



哈希分析器的实现简单,运行速度快,但其本身有一明显的缺点:由于不关心键值的分布情况,其散列到不同分区的概率会因数据而异,个别情况下会导致一部分分区分配到的数据多,一部分则比较少。范围分区器则在一定程度上避免这个问题,范围分区器争取将所有的分区尽可能分配得到相同多的数据,并且所有分区内数据的上界是有序的。使用范围分区器进行分区的一个示例如6-9图所示。
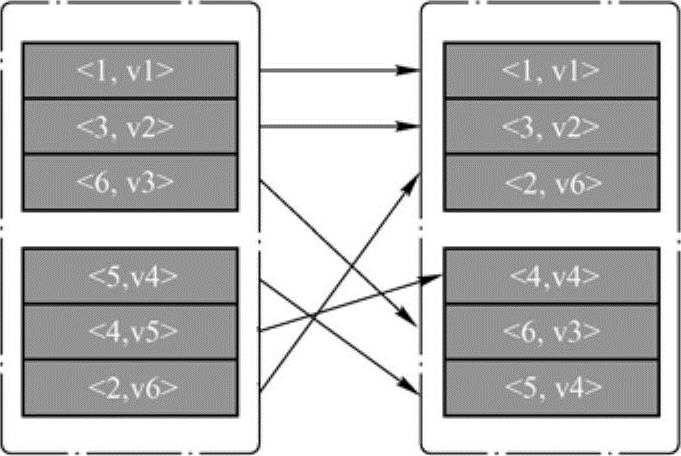
图6-9 范围分区器的一个例子
范围分区器的原理与Apache Hadoop上的TeraSort算法有些类似,范围分区器希望能够将所有键值划分成几个数据块(数目等于子RDD的分区个数),找出每个数据块的边界,每个数据块边界范围内,数据的个数应该是基本相等的,根据边界可以将键值对记录指派给特定的分区。这时候就需要考虑两个问题:一个是如何确定数据块的边界,一个是如何快速确定某个键值对记录属于哪个数据块(分区)。
1.确定边界
对于第一个问题,范围分区器给的方法与TeraSort算法一致,即采样。范围分区器对父RDD中的所有分区进行采样并对采样的结果进行排序,然后按照权重,将其划分成N个数据块,找出每个数据块的上限与下限。(https://www.xing528.com)
在采样算法上,范围分区器采用的是鱼塘采样法(Reservoir Sampling)。该方法能够从一个元素数量为n的集合S中,抽取出k个样本。其中,n是一个很大,或者未知的值。受条件限制,不能把数据全部放到内存中,而该算法则能保证每个样本抽取的概率是一致的。
具体关于确定边界算法的细节,读者可以参考RangePartitioner类中rangeBounds方法、sketch方法以及determineBounds方法的相关实现。
2.快速定位
对于第二个问题,范围分区器给的方法是使用二分查找法。若边界个数少于或等于128,则分区器直接采用穷举法,从头扫描,找到键值所落在的数据块,从而确定分区编号;若边界个数大于128,则对边界进行二分查找,判断当前键值是大于等于或者小于中间的边界值,根据情况继续查找左右两侧的边界值,直到分区刚好落在中间位置。
具体关于快速定位算法的细节,读者可以参考RangePartitioner类中getPartition方法的实现。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。