



【摘要】:聚类是一个无监督学习[5]的方法,其的意图在于基于某种相似性概念将数据实体分成不同的子集。MLLib支持多种聚类算法,我们将在本节重点介绍K-means算法,这是将数据点划分为预期簇个数的最常用聚类算法之一。表4-17 K-means算法的参数列表中的代码可在spark-shell中执行。在示例中,我们将首先导入和解析输入数据,之后使用KMeans对象将各数据点分到两个类簇中。可通过增加k值来降低该误差,事实上,当k的取值理想时,WSSSE图中将会有一个“低谷点”。
聚类是一个无监督学习[5]的方法,其的意图在于基于某种相似性概念将数据实体分成不同的子集。聚类常用于探索式分析或作为多层级监督学习管道中的一个组件(这其中每个簇都对应训练了不同的分类器和回归模型)。
MLlib支持下面5个模型。
● K-means。
● Gaussian mixture。
● Power iteration clustering(PIC)。
● Latent Dirichlet allocation(LDA)。
● Streaming k-means。(https://www.xing528.com)
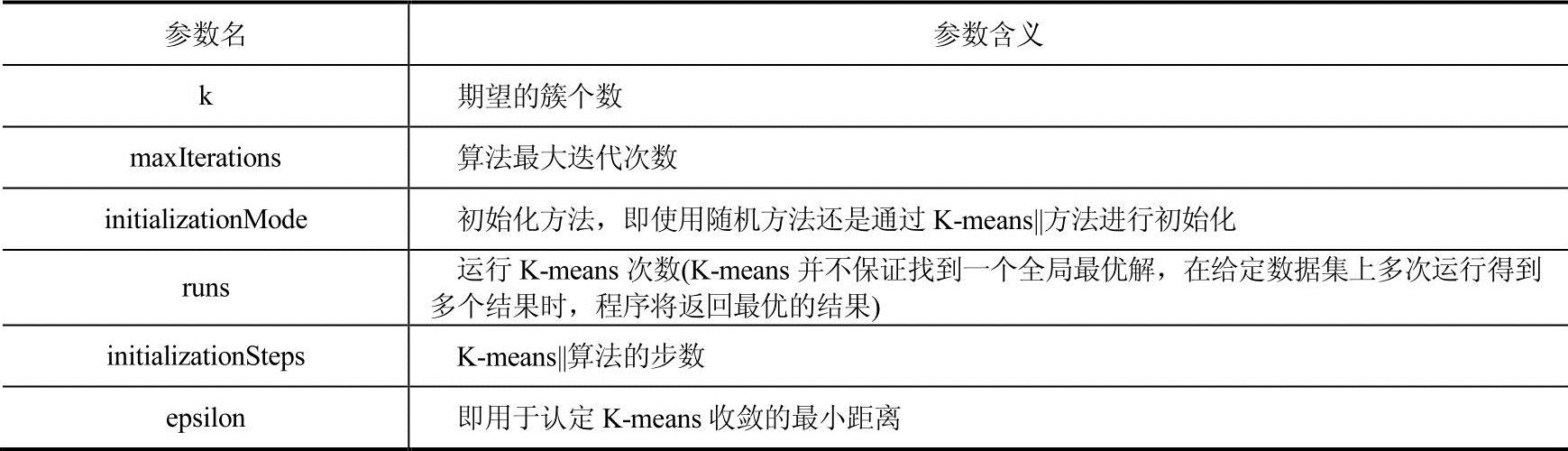
MLLib支持多种聚类算法,我们将在本节重点介绍K-means算法,这是将数据点划分为预期簇个数的最常用聚类算法之一。MLLib实现了K-means++的并行化的演变版本 K-means||。该算法在MLLib中实现的参数如表4-17所示。
表4-17 K-means算法的参数列表
【例4-63】中的代码可在spark-shell中执行。在示例中,我们将首先导入和解析输入数据,之后使用KMeans对象将各数据点分到两个类簇中。期望得到的类簇个数将作为参数传给算法,然后计算集内均方差总和。可通过增加k值来降低该误差,事实上,当k的取值理想时,WSSSE图中将会有一个“低谷点”。
【例4-63】K-means算法应用模型示例。

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。