



根据需求,公司采用SparkOnYARN架构,架构如图11-6[7]所示,并进行一系列对比测试来检验该架构的效果。
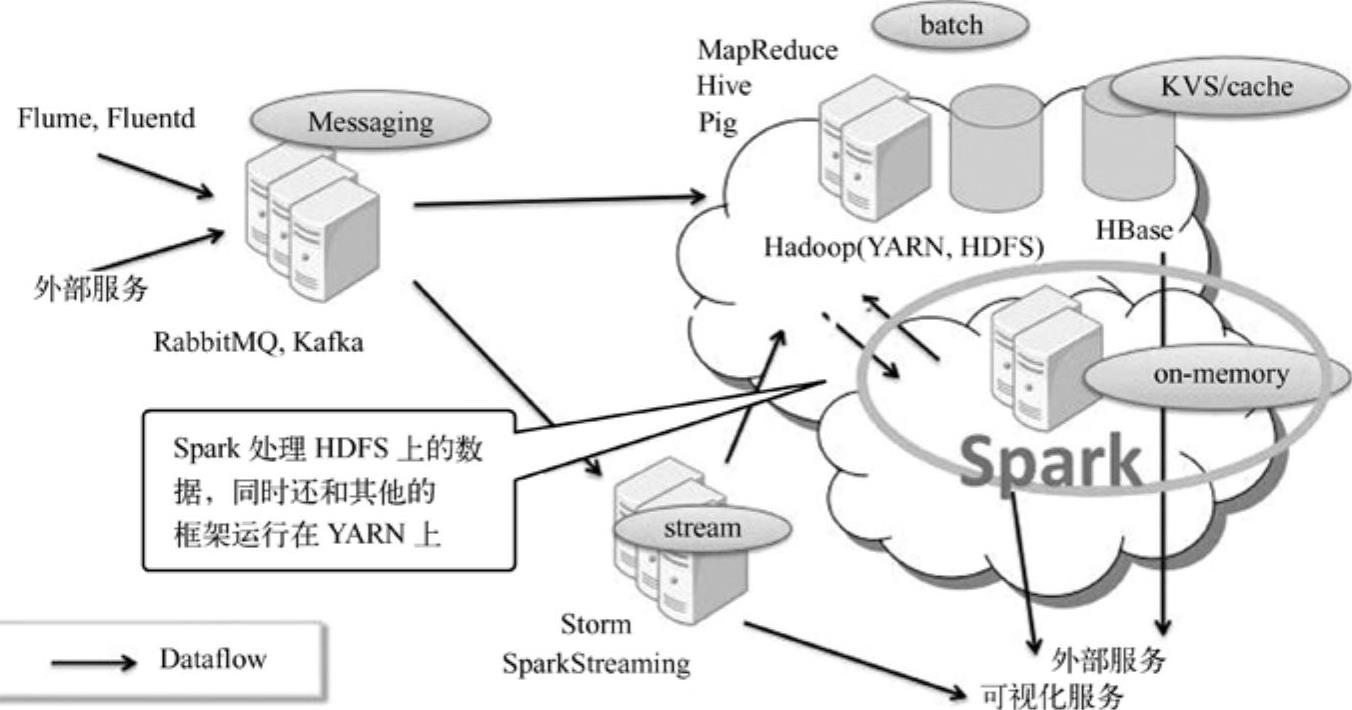
图11-6 NTTDATA公司采用的架构
从图中看出公司应用的是Hadoop生态系统“(Hive、Hbase、Pig)+Spark+Storm”混合架构来应对离线、准实时和实时的处理情况。
下面我们将从表11-1[8]中的4个方面评估该平台的使用情况。
表11-1 Hive与Spark应用平台对比分析
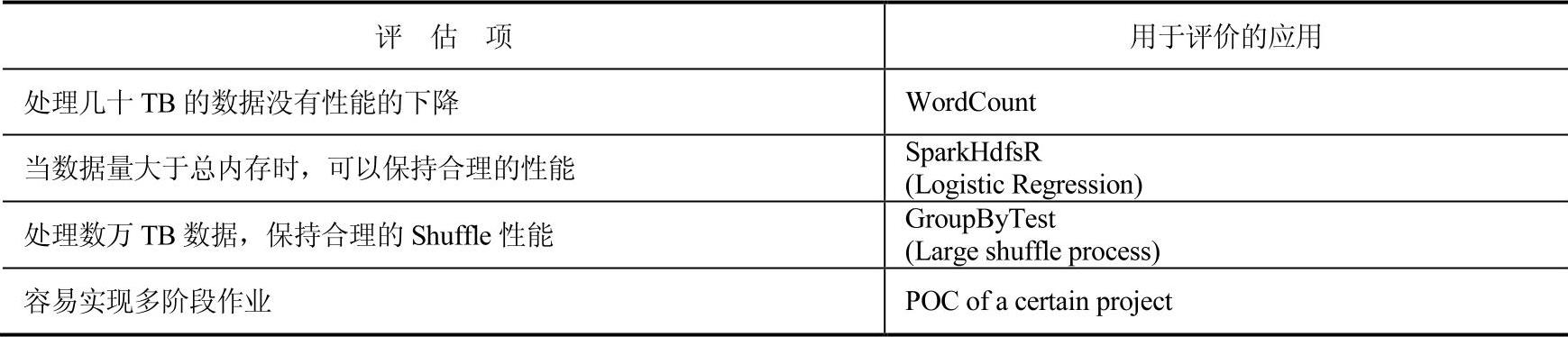
由表11-1可以看出,平台将从应对大数据量(几十TB数据)情况、数据量比总有效内存多的情况和大数据量下的Shuffle性能3个方面进行评估。集群的硬件和软件配置情况如图11-7[8]所示。
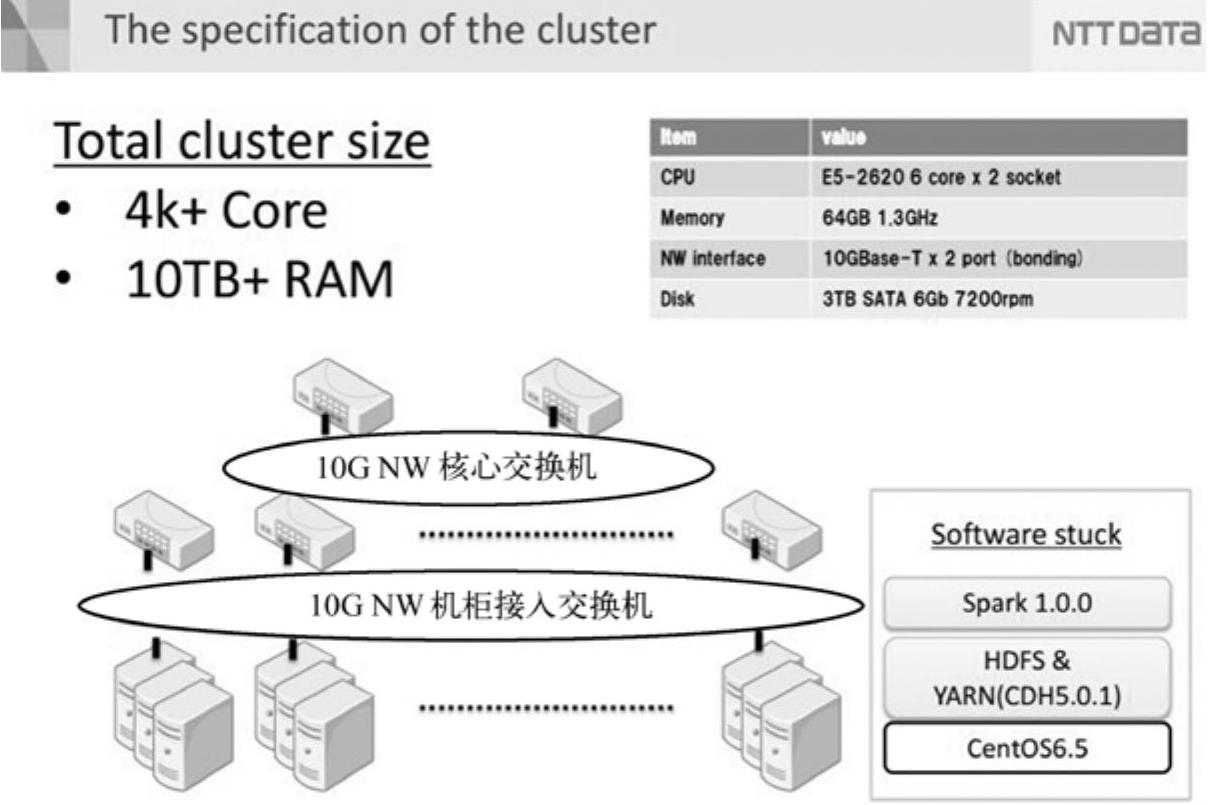
图11-7 被评估系统的硬件和软件配置情况
平台整体有4000以上的核心和10TB以上的内存,系统是CentOS6.5,使用SparkOn YARN架构。下面将具体分析每个评估方法的效果。
1.根据WordCount任务对数据处理性能评估
根据输入数据为27TB的处理时间如下图11-8[8]所示。
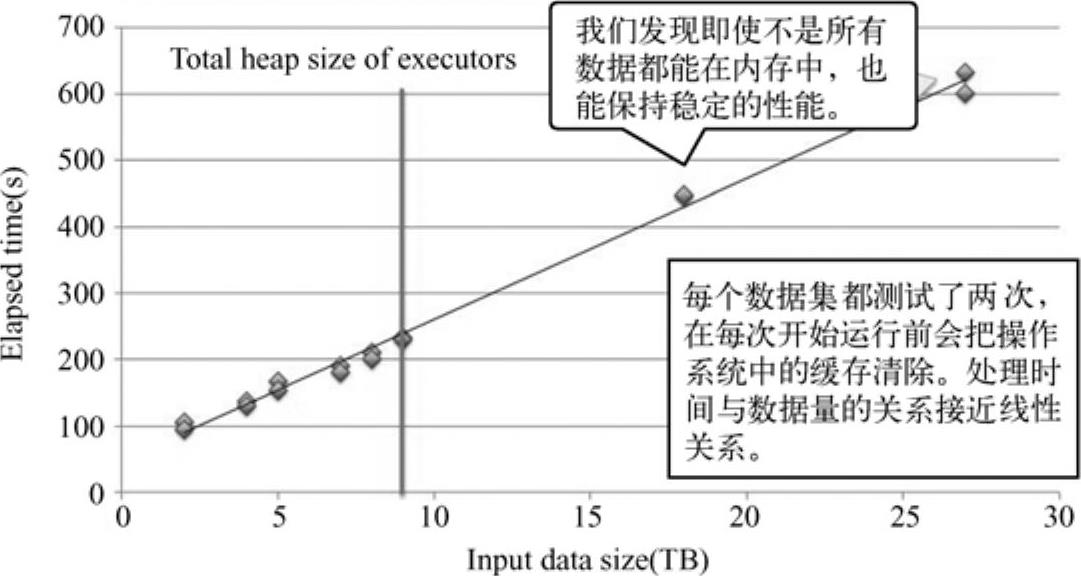
图11-8 输入数据量与处理时间的关系
由图11-8可知,即使不是所有数据都能存在内存中,处理时间与数据量的关系接近线性关系,性能比较合理。下图11-9[7]显示一个节点处理过程中的CPU、NW和I/O的消耗情况。
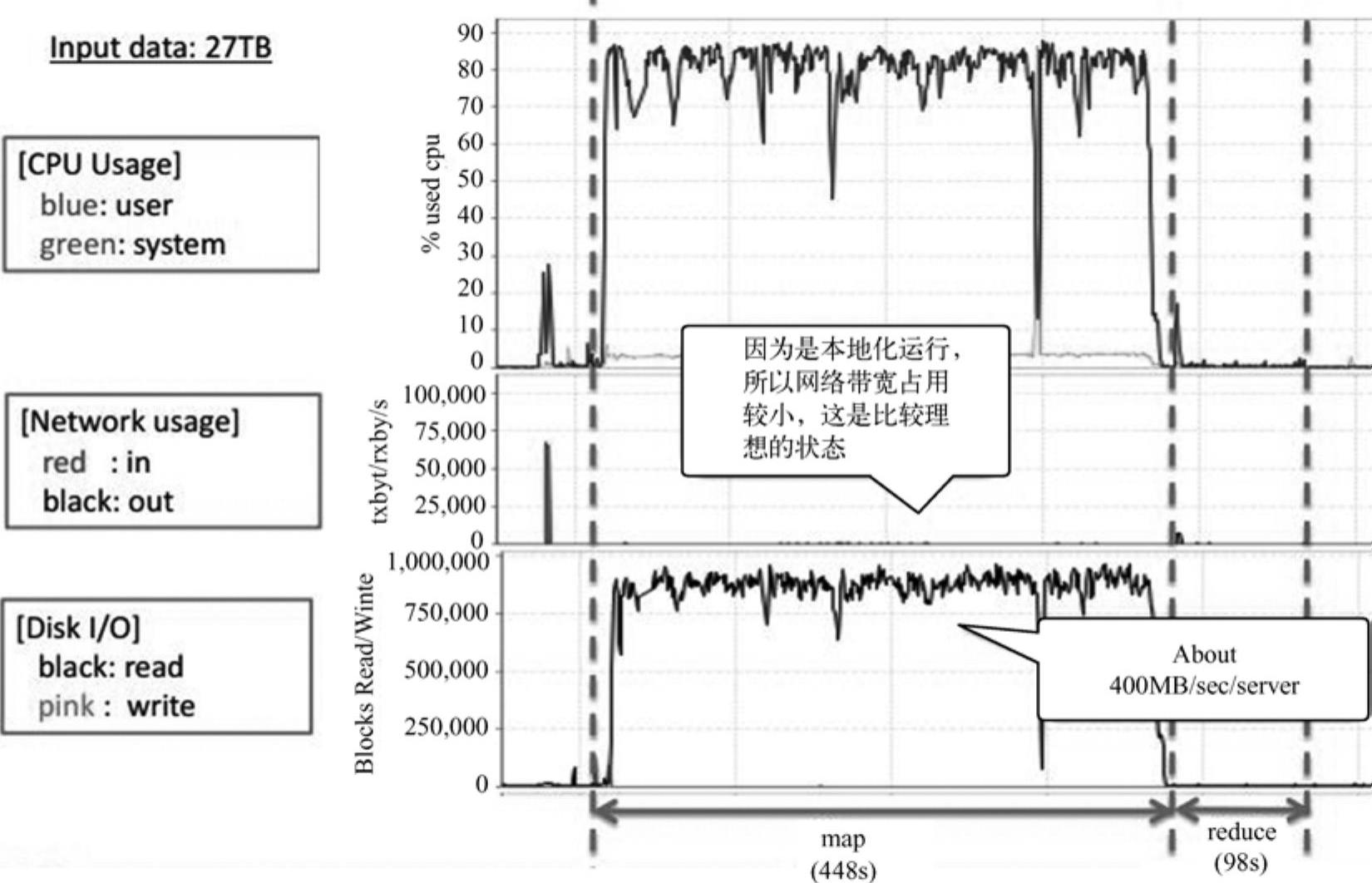
图11-9 处理过程中CPU、NW和I/O的消耗情况
从图11-9中看出,在CPU执行方面,CPU使用率在65%到85%区间浮动,说明CPU的利用情况良好;在网络方面,因为是本地执行,故网络带宽占用比较小,处于理想状态;在硬盘I/O方面,map阶段硬盘吞吐量比较大,花费时间为448秒,reduce阶段相对少很多,98s。
总之,WordCount算法的处理性能主要决定于map端,reduce端不大可能成为处理性能的瓶颈,主要因为map端输出的数据量比较小;此外当数据量超过内存储存能力而存入硬盘时,任务的整体处理性能也比较合理,吞吐量也比较稳定。
2.根据SparkHdfsLR任务的评估迭代性能
单个服务器可用内存为26GB,随着输入数据的增加,处理消耗时间如图11-10㊀所示。(https://www.xing528.com)
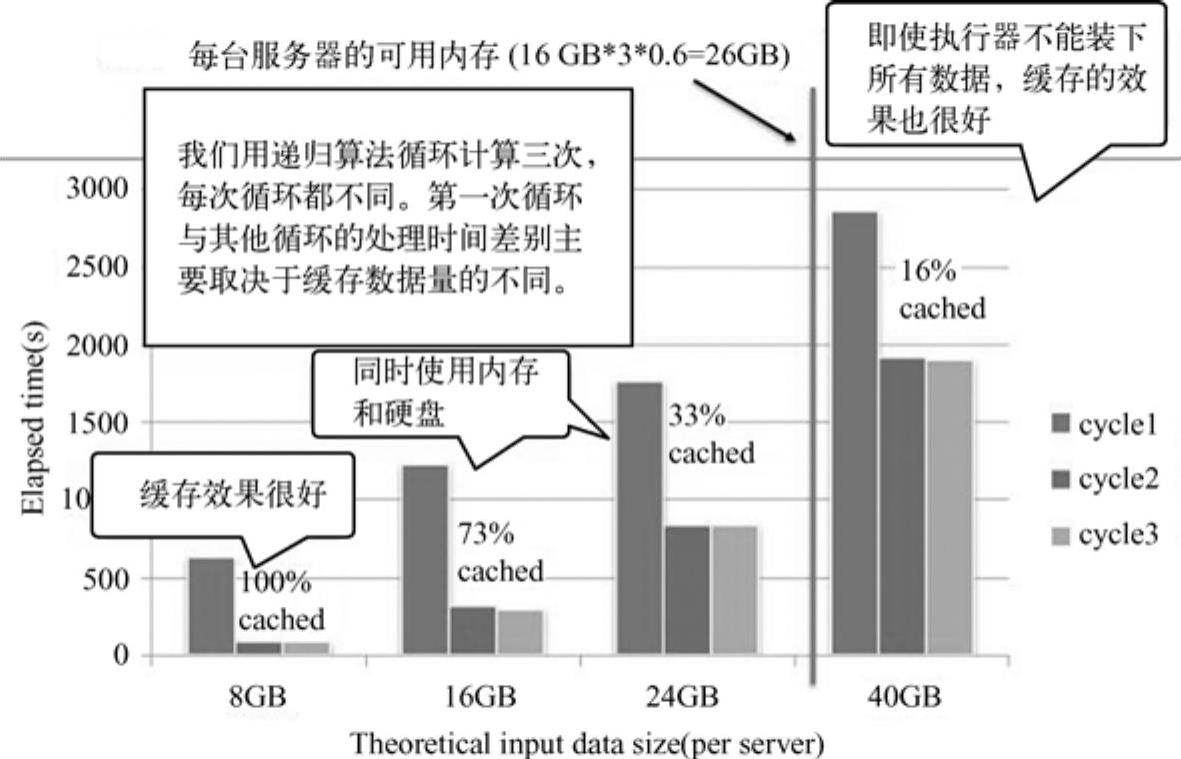
图11-10 输入数据与处理时间的关系
从图中可见,用递归算法计算3个周期,当缓存不同的情况下处理时间各不相同,第一周期的时间普遍较第二周期和第三周期长(因为第一次需要从硬盘读取数据),第二周期与第三周期的运行时间相当(从内存读取数据)。缓存数据百分比越大,各周期消耗时间越少。下图11-11[7]显示了处理过程中CPU、NW和I/O的消耗情况。
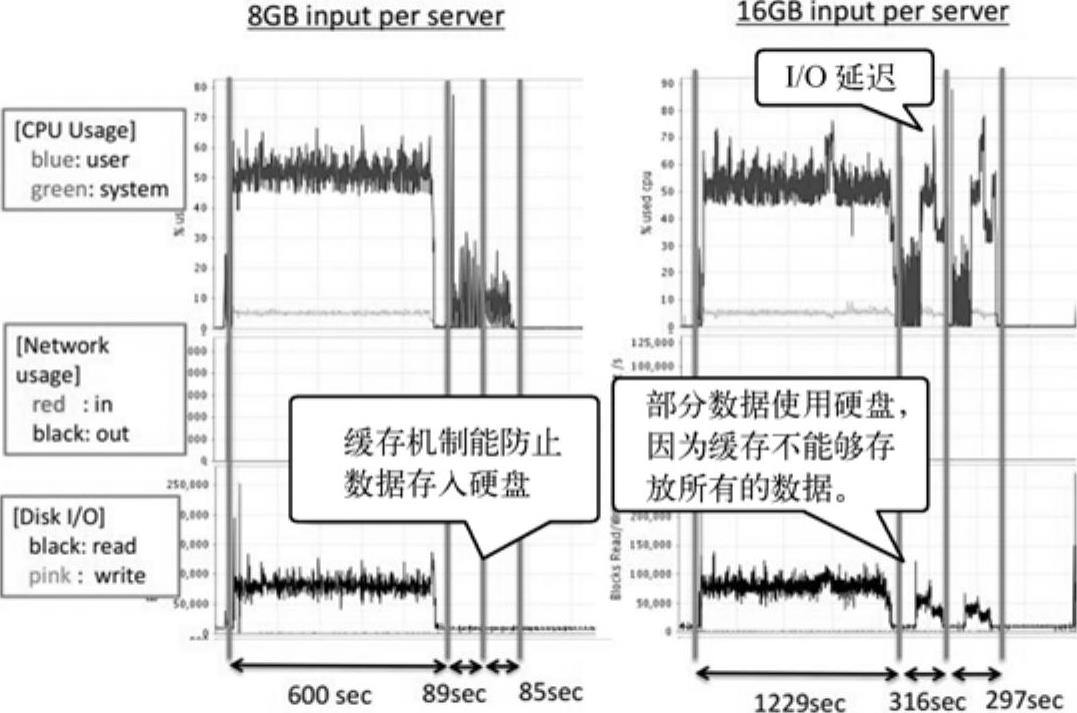
图11-11 处理过程中CPU、NW和I/O的消耗情况
由图11-11中看到每个服务器16GB输入的I/O延迟比8GB延迟更显著;8GB的输入情况下缓存机制能防止数据存入硬盘,16GB输入情况下会有数据占用硬盘,这导致I/O延迟,导致时间开销增加。
总之,内存机制更适用于迭代算法;当输入数据大于可用内存时,RDD缓存机制一致性工作能增加吞吐量;当把数据存到RDD中时最小化包装开销是很重要的优化策略。
3.根据GroupByTest任务评估大量Shuffle处理性能
Shuffle数据量与处理时间的关系如图11-12所示。
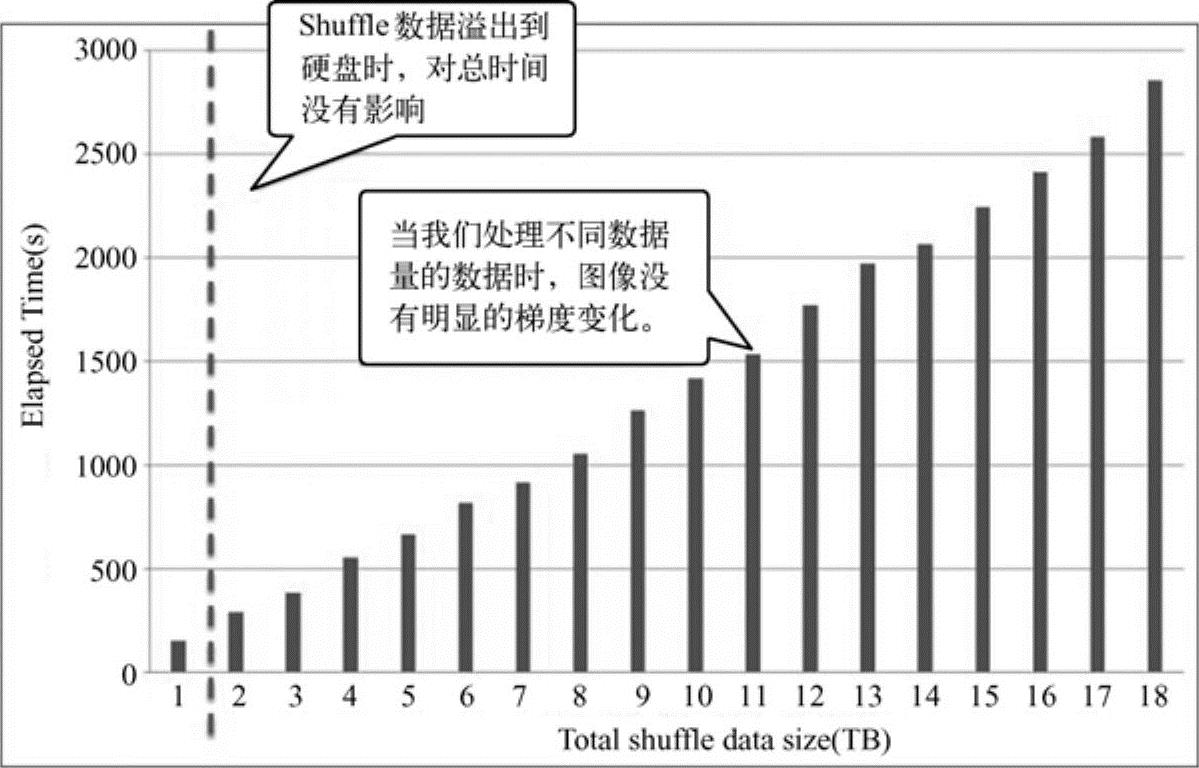
图11-12 Shuffle数据量与处理时间的关系
从图中看出,在Shuffle数据量不断增加的过程中,当Shuffle的数据开始溢出到硬盘中后,没有看到图像中激烈的梯度变化,整体处理时间随着Shuffle数据量的增长而稳定增长。不同Shuffle模式情况下的测试结果如图11-13所示。
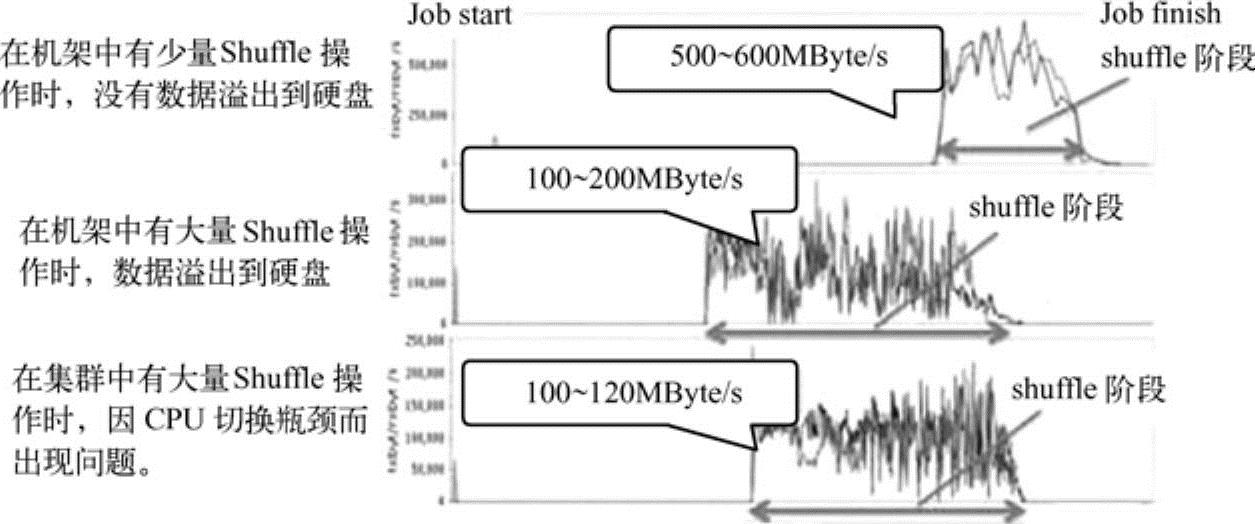
图11-13 不同Shuffle模式测试下网络资源使用情况
在图11-13中可以明显看到硬盘I/O和网络带宽瓶颈的出现,这是因为在运行shuffle测试时该任务的map任务产生了大量输出数据。说明大量Shuffle在机架内时,数据溢出到硬盘,CPU占用达到100%,数据吞吐仅有100~200MBytes;在大量Shuffle在集群中时,因为CPU切换瓶颈,导致数据吞吐大幅下降。
总之,在Shuffle输入量增加时,处理时间接近线性增长。当Shuffle数据溢出到硬盘中后,硬盘接入操作会在Shuffle相关任务间竞争,如shuffleMapTask(WRITE)、Fetcher(READ)等,这个竞争会影响处理性能。
4.POC[9]性能测试
图11-14[10]为POC流程图。
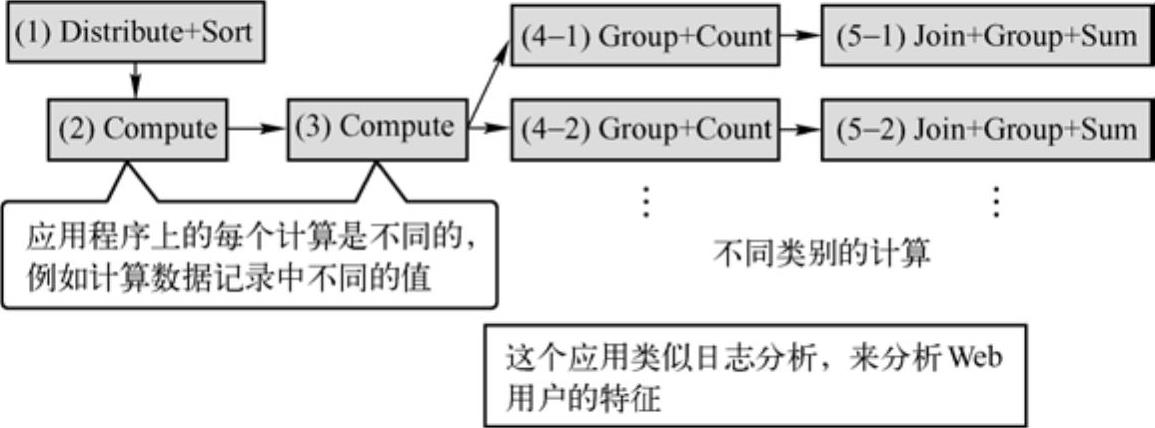
图11-14 POC流程图
图11-14中所示为一个实际的生产测试流程,包括排序、计算、连接和分组求和操作,作业的任务是找到Web使用者的特性。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。