



【摘要】:Graphflow公司的业务平台流程如图12-8所示。图12-8 Graphflow平台工作流程由图12-8可知,平台先收集网店用户的行为数据,并对这些数据进行后台分析,再通过网络、E-mail和公开的API推荐相匹配的物品,提升客户的消费体验,最终达到提升网店效益的目的。2)支持Python API和SQL语言分析。3)拥有Spark streaming流处理框架。图12-10 模型服务器处理过程从图中可以看出,处理过程从ElasticSearch端发出的搜索开始,然后向Spark发出计算任务请求,Spark向S3发出数据请求,S3向Model Server发出数据模型请求。
Graphflow公司的业务平台流程如图12-8所示。

图12-8 Graphflow平台工作流程
由图12-8可知,平台先收集网店用户的行为数据,并对这些数据进行后台分析,再通过网络、E-mail和公开的API推荐相匹配的物品,提升客户的消费体验,最终达到提升网店效益的目的。
那么Graphflow公司为什么会选择Spark作为大数据分析平台呢?原因主要有以下几点。
1)基于内存计算,计算更快。
2)支持Python API和SQL语言分析。
3)拥有Spark streaming流处理框架。
4)支持MLlib,适合机器学习。
Spark平台架构的实现如图12-9所示。
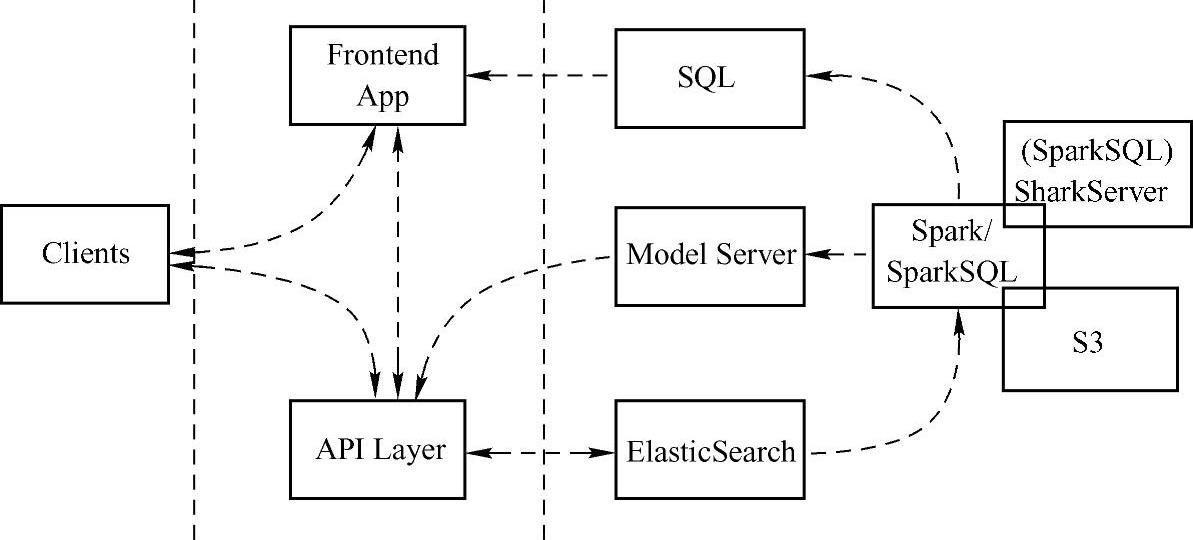
图12-9 Spark平台架构实现(https://www.xing528.com)
从上面的Spark平台架构实现图中可以看到公司采用了模型服务器。Graphflow公司对使用的模型服务器的具体要求如下。
1)能为100~1000个并行模型服务。
2)可以快速和横向扩展。
3)拥有许多小模型。
4)拥有一些非常大的模型(数以百万计的用户或项目)。
5)具有容错性。
公司使用的模型服务器处理过程如图12-10所示。
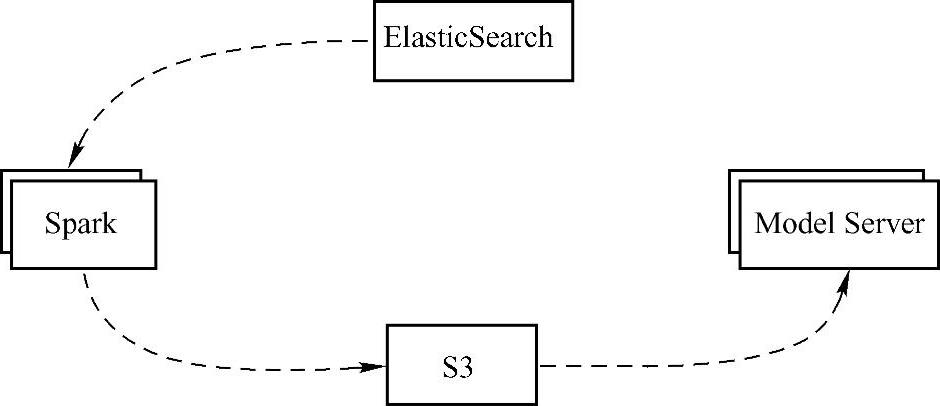
图12-10 模型服务器处理过程
从图中可以看出,处理过程从ElasticSearch端发出的搜索开始,然后向Spark发出计算任务请求,Spark向S3(类似HDFS的分布式文件系统)发出数据请求,S3向Model Server发出数据模型请求。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。