



协同过滤常常被用于分辨某位特定顾客可能感兴趣的东西,这些结论来自于对其他相似顾客对哪些产品感兴趣的分析。协同过滤以其出色的速度和健壮性,在全球互联网领域快速发展。与传统文本过滤相比,协同过滤有下列优点:第一是能够过滤难以进行机器自动基于内容分析的信息,如艺术品、音乐;第二是能够基于一些复杂的、难以表达的概念(信息质量、品位)进行过滤;第三是推荐的新颖性。正因为如此,协同过滤在商业应用上也取得了不错的成绩。Amazon,CDNow,MovieFinder都采用了协同过滤的技术来提高服务质量。
1.协同过滤算法
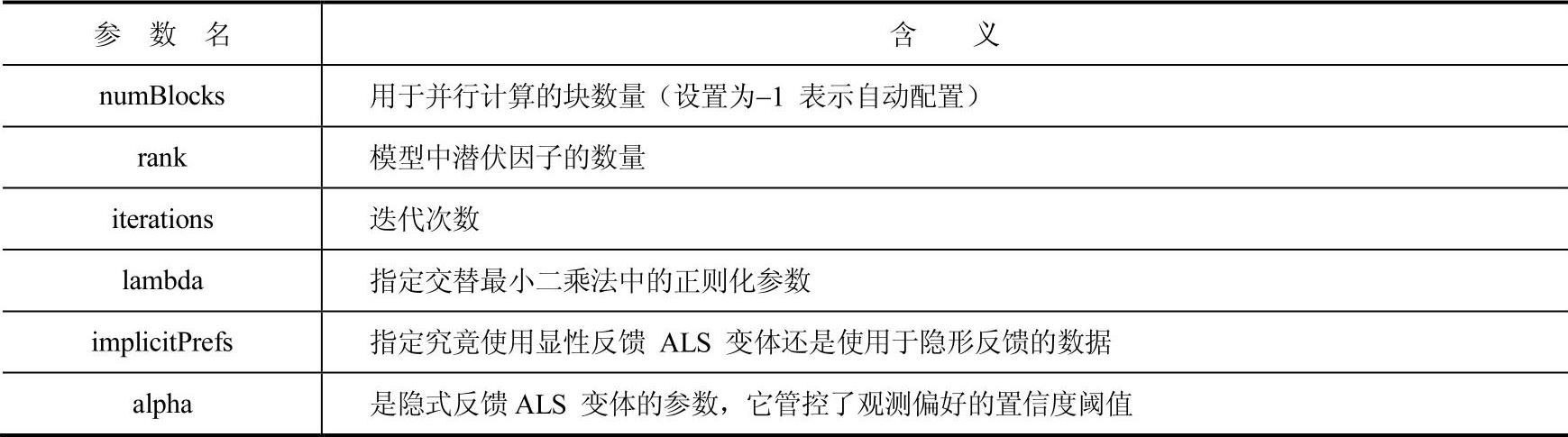
协同过滤常用来实现推荐系统。该技术力图填充用户与物品关联矩阵中缺失的实体。MLlib支持基于模型的协同过滤,在这里,用户和产品称之为是潜伏因子的一个子集,其用途是预测缺失实体。MLlib使用交替最小二乘法(ALS)来学习这些潜伏因子。MLlib中协同过滤参数如表4-16所示。
表4-16 协同过滤参数含义
2.显式反馈与隐式反馈
标准处理方式下,协同过滤把用户与物品关联矩阵中的实体当作用户对物品的显性喜好,基于此来发现矩阵因子。但在现实世界里,更常见的情形是隐式反馈(如浏览,点击,购买,点赞,分享等)。在MLlib中处理这类数据的方法请参见“Collaborative Filtering for Implicit Feedback Datasets[4]”。该方法并不直接拟合评级矩阵,而是将数据视为“是否喜好”和“置信度水平”的组合。对用户的喜好来说,评级与置信度水平相关,而不是用户对物品的显式评级值。然后模型尽可能地寻找潜伏因子,以用来预测用户对物品喜好。
3.对正则化参数的调整
从MLlib版本1.1开始,在解决每一最小二乘法问题时,使用更新用户因子时用户生成的评级数量或更新产品因子时产品得到的产品评级数量,来调整正则化参数lambda。这种方法称之为“ALS-WR”。它降低lambda对数据集大小的相关性。也因于此,能够把从抽样数据子集中学习到的最佳参数应用到数据全集。
4.示例程序(https://www.xing528.com)
在下面的【例4-62】中,将加载评级数据。每行数据由一个用户,一个产品和一个评级组成。假定评级信息是显性的,所以使用默认的ALS.train方法来训练。最后计算评级预测的均方误差来评估推荐模型。
【例4-62】ALS算法模型示例。


如果评级矩阵来源于另一个的信息来源(如从其他信号推断),则可以使用trainImplicit方法得到更好的结果,代码片段如下。
val alpha=0.01
val lambda=0.01
val model=ALS.trainImplicit(ratings,rank,numIterations,lambda,alpha)
为了运行上面的应用程序,一定要在构建文件时包含spark-mllib作为一个依赖。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。