



Hadoop和Spark的Shuffle机制中,重要的区别是数据的聚合和聚合数据的计算。对于Hadoop,聚合是通过对同一分区内的数据按照键值排序,键值相同的数据会彼此相邻,从而达到聚合的目的,而聚合后的数据会被交给combine(map端)和reduce(reduce端)函数去处理。对于Spark,聚合以及数据计算的过程,是交付给聚合器(Aggregator)处理的。实例化一个聚合器的时候,需要提供3个函数,分别是:createCombiner:V=>C,mergeValue: (C,V)=>C以及mergeCombiners:(C,C)=>C。
下面将以单词统计程序中的reduceByKey(_+_)转换操作为例,介绍这3个函数究竟是如何实现数据的聚合和计算的。
Spark会使用哈希表来存储所有聚合数据的处理结果,如图8-2所示,图中的浅色空槽用于存储键值,右侧相邻深色空槽表示该键值对应的计算值。聚合器开始处理聚合数据之前,哈希表是空的。
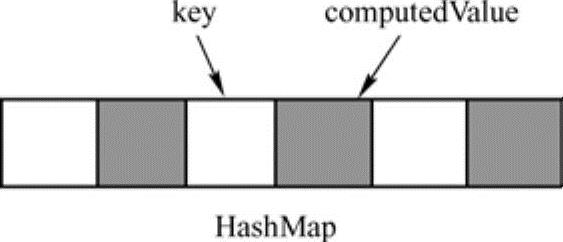
图8-2 未插入任何数据的哈希表
假设需要聚合的数据是<"A",1>、<"B",1>、<"A",1>,需要注意,这时候数据是无序的。对于第一个数据<"A",1>,Spark会通过散列函数计算键值“A”对应的哈希表地址,假设此时得到的哈希值为1,因此在哈希表中,地址为2的空槽用于存放键值“A”,地址为3的空槽用于存放计算后的值。由于地址为2和地址为3的槽均为空槽,这时候会调用createCombiner(kv._2)函数来计算初始值。对于reduceByKey转换操作,createCombiner实际为(v:V)=>v,因此得到计算值为1,将“A”放入到地址为2的空槽中,将1放入到地址为3的插槽中,如图8-3左侧所示。同理,对于数据<"B",1>,可以放入到另外两个空槽中,如图8-3右侧所示。
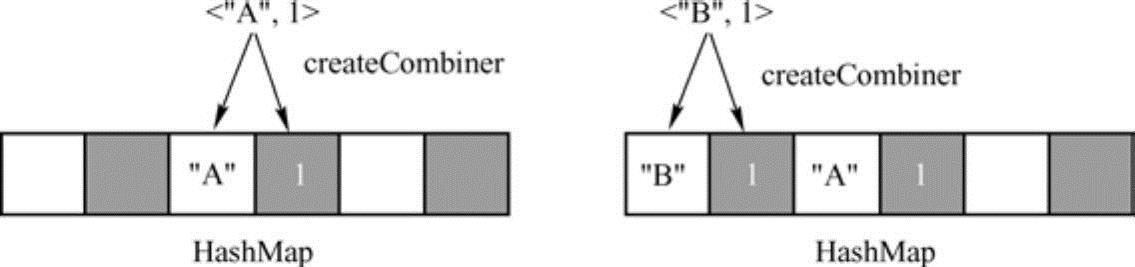
图8-3 分别插入不同键值后的哈希表
第三个数据是<"A",1>,计算得到地址为1,此时因为地址为2和地址为3的插槽已经有值oldValue,这时候调用mergeValue(oldValue,kv._2)来计算新的值。对于reduceByKey转换操作,mergeValue实际上为用户在调用reduceBykey时候指定的函数,在本例中,该函数为“_+_”,因此得到新的值为2,更新地址为3的槽。结果如图8-4所示。(https://www.xing528.com)
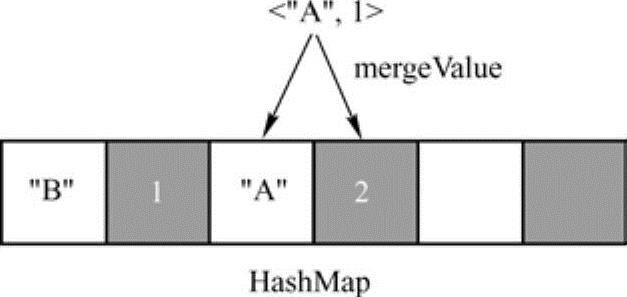
图8-4 更新已有值后的哈希表
reduceByKey指定了combiner,因此会在map端执行结合操作,reducer接收到的键值对数据,值的类型是C而非V(尽管在本例中,C和V是相同类型),这时候如果键值对应的槽为空槽,直接插入kc._2,否则调用mergeCombiners(oldValue,kc._2)函数来计算新的值。对于reduceByKey转换操作,mergeCombiners实际为用户调用reduceBykey时指定的函数。图8-5为执行mergeCombiners前后的哈希表状态。
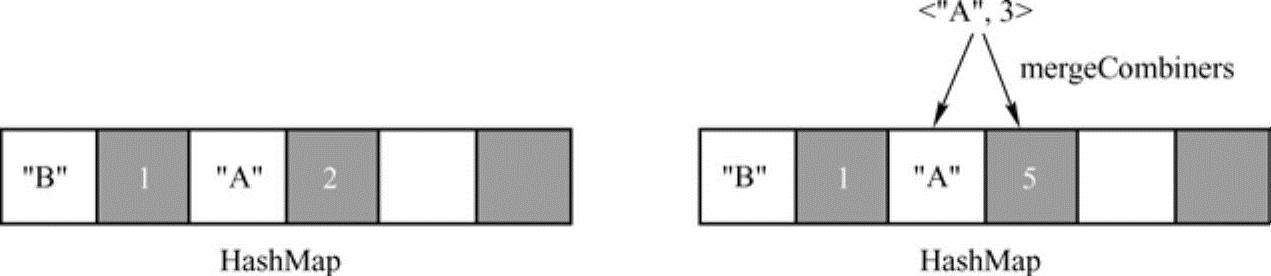
图8-5 执行mergeCombiners前后的哈希表
到此为止,数据已经被成功地聚合和计算了,当然在实际的过程中需要考虑的问题还很多,例如哈希表冲突解决、大小分配、内存限制等。
接下来,思考下Spark与MR机制中的聚合-计算过程的区别。首先,Spark的聚合-计算过程不需要进行任何排序,这意味Spark节省了排序所消耗的大量时间,代价是最后得到的分区内部数据是无序的;再者,Spark的聚合-计算过程是同步进行的,聚合完毕,结果也计算出来,而Hadoop需要等聚合完成之后,才能开始数据的计算过程;最后,Spark将所有的计算操作都限制在了createCombiner、mergeValue以及mergeCombiners之内,在灵活性之上显然要弱于Hadoop,例如,Spark很难通过一次聚合-计算过程求得平均数。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。