



在上一节中看到,在RDD中,可以通过计算链(Computing Chain)来计算某个RDD分区内的数据,分区是并行计算的基本单位,因此喜欢思考的读者可能会产生这么一种想法:能否把RDD每个分区内数据的计算当成一个并行任务,每个并行任务包含一个计算链,将一个计算链交付给一个CPU核心去执行,集群中的CPU核心一起把RDD内的所有分区计算出来。答案是可以,这得益于RDD内部分区的数据依赖相互之间并不会干扰,而Spark也是这么做的,但在实现过程中,仍有很多实际问题需要去考虑。下面进一步观察窄依赖、Shuffle依赖在做并行计算时候的异同点。
先来看图6-7左侧的依赖图,依赖图中所有的依赖关系都是窄依赖(包括一对一依赖和范围依赖),可以看到,不仅计算链是独立不干扰的(所以可以并行计算),所有计算链内的每个分区单元的计算工作也不会发生重复,如6-7右侧的图所示。这意味着除非执行了持久化操作,否则计算过程中产生的中间数据没有必要保留——因为当前分区的数据只会给计算链中的下一个分区使用,而不用专门保留给其他计算链使用。
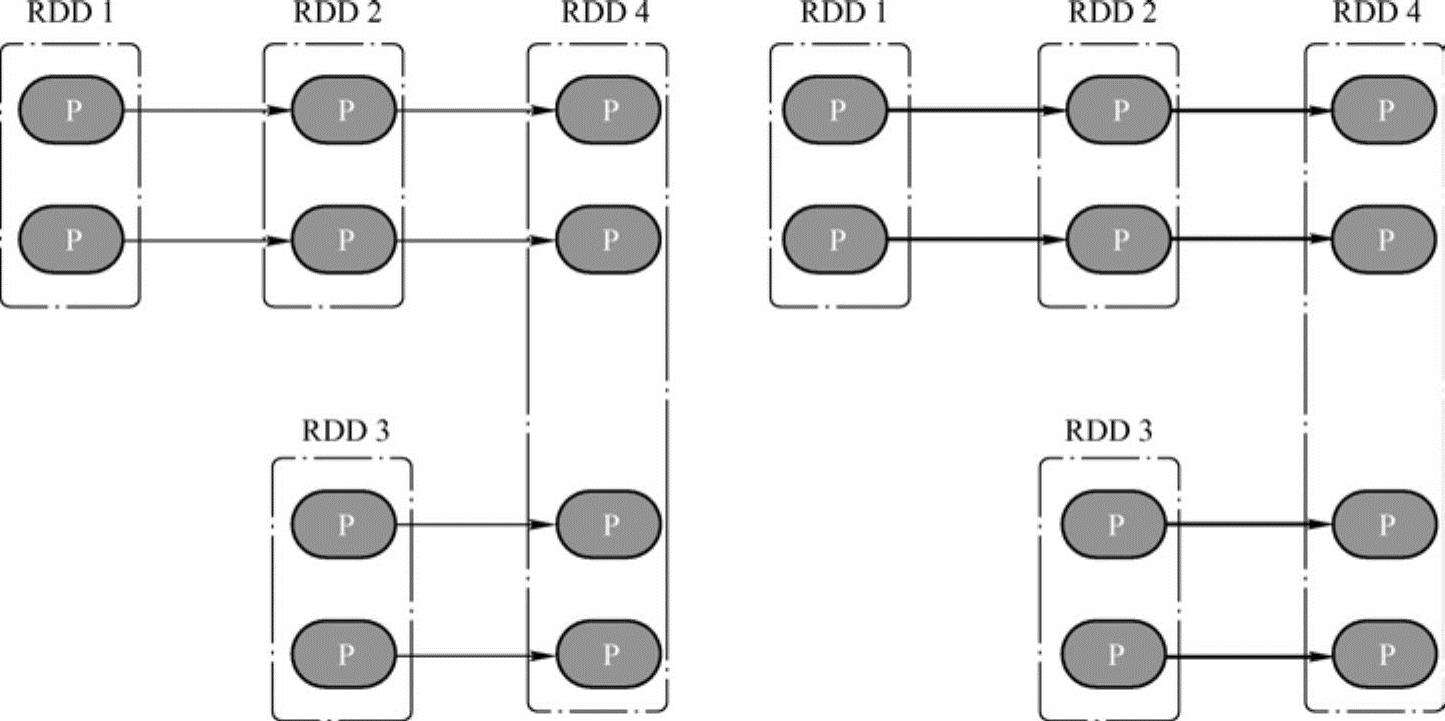
图6-7 窄依赖中的计算链
再来观察Shuffle依赖的计算链,如图6-8左侧所示的图中,既有窄依赖,又有Shuffle依赖,由于Shuffle依赖中,子RDD一个分区的数据依赖于父RDD内所有分区的数据,当想计算末RDD中一个分区的数据时,Shuffle依赖处需要把父RDD所有分区的数据计算出来,如6-8右侧图所示——而这些数据,在计算末RDD另外一个分区的数据时候,同样会被用到。如果做到计算链的并行计算的话,这就意味着,要么Shuffle依赖处父RDD的数据在每次需要使用的时候都重复计算一遍,要么想办法把父RDD数据保存起来,提供给其余分区的数据计算使用。(https://www.xing528.com)
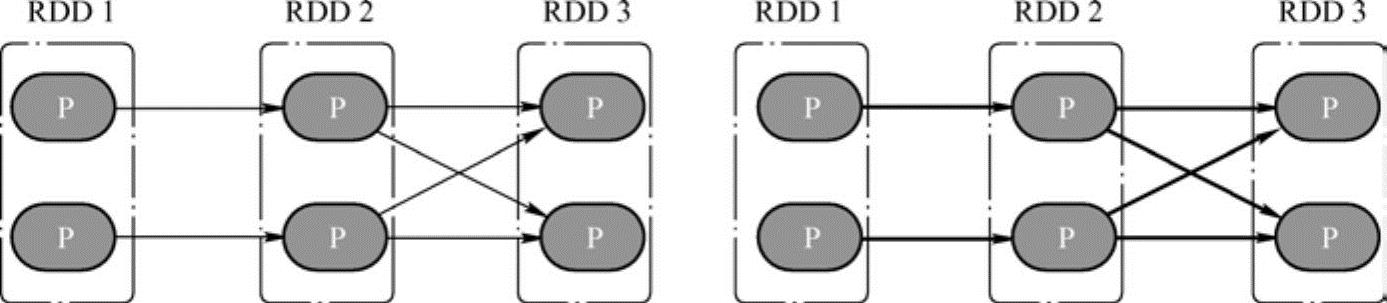
图6-8 Shuffle依赖中的计算链
Spark采用的是第二种办法,但保存数据的方法可能与读者想象中的会有所不同,Spark把计算链从Shuffle依赖处断开,划分成不同的阶段(Stage),阶段之间存在依赖关系(其实就是Shuffle依赖),从而可以构建一张不同阶段之间的有向无环图(DAG)。有关DAG的内容会在第7章中细述。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。