



目前,腾讯内部规模最大的分布式系统是腾讯分布式数据仓库(Tencent Distributed DataWarehouse,简称TDW),如图9-1[1]所示。TDW集中了腾讯内部各个产品的数据,为每个产品提供海量数据存储和分析服务,包括数据挖掘、产品报表、经营分析等服务。TDW作为腾讯首批对外开源软件,代码已经托管到CSDNCODE平台。

图9-1 TDW腾讯分布式数据仓库平台
腾讯分布式数据仓库,支持百PB级的数据存储和计算,为公司提供海量、高效、稳定的大数据平台支撑和决策支持。
TDW计算引擎包括两部分:一个是偏离线的MapReduce,一个是偏实时的Spark。腾讯TDW Spark平台基于社区最新Spark版本进行深度改造,在性能、稳定和规模方面都得到了极大的提高,为大数据挖掘任务提供了有力的支持。
下面将介绍基于物品的协同过滤推荐算法案例在TDW Spark与MapReudce上的实现对比。
1.算法介绍
互联网的发展导致了信息爆炸。面对海量的信息,如何对信息进行刷选和过滤,将用户最关注最感兴趣的信息展现在用户面前,已经成为了一个亟待解决的问题。推荐系统可以通过用户与信息之间的联系,一方面帮助用户获取有用的信息,另一方面又能让信息展现在对其感兴趣的用户面前,实现了信息提供商与用户的双赢。
协同过滤推荐(Collaborative Filtering Recommendation)算法是最经典最常用的推荐算法,算法通过分析用户兴趣,在用户群中找到指定用户的相似用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。协同过滤可细分为以下3种。
1)User-based CF:基于User的协同过滤,通过不同用户对Item的评分来评测用户之间的相似性,根据用户之间的相似性做出推荐。
2)Item-based CF:基于Item的协同过滤,通过用户对不同Item的评分来评测Item之间的相似性,根据Item之间的相似性做出推荐。
3)Model-based CF:以模型为基础的协同过滤(Model-based Collaborative Filtering)是先用历史资料得到一个模型,再用此模型进行预测推荐。
2.推荐问题背景描述
1)输入数据格式:Uid,ItemId,Rating(用户Uid对ItemId的评分)。
2)输出数据:每个ItemId相似性最高的前N个ItemId。
3)由于篇幅限制,这里只选择基于Item的协同过滤算法解决的案例。
3.算法逻辑
基于Item的协同过滤算法的基本假设为两个相似的Item获得同一个用户好评的可能性较高。因此,该算法首先计算用户对物品的喜好程度,然后根据用户的喜好计算Item之间的相似度,最后找出与每个Item最相似的前N个Item。该算法的详细描述如下。
计算用户喜好:不同用户对Item的评分数值可能相差较大,因此需要先对每个用户的评分做二元化处理,例如对于某一用户对某一Item的评分大于其给出的平均评分则标记为好评1,否则为差评0。
计算Item相似性:采用Jaccard系数作为计算两个Item的相似性方法。狭义Jaccard相似度适合计算两个集合之间的相似程度,计算方法为两个集合的交集除以其并集,具体分为以下3步。
1)Item好评数统计,统计每个Item的好评用户数。
2)Item好评键值对统计,统计任意两个有关联Item的相同好评用户数。
3)Item相似性计算,计算任意两个有关联Item的相似度。
找出最相似的前N个Item。这一步中,Item的相似度还需要归一化后整合,然后求出每个Item最相似的前N个Item,具体的分为以下3步。(https://www.xing528.com)
1)Item相似性归一化。
2)Item相似性评分整合。
3)获取每个Item相似性最高的前N个Item。
4.基于HadoopMapReduce实现的方案
在实现基于物品的协同过滤推荐算法中,使用MapReduce编程模型需要为每一步实现一个MapReduce作业,一共包含7个MapRduce作业。每个MapReduce作业都包含map和reduce,其中map从HDFS读取数据,输出数据通过Shuffle把键值对发送到reduce,reduce阶段以<key,Iterator<value>>作为输入,输出经过处理的键值对到HDFS。其运行原理如图9-2所示。
使用MapReduce实现基于物品的协同过滤推荐算法包括7个MapReduce作业,而7个MapReduce作业意味着需要7次读取和写入HDFS,它们的输入输出数据存在关联,7个作业输入输出数据关系如下图9-3所示。
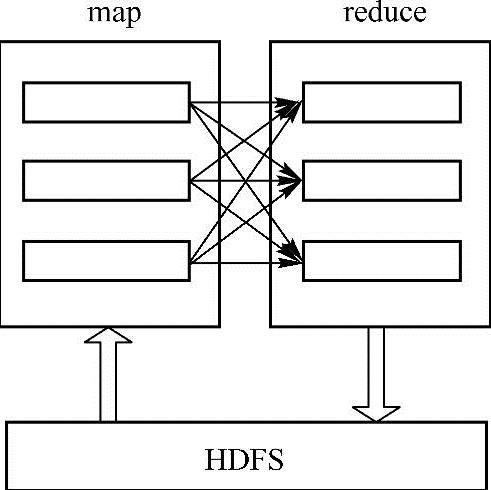
图9-2 MapReduce

图9-3 算法中7个mapreduce的关联图
上述算法是传统Hadoop的MapReduce计算模型的实现,但是会有如下问题。
1)为了实现一个业务逻辑需要使用7个MapReduce作业,7个作业间的数据交换通过HDFS完成,增加了网络和磁盘的开销。
2)7个作业都需要分别调度到集群中运行,增加了Gaia集群(Gaia是腾讯云计算中心的资源调度平台,类似YARN和Mesos资源管理系统)的资源调度开销。
3)MR2和MR3重复读取相同的数据,造成冗余的HDFS读写开销。
5.基于Spark的实现方案
相比于上述的MapReduce编程模型,Spark提供了更加灵活的DAG编程模型,不仅包含传统的map、reduce接口,还增加了filter、flatMap、union等操作接口,使得编写Spark程序更加灵活方便。使用Spark编程接口实现上述的业务逻辑如图9-4[2]所示。
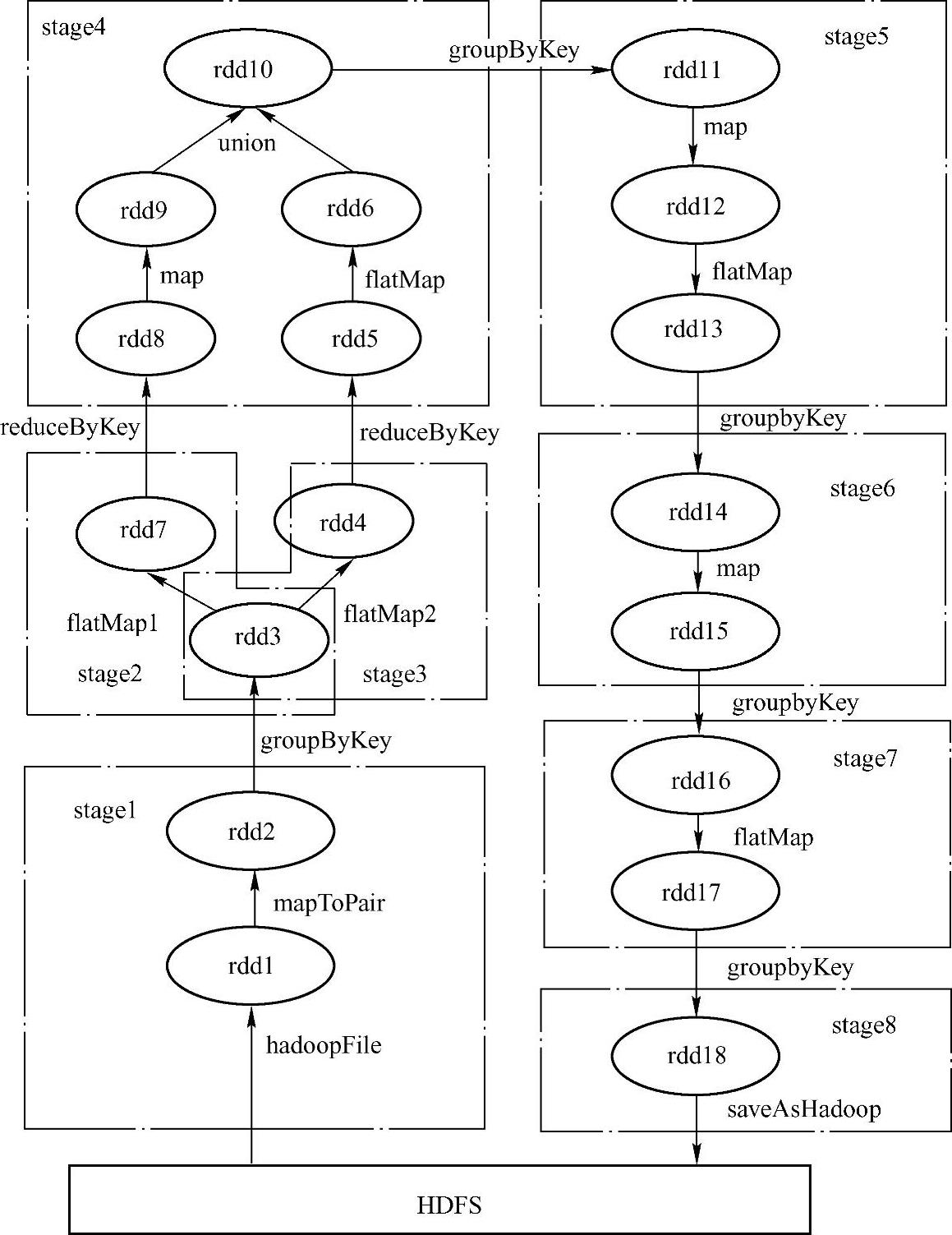
图9-4 Spark中RDD的执行逻辑
相对于HadoopMapReduce,Spark在以下方面优化了作业的执行时间和资源利用。
1)DAG编程模型。通过Spark的DAG编程模型可以把7个MapReduce简化为一个Spark作业。Spark会把该作业自动切分为8个Stage,每个Stage包含多个可并行执行的 Task。Stage之间的数据通过Shuffle传递。最终只需要分别读取和写入HDFS一次。减少了6次HDFS的读写,读写HDFS次数减少了70%。
2)Spark作业启动后会申请所需的Executor资源,所有Stage的Task以线程的方式运行,共用Executor,相对于MapReduce方式,Spark申请资源的次数减少了近90%。
3)Spark引入了RDD模型,中间数据都以RDD的形式存储,而RDD分布存储于slave节点的内存中,这就减少了计算过程中读写磁盘的次数。RDD还提供cache机制,例如对图9-4中的rdd3进行cache操作后,rdd4和rdd7都可以访问rdd3的数据。相对于MapReduce解决了MR2和MR3重复读取相同数据带来的问题。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。