



针对公司的3个用例:基数估计(Cardinality Estimation)、多阶段工作流(Multi Stage Workflows)和分组集(Grouping sets),我们测试了在不同平台下它们各自的性能情况。
1.技术估计
在Spark平台和Hive平台下,完成基数估计(Cardinality Estimation)用例的性能对比情况如图13-11[24]所示。
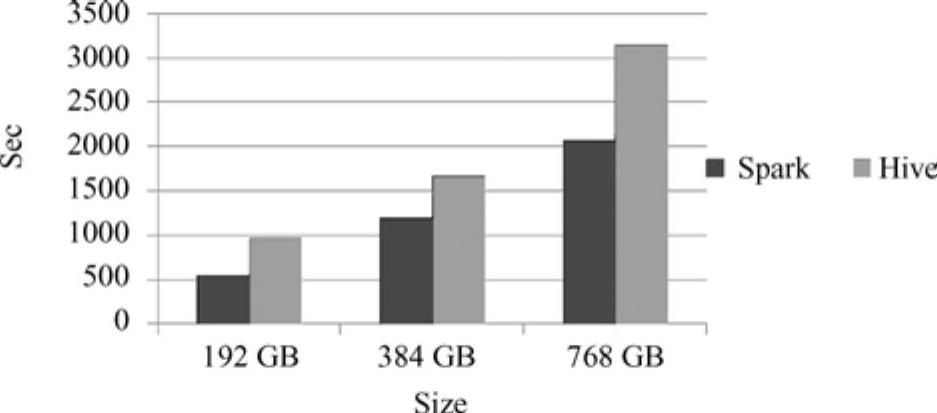
图13-11 基数估计用例的性能变化
由图13-11可以看出,当内存大小为192GB时,完成基数估计用例,在Spark平台下需要500s,而在Hive平台下需要1000s;内存大小为384GB时,Spark需要1200s,而Hive需要1700s;内存大小为768GB时,Spark需要2000s,而Hive需要3100s。由此可以推断出,在不同的内存环境下,完成基数估计用例使用Spark平台比使用Hive平台大约快25%~30%的时间。
2.多阶段工作流
在Spark平台和Hive平台下,完成多阶段工作流(Multi Stage Workflows)用例的性能对比情况如图13-12[25]所示。
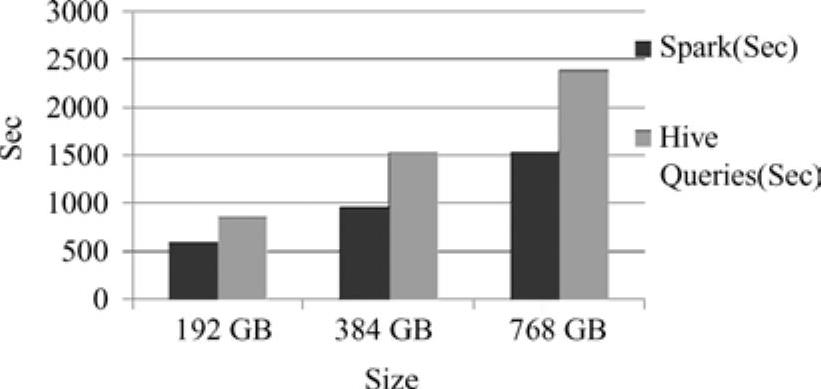 (https://www.xing528.com)
(https://www.xing528.com)
图13-12 多阶段工作流用例的性能变化
由图13-12可知,当内存大小为192GB时,完成多阶段工作流用例在Spark平台下需要550s,而在Hive平台下需要850s;内存大小为384GB时,Spark需要950s,而Hive需要1500s;内存大小为768GB时,Spark需要1500s,而Hive需要2400s。可以看出,完成此用例在Spark平台下比在Hive平台下快大约85%的时间。
3.分组集
在Spark平台和Hive平台下,完成分组集(Grouping sets)用例的性能对比情况如图13-13[26]所示。
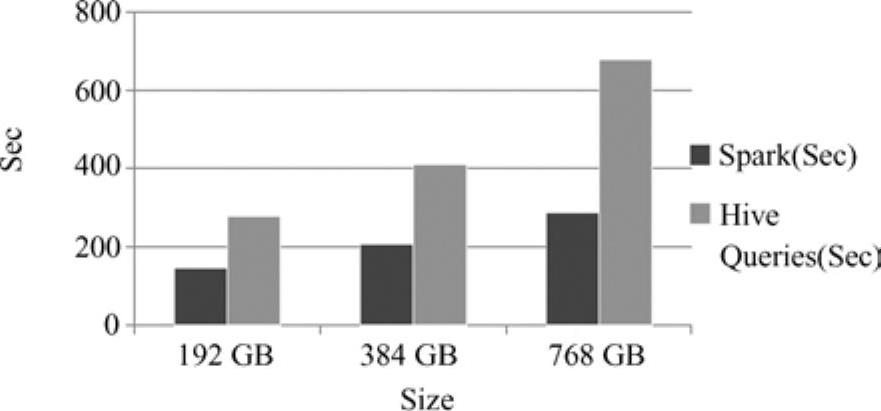
图13-13 分组集用例的性能变化
由图13-13可以得出,当内存大小为192GB时,完成分组集用例在Spark平台下需要150s,而在Hive平台下需要280s;内存大小为384GB时,Spark需要200s,而Hive需要400s;内存大小为768GB时,Spark需要300s,而Hive需要700s。采用Spark平台比采用Hive平台大约快150%的时间。
通过对比以上3个用例在使用Spark平台前后的性能变化,可以看出采用Spark技术后,它们各自的性能都有了显著的提升。正是因为Spark是基于内存计算的,所以Spark技术能实时快速地处理公司各项业务,发挥公司最大的服务功能。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。