



Spark SQL通过DataFrame类提供的接口从而实现对不同数据源操作的支持。DataFrame既可以像普通RDD一样使用,也可以被注册为一张临时表。将DataFrame注册为一张表,且能在这个表的数据之上运行SQL查询,那么一个DataFrame就类似于传统关系型数据库中的一张表。DataFrame可以从现有的RDD、Parquet文件、JSON数据集或者从HiveQL的结果数据中创建。下面主要介绍将数据加载到DataFrame的几种方法。
1.RDDs与DataFrames的互操作
Spark SQL提供两种不同的方法来将现有的RDDs转变成DataFrames。第一种方法是使用反射机制(reflection)来推断包含特定类型对象的RDD的格式。这种基于反射机制的方法使得代码更简洁,不过需要在编写Apache Spark应用之前就知道RDD的格式。
Scala接口支持自动将含有样本类(Case Classes)的RDD转变为DataFrame。样本类定义了表的Schema。样本类中的参数名通过反射被读取,然后转变为列的名称。样本类也可以嵌套或包含复杂类型,如序列或数组。这种RDD可以隐式转换为DataFrame,然后注册为一张表,这张表可以在后续的SQL语句中使用。
【例4-2】RDD与DataFrame的隐式转换。


创建DataFrames的第二种方法是通过一个编程接口,允许构建一种格式,然后将其应用到现有的RDD。虽然这种方法比较烦琐,但可以在不知道RDD的列和它们的类型时构建DataFrames。
当样本类不能提前确定时(例如当记录的结构由字符串或文本数据集编码而成,它在解析时,字段将会对不同的用户有不同的投影结果),DataFrame可以由以下3个步骤创建。
1)从原始RDD创建一个含有Rows的RDD。
2)创建一个由StructType表示的模式,它与第1)步中创建的RDD的Row结构相一致。
3)通过调用SQLContext中createDataFrame方法,将模式应用到含有Rows的RDD。
【例4-3】RDD与DataFrame的编程接口转换。

2.Parquet文件
Parquet文件是一种列式存储格式的文件,被很多数据处理系统支持。下面将会展示Spark SQL如何支持读取和写入Parquet文件,并实现可自动保留原始数据格式的功能。
(1)以编程方式加载数据
如【例4-4】所示,主要介绍了如何将RDD数据集转换为DataFrame格式,以便支持SQL查询。
【例4-4】以编程方式加载数据。

(2)配置
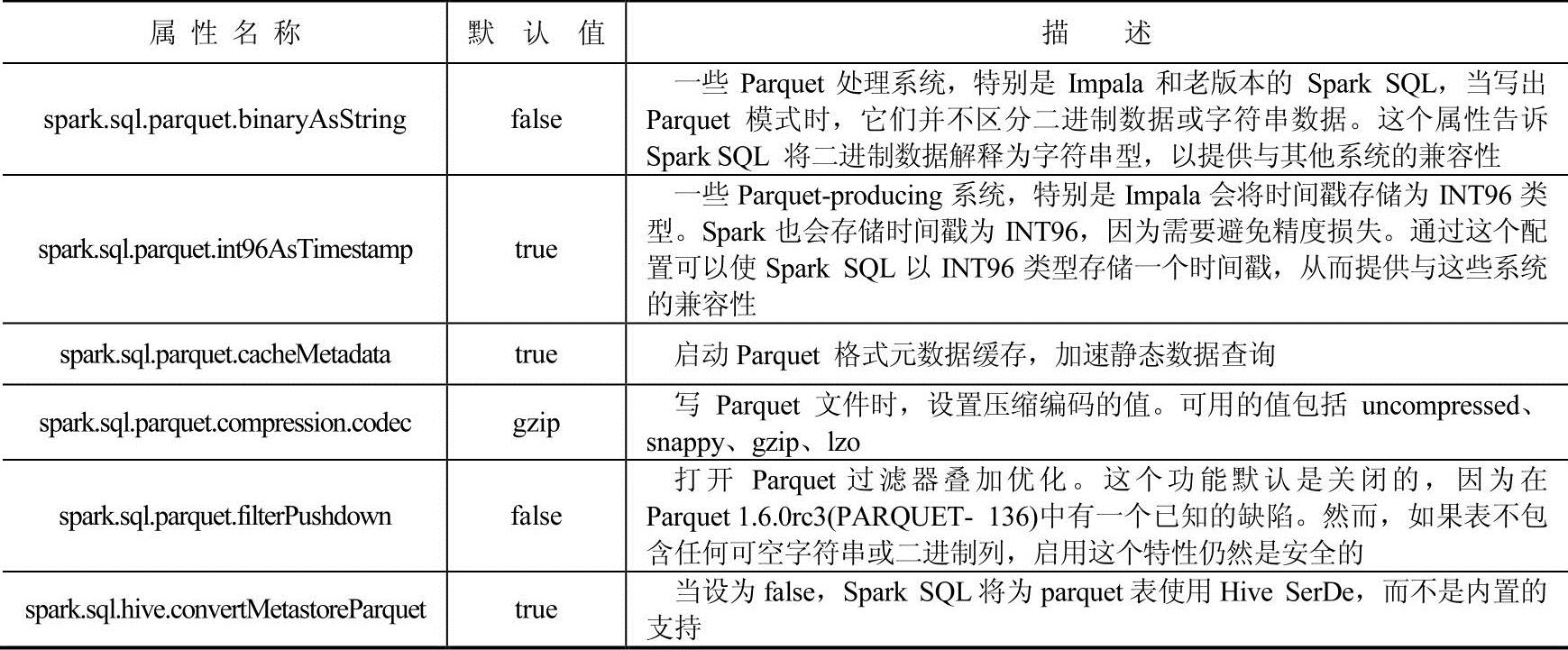
可以用SQLContext中setConf方法或使用SQL运行“SET key=value”命令,来完成Parquet配置。Parquet配置属性如表4-1所示。
表4-1 Parquet配置属性表
(3)分区发现
表分区在系统中是一种常见的优化方法,比如在Hive数据仓库中就有所应用。在一个分区表中,数据通常存储在不同的目录中,分区列值编码在每个分区目录的路径中。Parquet数据源能够自动发现和推断分区信息。例如,可以将以前使用的人口数据存储到一个分区表中,在分区表中可以使用如【例4-5】所示的目录结构,性别和国家作为分区列。
【例4-5】目录结构
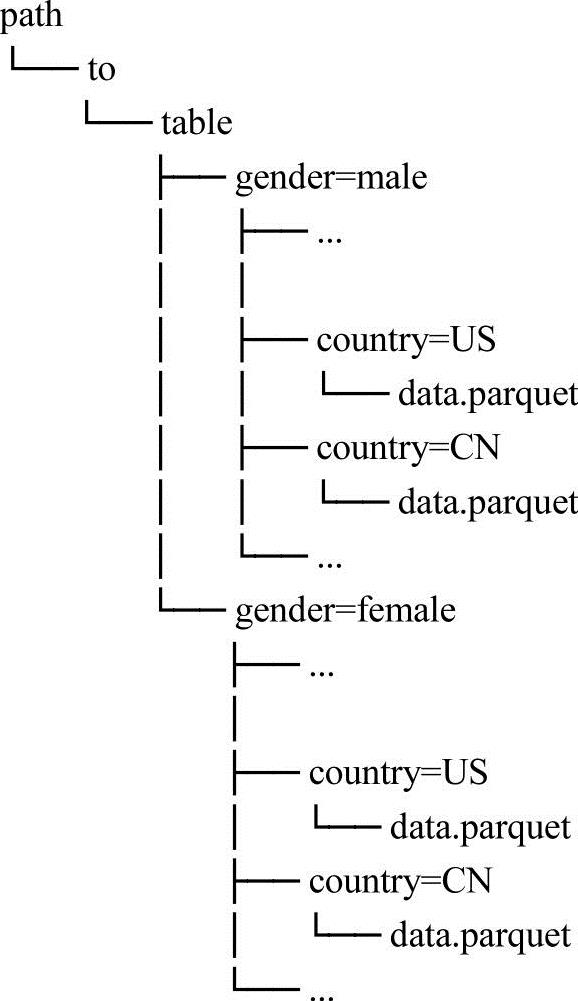
在Spark SQL中使用SQLContext.read.load或者SQLContext.read.parquet方法将自动从路径分区path/to/table中提取信息。【例4-5】中的信息就可以被自动提取为DataFrame数据类型,具体表现如下。
root
|--name:string(nullable=true)
|--age:long(nullable=true)
|--gender:string(nullable=true)
|--country:string(nullable=true)
值得注意的是,分区的列的数据类型是自动推断的,目前为止,仅支持数字数据类型和字符串类型。(https://www.xing528.com)
(4)模式合并
像ProtocolBuffer、Avro、Thrift、Parquet数据源都支持模式演化。用户可以从一个简单的模式开始,逐步添加更多的列的模式。通过这种方式,用户可能得到一个来自多个不同Parquet文件但最终都相互兼容的模式。Parquet数据源能够自动检测这种情况下的这些文件并且将模式合并,具体见【例4-6】。
【例4-6】模式合并


3.JSON数据集
Spark SQL可以自动推断出一个JSON数据集的结构,并将其加载为DataFrame。可以利用SQLContext提供的SQLContext.read.json()方法来将JSON文件或者字符串类型的RDD转换为DataFrame。
需要注意的是这里的JSON文件不是一般意义的JSON文件,在这个JSON文件中每一行必须包括独立的、有效的JSON对象,因此常规的多行JSON文件通常会加载失败。
【例4-7】加载JSON数据集。

4.Hive表
Spark SQL还支持读取和写入存储在Apache Hive中的数据。然而,由于Hive有大量的依赖关系,它并不包括在默认的Apache Spark组件中。为了使用Hive,必须在构建Spark的时候加入“-Phive”和“-Phive-thriftserver”,这个命令构建了一个包含Hive的新的集成Jar包。需要注意到Hive的集成Jar包必须存在于所有的工作节点上,因为它们需要访问Hive的序列化和反序列化库,以访问到存储在Hive中的数据。
将hive-site.xml文件放到conf目录下,以完成Hive的配置。
当运行Hive时,必须构造一个HiveContext,它继承于SQLContext,并增加了对在MetaStore中查询表的支持,以及使用HiveQL编写查询语句的支持。即使没有一个现存的Hive部署,仍然可以创建一个HiveContext。当不使用hive-site.xml的配置时,上下文自动在当前目录中创建metastore_db和warehouse。示例代码如【例4-8】所示。
【例4-8】使用Hive。
val sqlContext=new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql("CREATE TABLE IF NOT EXISTS src(key INT,value STRING)")
sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
//HiveQL语法的查询语句
sqlContext.sql("FROM src SELECT key,value").collect().foreach(println)
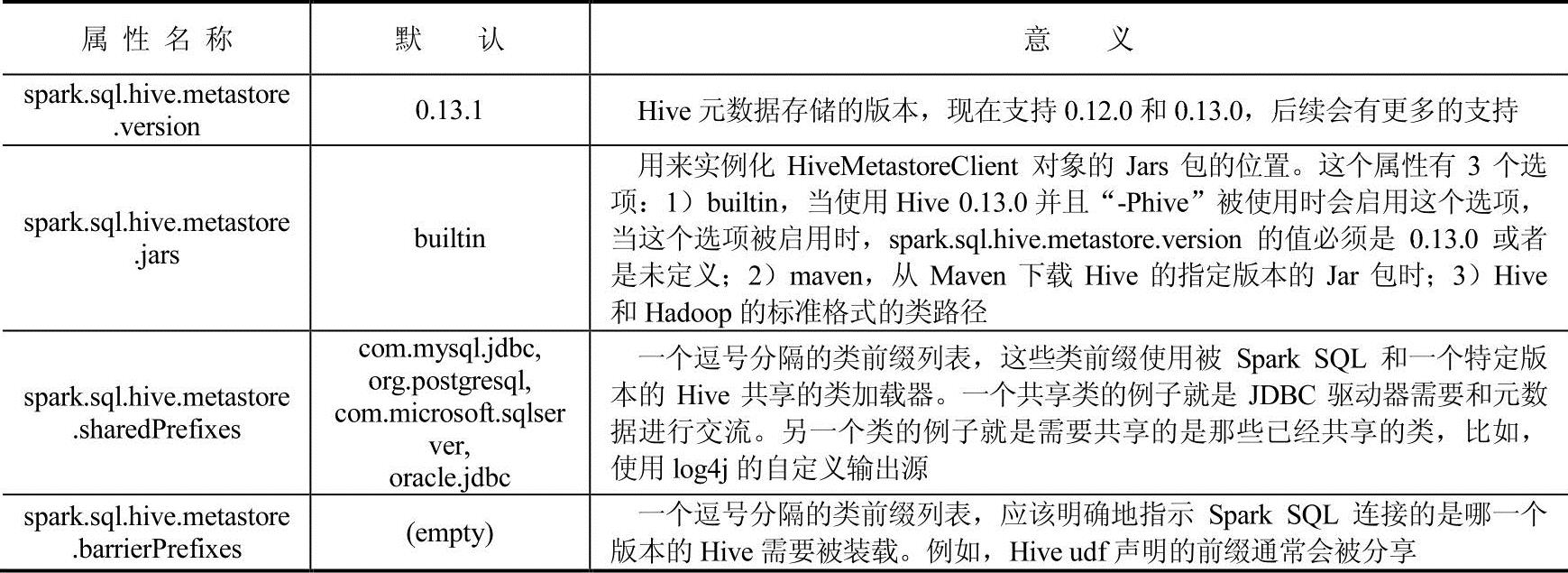
Spark SQL可以直接与Hive进行交互,使Spark SQL可以访问元数据表。从Spark1.4开始,使用二进制编译的Spark SQL可以使用SQL查询不同版本的Hive表,在使用之前还需要进行一些配置,配置表如表4-2所示。
表4-2 配置表
5.其他数据库
Spark SQL提供了JDBC以连接其他数据库读取数据,这个功能优于使用jdbcRDD获取数据。JDBC连接数据库获取的数据是以DataFrame的类型作为返回值,这样数据就能够很方便地被Spark SQL进行处理并能够很好地与其他数据源的数据结合。需要说明的是这里的JDBC不同于使程序执行Spark SQL的查询的Spark SQL JDBC Server。
使用JDBC来连接数据库,首先需要一个特定的JDBC驱动类,比如通过Spark Shell连接Postgres数据库,需要执行下面的操作。
SPARK_CLASSPATH=postgresql-9.3-1102-jdbc41.jar bin/spark-shell
远程数据库中的数据表可以使用数据源API加载为DataFrame或者Spark SQL的临时表的形式,在加载过程中支持的选项如表4-3所示。
表4-3 JDBC加载属性表

下面的代码片段给出了具体的JDBC连接语句。
val jdbcDF=sqlContext.load("jdbc",Map(
"url"->"jdbc:postgresql:dbserver",
"dbtable"->"schema.tablename"))
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。