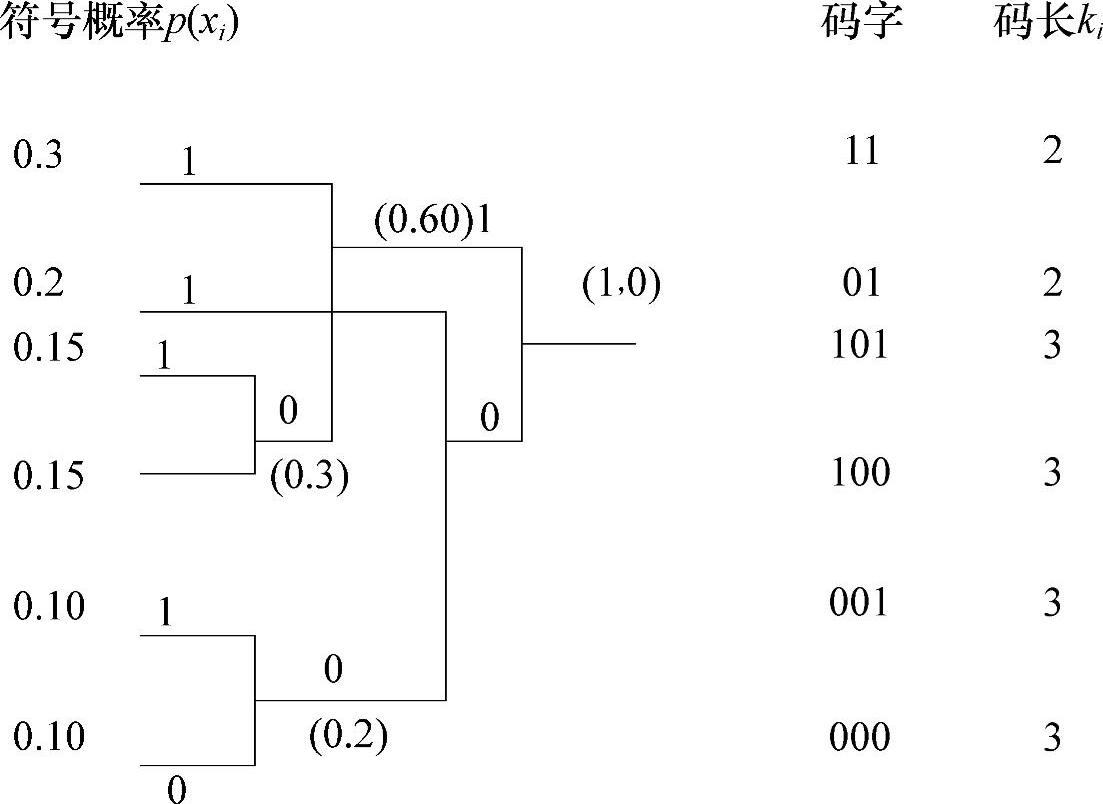
信源熵为
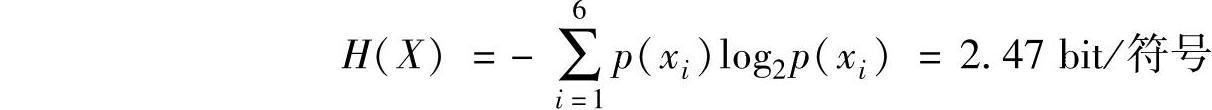
哈夫曼编码的平均码字长度为(https://www.xing528.com)
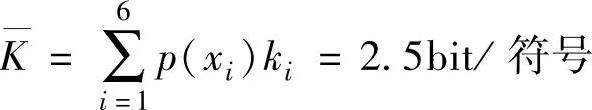
编码效率为
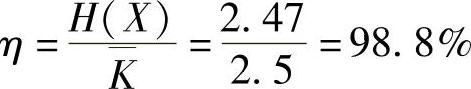
8.设有一个信源具有4个可能出现的符号X1、X2、X3、X4,其出现的概率分别为1/2、1/4、1/8、1/8。请以符号序列X2 X1 X4 X3 X1为例解释其算术编码和解码的过程。
解:编码过程如图4-5所示。
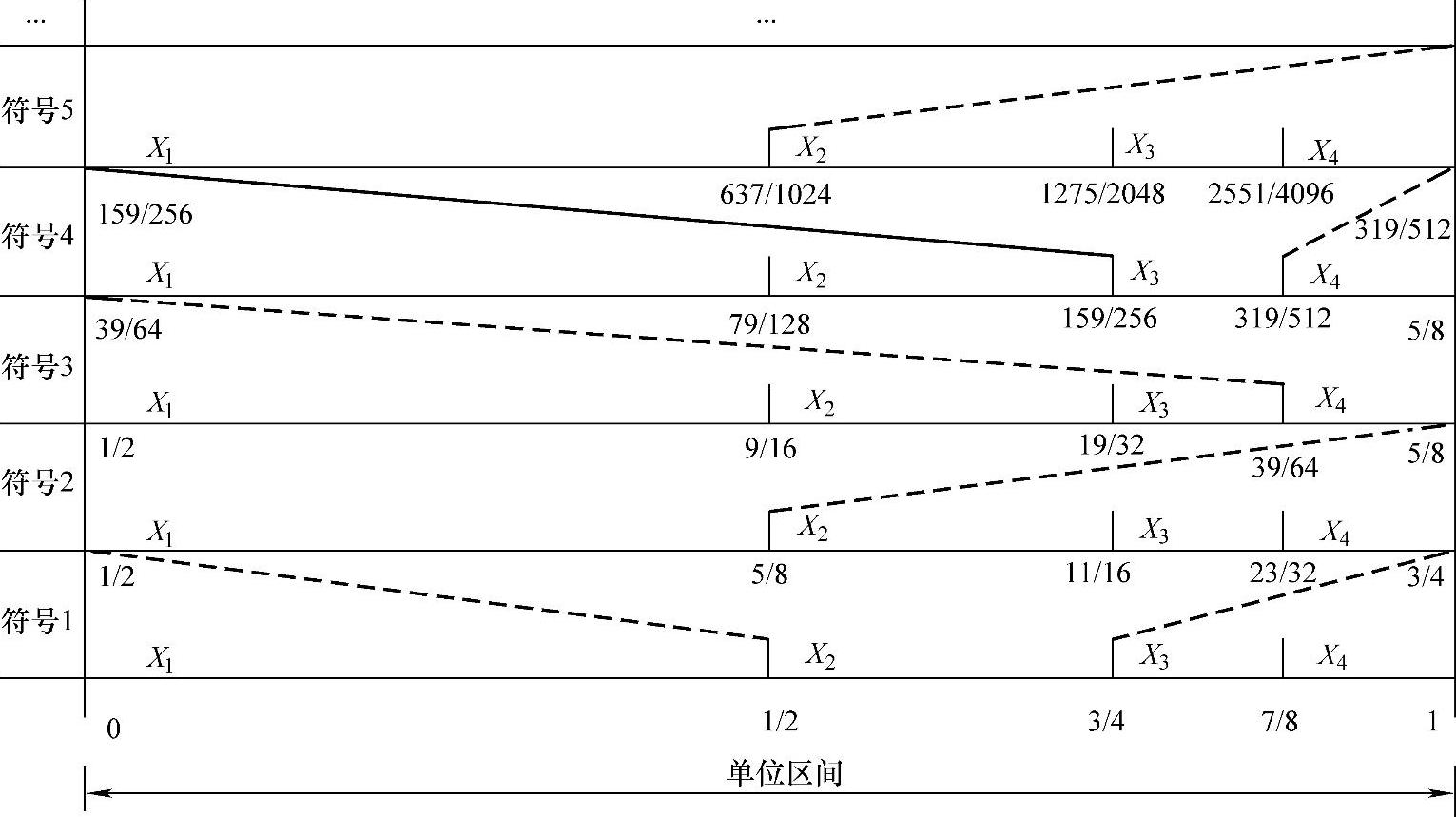
图4-5 算术编码过程
首先4个符号X1、X2、X3、X4把单位区间按比例分成4份,符号序列第1个符号为X2,则编码结果落在了区间[1/2,3/4);将此区间按比例再分为4份,符号序列第2个符号为X1,则编码结果落在区间[1/2,5/8);将此区间按比例再分为4份,符号序列第3个符号为X4,则编码结果落在区间[39/64,5/8);将此区间按比例再分为4份,符号序列第4个符号为X3,则编码结果落在区间[159/256,319/512);将此区间按比例再分为4份,符号序列第5个符号为X1,则编码结果落在区间[159/256,637/1024)……以此类推。
编码到第5个符号,编码的结果为[159/256,637/1024),即[0.62109375,0.6220703125)区间任一数字,比如0.62109376。
当收到0.62109376进行解码。首先,该数字在[1/2,3/4),即[0.5,0.75)区间,故解出第1个符号为X2;该数字又落在了[1/2,3/4)区间更小区间的[1/2,5/8),即[0.5,0.625)中,故解出第2个符号为X1;再细化区间,[39/64,5/8)即[0.609375,0.625)包含收到的码字,故解出第3个符号为X4……以此类推,细化到[159/256,319/512),即[0.62109375,0.623046875),解出第4个符号为X3;细化到[159/256,637/1024),即[0.62109375,0.6220703125),解出第5个符号为X1。由此解出符号序列为X2X1X4X3X1。
9.试对算术编码和哈夫曼编码进行比较,算术编码在哪些方面具有优越性?
解:哈夫曼编码是一种分组码,而算术编码是一种非分组码,它用一个浮点数值表示整个信源符号序列,克服了哈夫曼编码用一个特定的(整数码长)代码表示一个信源符号的缺点,可以更逼近无失真信源编码的极限。从算术编码过程产生的是一个小于1,并且大于或等于0的数值,这个数值可以唯一地被解码,精确地恢复原始的信源符号序列,无需任何码表。算术编码与哈夫曼编码方法的平均压缩效果非常接近,有关试验数据表明,在未知信源概率分布的大部分情形下,算术编码的性能优于哈夫曼编码。
10.请说明预测编码的原理,并画出DPCM编解码器的原理框图。
解:预测编码的基本原理就是利用图像数据的相关性,利用已传输的像素值对当前需要传输的像素值进行预测,然后对当前像素的实际值与预测值的差值(即预测误差)进行编码传输,而不是对当前像素值本身进行编码传输,以去除图像数据中的空间冗余或时间冗余。在接收端,将收到的预测误差的码字解码后再与预测值相加,得到当前像素值。
DPCM编解码器的原理框图如图4-6所示。
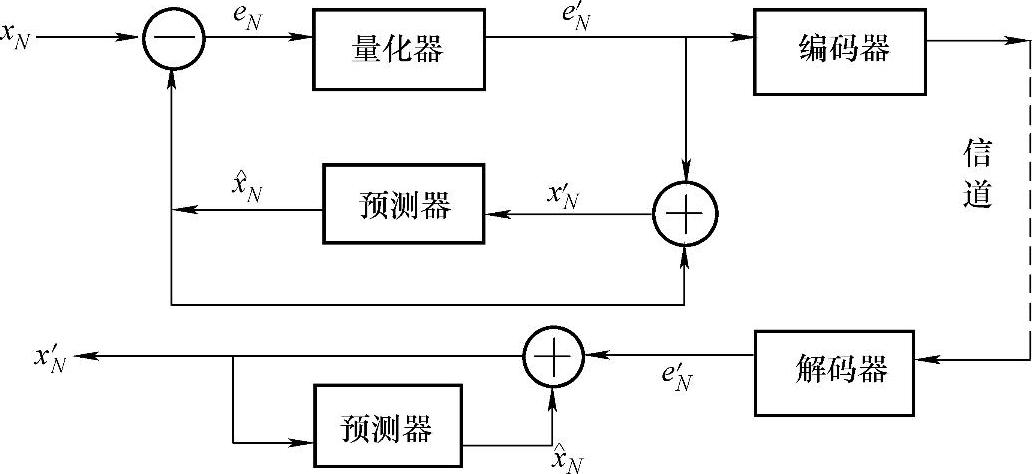
图4-6 DPCM编解码器的原理框图
11.预测编码是无失真编码还是限失真编码?为什么?
解:预测编码是通过减小图像信号在时间上和空间上的相关性来进行数据压缩的,其基本原理是利用邻近像素之间存在的相关性,将某一个像素点的灰度值用与它相邻近的像素点的灰度值来估计,并把估计值与实际值之差值作为样本进行编码。如果这个差值即预测误差,不被量化而直接编码传送,就是无失真编码。如果允许压缩过程中,存在客观信息损失(在保证传输质量的前提下),则可以进一步利用人的主观视觉特性,对预测误差量化后再编码传送,就是限失真预测编码。因为量化的过程是失真产生的根源。
12.DCT能不能压缩数据,为什么?请说明DCT编码的原理。
解:DCT本身并不能压缩数据,它只把信号映射到另一个域,但由于变换后系数之间的相关性明显降低,为在变换域里进行有效的压缩创造了有利条件。空间域中一个N×N个像素组成的图像块经过DCT后,在变换域变成了同样大小的变换系数块。变换前后的明显差别是,空间域图像块中像素之间存在很强的相关性,能量分布比较均匀;经过变换后,变换系数间的相关性基本解除,可近似认为是统计独立的,并且图像的大部分能量主要集中在直流和少数低空间频率的变换系数上。
DCT编码的原理框图如图4-7所示。
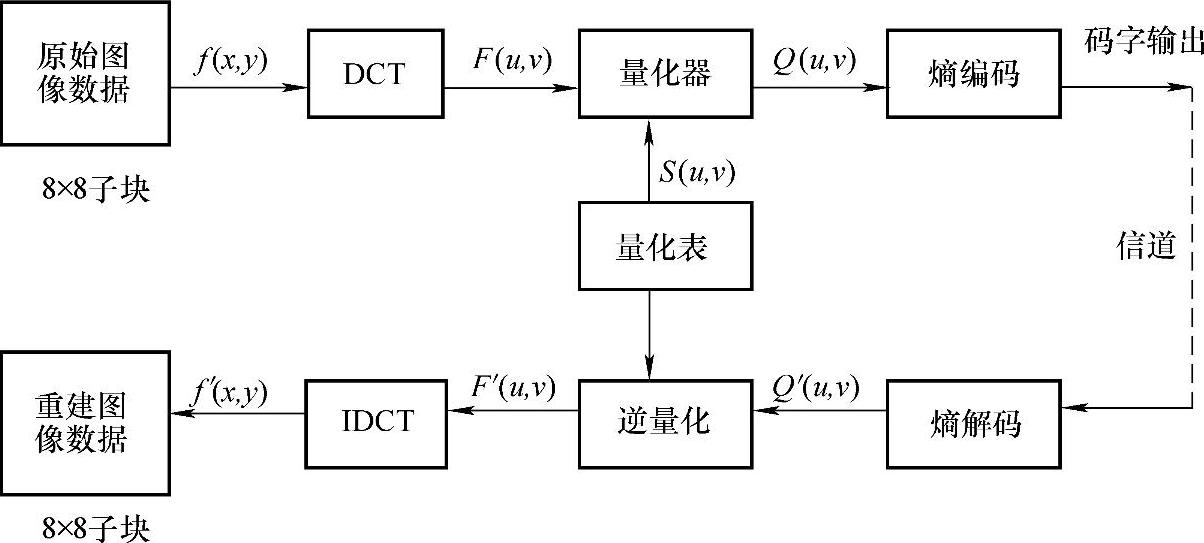
图4-7 DCT编码的原理框图
首先把一幅图像(单色图像的灰度值或彩色图像的亮度分量或色度分量信号)分成大小为8×8像素的图像子块。可以把DCT过程看做是把一个图像块表示为基图像的线性组合,这些基图像是输入图像块的组成“频率”。DCT输出64个基图像的幅值称为“DCT系数”,是输入图像块的“频谱”。为了达到压缩数据的目的,对DCT系数F(u,v)还需作量化处理。量化处理是一个多到一的映射,它是造成DCT编解码信息损失的根源。在量化过程中,应根据人眼的视觉特性,对于可见度阈值大的频率分量允许有较大的量化误差,使用较大的量化步长(量化间隔)进行粗量化;而对可见度阈值小的频率分量应保证有较小的量化误差,使用较小的量化步长进行细量化。经过量化后的变换系数是一个8×8的二维数组结构。为了进一步达到压缩数据的目的,需对量化后的变换系数进行基于统计特性的熵编码。为了便于进行熵编码和实现码字的串行传输,还应把此量化系数按一定的扫描方式转换成一维的数据序列。一个有效的方法是Z字形(Zig-Zag)扫描,可以使量化系数为0的连续长度增长,有利于后续的游长编码。熵编码可以采用哈夫曼编码,也可以采用算术编码。
13.目前最常用的运动估值算法是什么?其假设的前提条件是什么?块大小的选择与运动矢量场的一致性是如何考虑的?
解:目前最常用的运动估值算法是块匹配算法,其假设的前提条件是位于同一图像子块内的所有像素都作相同的运动,且只作平移运动。方块大小的选取受到两个矛盾的约束:块大时,一个方块可能包含多个作不同运动的物体,块内各像素作相同平移运动的假设难以成立,影响估计精度;但若块太小,则估计精度容易受噪声干扰的影响,不够可靠,而且传送运动矢量所需的附加比特数过多,不利于数据压缩。因此,必须恰到好处地选择方块的大小,以做到两者兼顾。目前的图像压缩编码标准,如MPEG-1、MPEG-2等,一般都用16×16大小块作为匹配单元,这是一个较好的折中结果。
14.简述运动自适应帧内插的原理及其特点。
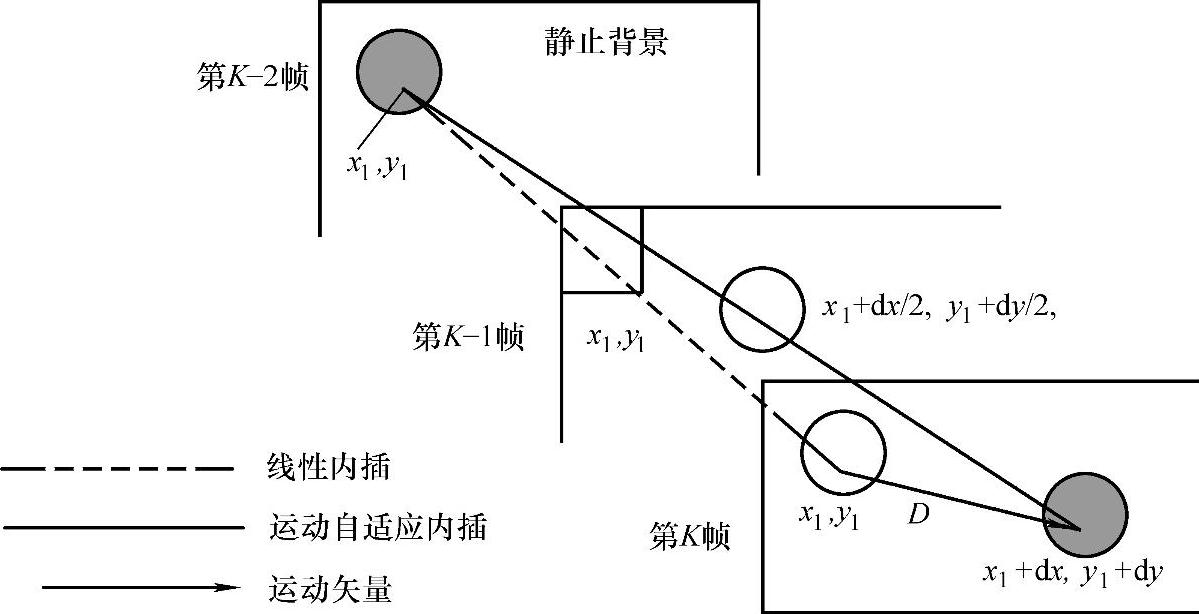
图4-8 运动自适应帧内插
解:运动自适应帧内插的原理如图4-8所示,图中第K-2帧和第K帧是传输帧,第K-1帧是内插帧。按照一般的线性内插算法,第K-1帧内位于(x1,y1)的像素要由第K-2帧和第K帧的同样处于(x1,y1)的像素值内插获得。显然,这会引起图像模糊,因为这是将运动物体上的像素值和静止背景上的像素值求混合平均,为了在内插帧中正确地恢复运动物体,必须考虑运动位移,即进行运动补偿。在第K-2帧中,中心位于(x1,y1)的运动物体在第K帧中移动到了(x1+dx,y1+dy)。因此,在内插帧第K-1帧中,该运动物体的中心处于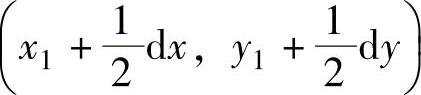 处,即该帧中位于
处,即该帧中位于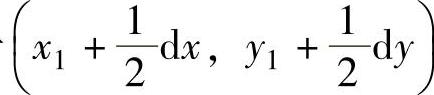 处的像素值应由第K-2帧中位于(x1,y1)的像素值和第K帧中位于(x1+dx,y1+dy)的像素值内插得到。
处的像素值应由第K-2帧中位于(x1,y1)的像素值和第K帧中位于(x1+dx,y1+dy)的像素值内插得到。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。