



Spark支持3种集群资源管理器,分别是Standalone、YARN和Mesos,其中Standalone为Spark自带,无须用户再额外安装和部署其他的资源管理器。本章会以Standalone为例,介绍如何搭建和管理一个Spark集群,对YARN和Mesos感兴趣的读者可以参考官方提供的文档。
1.SSH配置
为了实现无缝工作,安装完毕SSH的客户端与服务端之后,需要允许master(主)节点能够无须输入密码即可登录集群内的所有机器,我们可以通过创建公钥和私钥对来实现。在master节点上,执行命令“ssh-keygen-tdsa”生成SSH私钥,如果生成过程需要输入,按<Enter>键即可,执行结果如图2-6所示。

图2-6 生成SSH私钥
接下来使用ssh-copy-id命令将私钥加入到所有节点(包括master节点本身)的.ssh/authorized_keys文件中,例如可以使用命令“ssh-copy-id spark@slave1”实现slave1节点上Spark用户的无密码登录,执行结果如图2-7所示。

图2-7 实现无密码登录
2.Spark配置文件
在master节点上,进入Spark安装目录下的conf目录,使用如下命令得到slaves和spark-env.sh文件。
$cp slaves.template slaves
$cp spark-env.sh.template spark-env.sh
编辑spark-env.sh文件,在文件末尾加入“export JAVA_HOME=/path/to/java”行,其中读者需要把“/path/to/java”替换成自己实际的Java安装目录。继续编辑slaves文件,加入所有工作节点的主机名,每个节点占据一行。
3.复制Spark目录(https://www.xing528.com)
接下来把配置好的Spark目录复制到所有节点上,目录所存放的位置在所有节点上都必须是一致的。可以使用scp命令来完成此项工作,如下命令为一条示例,用于将maste节点上的spark-1.4.1-bin-hadoop2.6目录复制到slave1节点的/home/spark/spark目录下,读者可以根据实际情况来修改。如果节点数目比较多的话,建议读者编写一个Shell脚本来完成此项任务。
$scp-r spark-1.4.1-bin-hadoop2.6 spark@slave1:/home/spark/spark/
4.运行与关闭Standalone集群
回到Spark的安装目录,执行命令“sbin/start-all”即可启动集群上的所有节点。集群启动完毕后,打开浏览器,访问http://masternode:8080,其中masternode需要替换成自己master节点的真实IP或者主机名,可以看到Web监控界面如图2-8所示,该页面显示集群中所有节点的信息,以及曾经运行、正在运行的应用程序的相关情况。
切换到Spark的安装目录,执行命令“sbin/stop-all.sh”即可关闭集群,Spark会自动关闭正在运行的所有节点。
5.运行Example程序
执行如下的spark-submit命令可以向搭建好的Spark集群提交之前曾经运行过的Example程序,其中masternode需要替换成读者自己master节点的主机名。spark-submit命令的使用会在下一节中具体介绍。
$spark-submit--master spark://masternode:7077 examples/src/main/python/pi.py
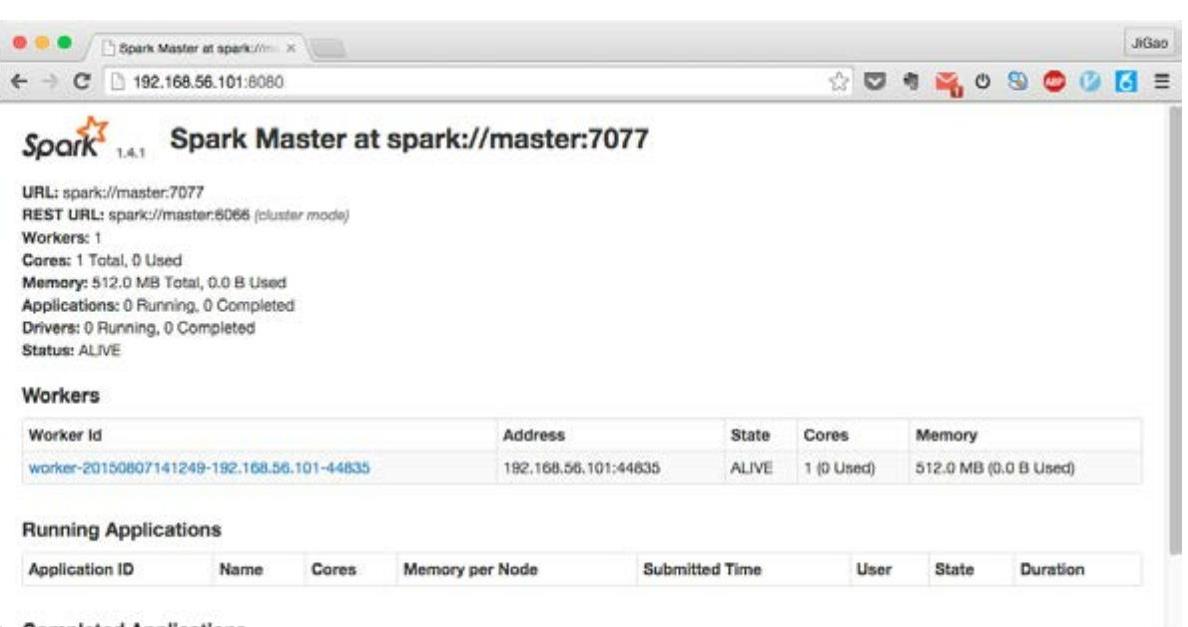
图2-8 Web监控界面
刷新Spark Web界面,可以看到程序的运行情况,如图2-9所示。
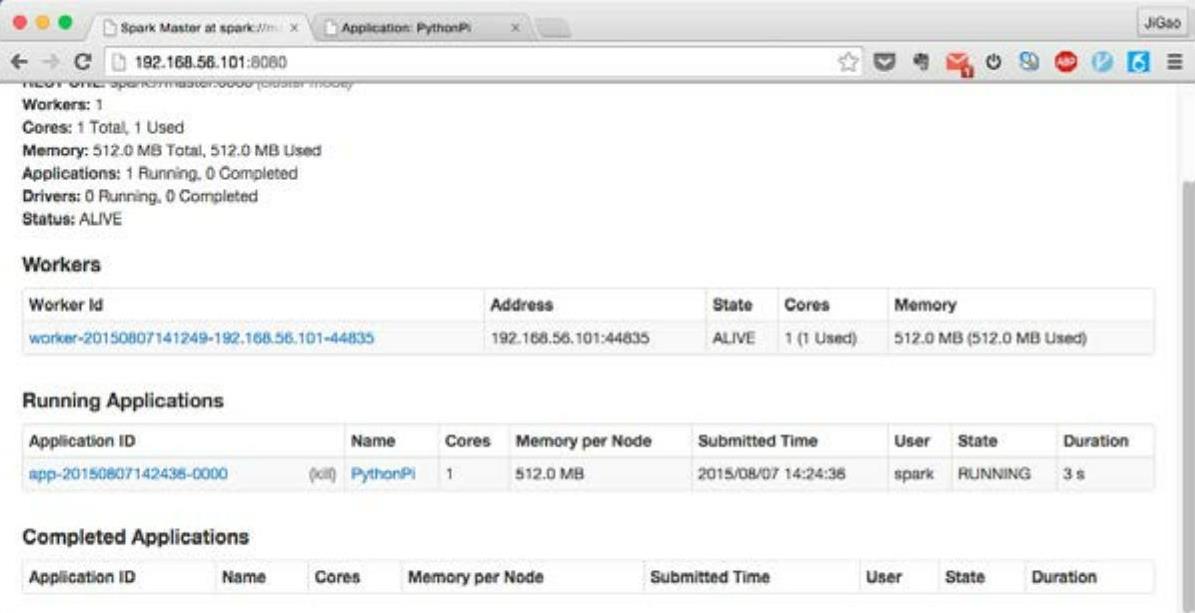
图2-9 程序运行情况界面
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。