



【摘要】:Spark的编程模型如图3-1所示。图3-1 Spark编程模型开发人员在编写Spark应用的时候,需要提供一个包含main函数的驱动程序作为程序的入口,开发人员根据自己的需求,在main函数中调用Spark提供的数据操纵接口,利用集群对数据执行并行操作。Spark为开发人员提供了两类抽象接口。
Spark的编程模型如图3-1所示。
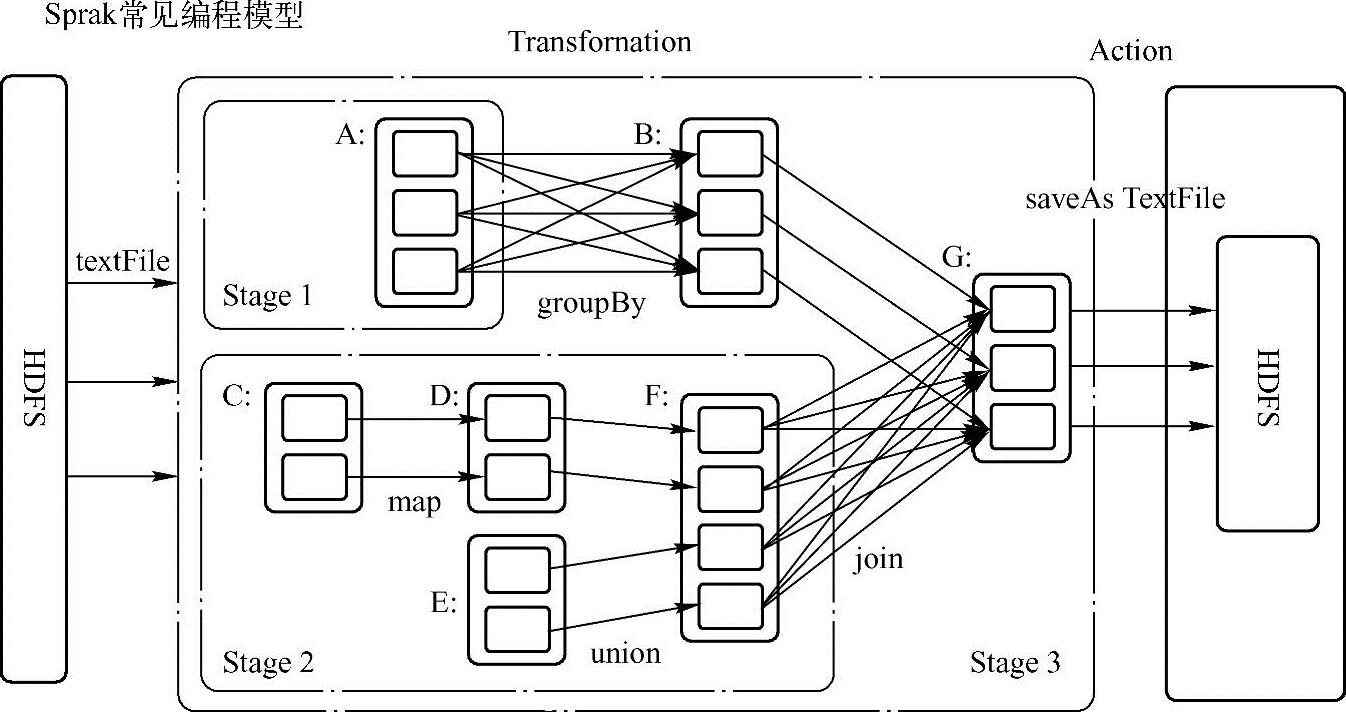
图3-1 Spark编程模型(https://www.xing528.com)
开发人员在编写Spark应用的时候,需要提供一个包含main函数的驱动程序作为程序的入口,开发人员根据自己的需求,在main函数中调用Spark提供的数据操纵接口,利用集群对数据执行并行操作。
Spark为开发人员提供了两类抽象接口。第一类抽象接口是弹性分布式数据集RDD,顾名思义,RDD是对数据集的抽象封装,开发人员可以通过RDD提供的开发接口来访问和操纵数据集合,而无须了解数据的存储介质(内存或磁盘)、文件系统(本地文件系统、HDFS或Tachyon)、存储节点(本地或远程节点)等诸多实现细节;第二类抽象是共享变量(SharedVariables),通常情况下,一个应用程序在运行的时候会被划分成分布在不同执行节点之上的多个任务,从而提高运算的速度,每个任务都会有一份独立的程序变量拷贝,彼此之间互不干扰,然而在某些情况下任务之间需要相互共享变量,ApacheSpark提供了两类共享变量,它们分别是广播变量(Broadcast Variable)和累加器(Accumulators)。第3.3节会介绍RDD的基本概念和RDD提供的编程接口,并在后面详细解读接口的源码实现,从而加深对RDD的理解,此外在第3.4节中将介绍两类共享变量的使用方法。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。