



1.数字音频压缩的必要性和可能性
音频信号数字化之后所面临的一个问题是巨大的数据量给存储和传输带来的压力。为了降低传输或存储的费用,就必须对数字音频信号进行压缩编码。
数字音频压缩编码主要基于两种机理:一是去除音频信号中的冗余部分,二是利用人耳的听觉感知特性,去除音频信号中人耳不能感知的声音成分,只保留人耳能感知的声音成分。
音频信号中的冗余形式主要包括时间域冗余、频率域冗余和听觉冗余。
音频信号在时间域上的冗余形式主要表现在以下几方面:
1)样值幅度分布的非均匀性使得不同幅度的样值出现的概率不同,小幅度的样值比大幅度样值出现的概率要高。
2)样值间的相关性。
3)信号周期之间的相关性。
4)静音。语音间的停顿间歇本身就是一种冗余,若能正确检测出该静音段,并去除这段时间的样值数据,就能起到压缩的作用。
音频信号在频率域上的冗余形式主要表现在以下几方面:
1)长时功率谱密度的非均匀性使得功率谱的低频成分能量较高,高频成分能量较低。
2)语音特有的短时功率谱密度表现为在某些频率上出现“峰值”,而在另一些频率上出现“谷值”。
此外,音频信号最终是给人听的,因此,要充分利用人耳的听觉特性对于音频信号感知的影响。因为人耳对信号幅度、频率的分辨能力是有限的,所以凡是人耳感觉不到的成分,即对人耳辨别声音的强度、音调、方位没有贡献的成分,称为与听觉无关的“不相关”部分,都可视为是冗余的,可以将它们压缩掉。
数字音频压缩编码的目的,是在保证重构声音质量一定的前提下,以尽量少的比特数来表征音频信息,或者是在给定的传输速率下,使得解码恢复出的重构声音的质量尽可能高。
2.人耳的听觉感知特性
由于人耳对音频信号的幅度、频率和时间的分辨能力是有限的,压缩编码就是要将那些人耳可感知的信息传递出去,而舍去那些感知不到的信息,在可接受的信号质量下降的前提下,取得较低的比特率。为了达到这样的目的,必须充分利用人耳听觉的心理声学特性。
(1)人耳的听阈与频率的关系
人耳能听到的声音频率在20Hz~20kHz范围之内,但是其灵敏度与频率有关,也就是说人耳听到的声音的响度与声音的频率有关。描述响度级、声压级,以及与声源频率之间关系的曲线称为等响度曲线,如图4-1所示。图4-1是将一组不同频率纯音的主观响度感觉与1kHz纯音相同时的声压级值用曲线连接起来的结果,图中每条曲线上的点响度相同。
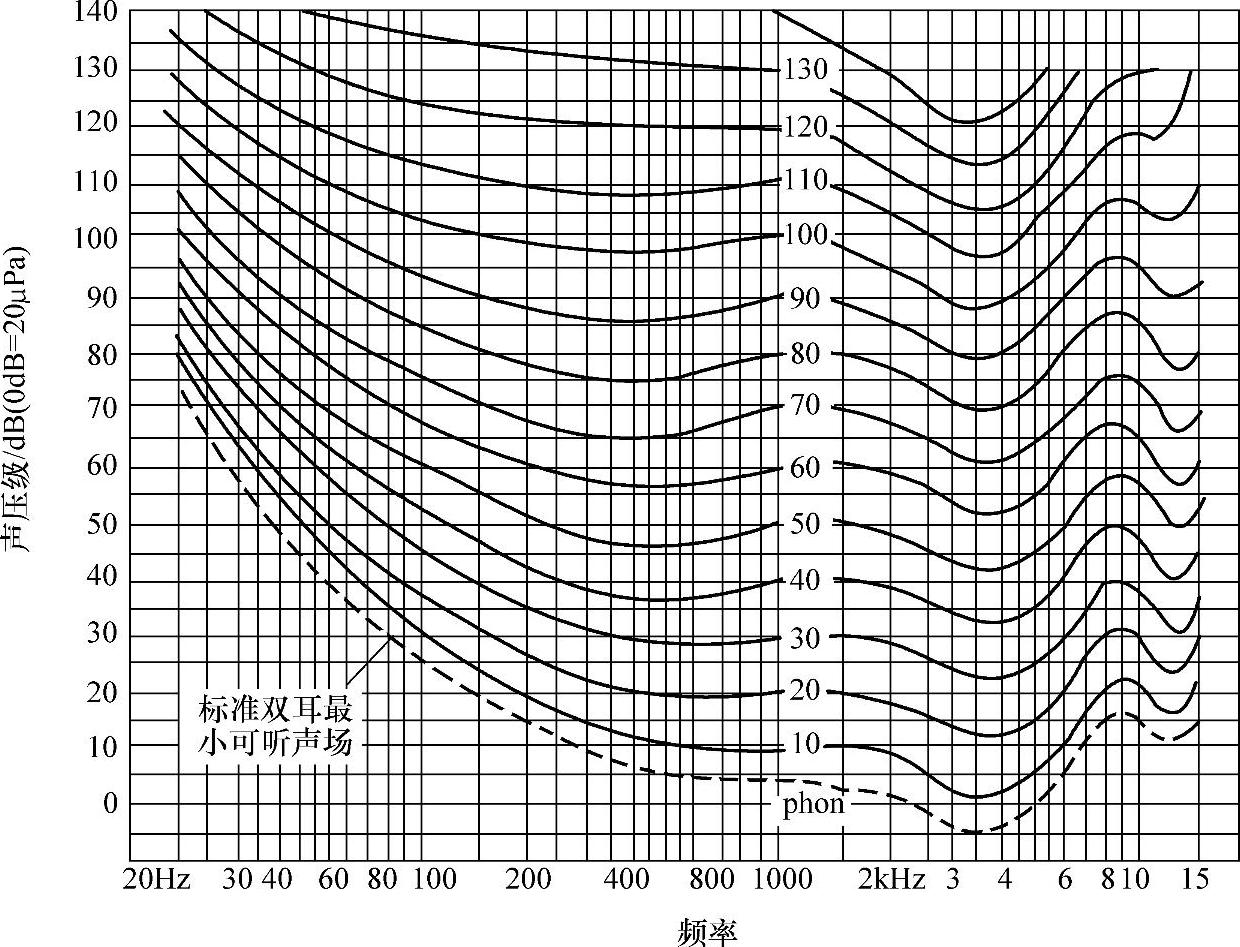
图4-1 人耳听觉的等响度曲线(https://www.xing528.com)
在人耳的可听频率范围(20Hz~20kHz)内,将声音减弱到人耳刚刚可以听见的强度,此时的声压级称为最小可听阈值,简称为“听阈”。一般以1kHz纯音为基准进行测量,人耳刚能听到的声压级为0dB(通常大于0.3dB即有感受)。图4-1中最下面的一条等响度曲线(虚线)描述的是最小可听阈值,在这条线以下的区域为不可听见区,它表示虽然存在一定的声压,但人耳却听不到。而当声音增强到使人耳感到疼痛时,这个听觉阈值称为“痛阈”。仍以1kHz纯音为基准来进行测量,使人耳感到疼痛时的声压级约140dB左右。
实验表明,人耳对不同频率的声音听阈和痛阈不一样,灵敏度也不一样。人耳的痛阈受频率的影响不大,而听阈随频率变化相当剧烈。人耳对3~4kHz的声音最敏感,幅度很小的声音信号都能被人耳听到;而在低频区(如小于800Hz)和高频区(如大于5kHz),人耳对声音的灵敏度要低得多。因此可以将输入信号与最小可听阈值相比较,去掉那些低于阈值的信号,这样可以压缩数据。
(2)人耳的听觉掩蔽效应
人耳的听觉掩蔽效应是指一个较弱的声音(被掩蔽音)的听觉感受被另一个较强的声音(掩蔽音)影响的现象。人耳的听觉掩蔽效应是一个较为复杂的心理声学和生理声学现象,主要表现为频率域掩蔽效应和时间域掩蔽效应。
1)频率域掩蔽效应。所谓频率域掩蔽是指掩蔽音与被掩蔽音同时作用时发生的掩蔽效应,又称同时掩蔽。通常,频率域中的一个强音会掩蔽与之同时发声的频率相近的弱音,弱音的频率与强音的频率越接近,越容易被掩蔽。
2)时间域掩蔽效应。除了同时发出的声音之间有掩蔽效应之外,在时间上相邻的声音之间也有掩蔽效应。即在一个强音信号之前或之后的弱音信号,也会被掩蔽掉。这种掩蔽效应称为时间域掩蔽,也称异时掩蔽。时间域掩蔽又分为前掩蔽和后掩蔽。在时间域内,听到强音之前的短暂时间内,已存在的弱音可以被掩蔽而听不到,这种现象称为前掩蔽;当强音消失后,经过较长的持续时间,才能重新听到弱音信号,这种现象称为后掩蔽。产生时间域掩蔽的主要原因是人的大脑处理信息需要花费一定的时间。时间域掩蔽也随着时间的推移很快会衰减,是一种弱掩蔽效应。
在数字音频压缩编码过程中,我们可以去除将会被掩蔽的信号分量,因为这部分信号即使传输了也不会被听见,也可以不考虑可能被掩蔽的量化噪声。
(3)临界频带
临界频带是指,如果掩蔽信号覆盖一定的频率范围,它的带宽逐渐增大时,掩蔽效应并不随着带宽的增大而改变,直到带宽增加到超过某个值,掩蔽效应才不再保持不变,这个带宽就是临界频带。信号临界频带的概念表明人的耳朵好似一组多通道的实时分析器,各分析器具有不同的灵敏度和带宽。
临界频带也代表掩蔽音的最小分辨率。例如,窄带噪声由于一个频率上靠近的大的正弦波的存在而受到掩蔽,该正弦波的频率在一定范围内改变,掩蔽效应保持不变,直到两个正弦波之间的频率超过临界频带,两者的掩蔽效应才不同。
临界频带的大小是频率的函数,随着频率的增加,临界频带也随之改变。研究表明,低频段的临界频带要比高频段的窄得多,故相比之下人耳能从低频段获得更多信息。
3.数字音频压缩编码采用的心理声学模型
心理声学模型是对人类听觉心理声学所作大量测试的统计结果,主要反映听觉阈值特性和掩蔽效应,并具体化为用于数字音频信号压缩编码的对照表。
阈值特性主要反映了只有声压高于阈值的声音才可被听觉所感受到,而阈值又随音频频率改变,通常1~5kHz范围内阈值最低,即听觉对此频率范围的声音最敏感。依据听觉的阈值特性,声音信号中声压低于阈值的音频分量可舍弃,低于阈值的编码损失也可不必考虑。
掩蔽效应指强音能抑制其邻近弱音的听觉特性。掩蔽效应表明,声音信号中,可被掩蔽的信号可以不传,也不用担心那些可被掩蔽的量化噪声。
心理声学模型对音频压缩编码的意义在于:听觉系统像一组多信道实时分析器,各自具有不同的带宽和敏感度。不能被人感知的声音信号不必传输,压缩音频带来的损失,只要不会被听觉感受,也就不必去考虑。
4.音频感知编码原理
心理声学模型中一个基本的概念就是听觉系统中存在一个最小可听觉阈值(简称听阈),强度低于这个听阈的音频信号就听不到,因此可以把这部分信号忽略掉,无需对它进行编码。心理声学模型中的另一个概念是听觉掩蔽效应。听觉主要是基于对音频信号的短暂频谱分析,在相邻频谱中,人的听觉系统无法感受邻近频谱上一个较强信号所掩蔽的失真,即存在所谓的掩蔽效应。在理想状态下,掩蔽阈值以下的失真是听不见的。于是人们从两方面着手研究音频编码:一是如何精确地计算出掩蔽阈值(即获得“心理声学模型”);二是如何从音频信号中仅仅提取可听信息加以处理,将人耳不能感知的声音成分去掉,在量化时也不必一味追求最小的量化噪声,只要量化噪声不被人耳感知即可。理想情况下,经一个音频编码器压缩后,引入的失真恰好在掩蔽阈值之下。这样,既实现了音频数据压缩的目的,又不影响解码端重建音频信号的主观听觉质量。
自适应变换编码和子带编码利用了人耳的听觉感知特性,在音频压缩编码中已得到广泛应用。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。