



为了实现业务需求,Uber公司使用Sqoop工具进行数据的传递,先带读者简单了解一下有关Sqoop工具的相关内容。
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(如SQL、Oracle、Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
之前版本的Sqoop工具在进行数据摄取时,遇到了以下几个问题。
1)非SQL的数据源。
2)消息系统作为数据源。
3)多级管道。
这些问题的出现使数据摄取过程无法顺利进行,需要进一步改进。改进后的Sqoop如图13-3所示。
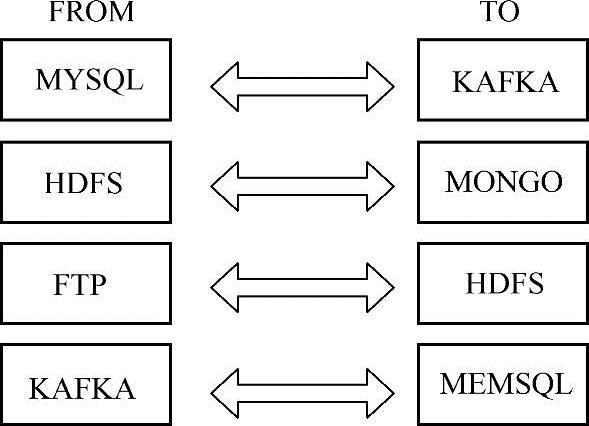
图13-3 Sqoop数据摄取
从图13-3可以看出,目前的Sqoop工具可以实现使一般的的数据传输服务从任何来源到任何目标。例如从MYSQL到KAFKA、从HDFS到MONGO、从FTP到HDFS、从KAFKA到MEMSQL等。
Sqoop连接器API如图13-4所示。

图13-4 Sqoop连接器API
由图13-4可以看出,Sqoop连接器API没有转换阶段,它直接将数据从源端经过分隔、抽取、加载这些步骤,传输到了目标端。
Uber公司使用Sqoop工具进行数据传递时是基于Spark技术的,为什么要选择Spark技术呢?原因如下。
1)MapReduce速度缓慢。
2)需要连接器API去支持转换,而不仅仅是EL。
3)可插拔的执行引擎。
4)Spark社区数量的不断增长。
5)使用方便。(https://www.xing528.com)
6)同时支持批处理、SparkSQL以及机器学习。
Sqoop在Spark上工作时,主要做3件事:创建作业、作业提交、作业执行。
(1)Sqoop Job API的工作流程
1)创建Sqoop作业。
● 创建源端和终端的作业配置。
● 对源端和终端的配置创建作业联系。
2)SparkContext持有Sqoop作业。
3)调用SqoopSparkJob.execute(conf,context)方法。
(2)Spark作业提交
1)在过程中调用Spark和Sqoop服务器来执行这项作业。
2)使用远程的Spark Context去提交。
3)Sqoop作业作为Spark提交命令的驱动。
4)构建uber.jar以及所有Sqoop的依赖。
5)以编程方式使用Spark YARN Client,或直接通过命令行提交驱动程序到YARN Client。
(3)Spark作业执行过程如图13-5所示。
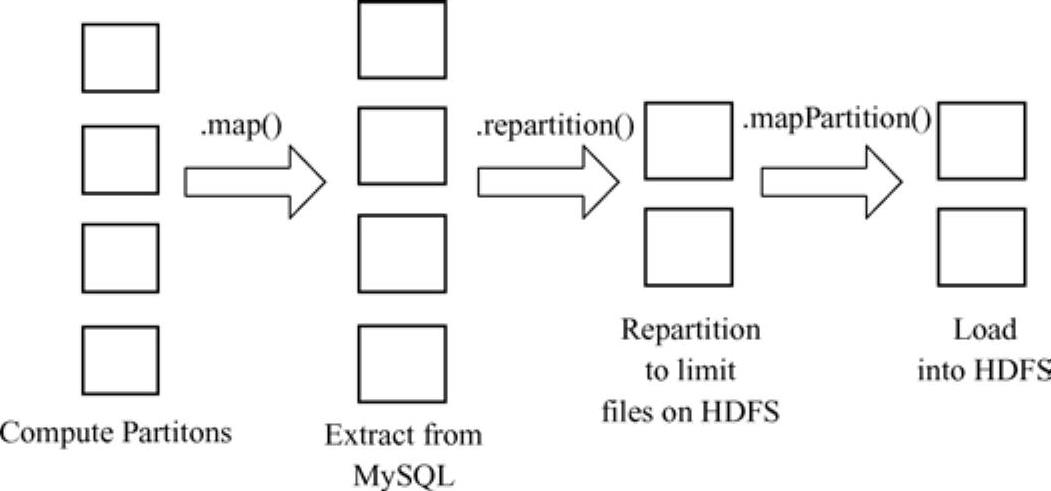
图13-5 Spark作业执行过程
从图13-5中可以看出,Spark在执行作业时首先计算分区,调用map()方法从MySQL中提取数据,接着调用repartition()方法在HDFS中再分配限制文件,最后调用mapPartition()方法将数据加载到HDFS中。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。