



DSP广泛采用旨在减少指令执行时间的流水线操作,进一步增强了处理器的处理能力。流水线操作是指各条指令以机器周期为单位,相差一个机器周期而连续并行工作的情况。流水线操作的原理是:将指令分成几个子操作,每个子操作由不同的操作阶段完成。这样,每隔一个机器周期,每个操作阶段就可以进入一条新指令。因此在同一个机器周期内,在不同的操作阶段可以处理多条指令,相当于并行执行了多条指令。
TMS320C54x有一个6段的指令流水线(流水线操作是由6个操作阶段组成的),如图3-33所示。流水线的6个段彼此是独立的,允许指令重叠执行。在任何一个机器周期内,可以有1~6条不同的指令在同时工作,每条指令可在不同的周期内工作在不同的操作阶段。

图3-33 6段指令流水线示意图
流水线的6个操作阶段分别为预取指(P)、取指(F)、译码(D)、访问(A)、读数(R)和执行(X)。每个流水线操作阶段各占用一个机器周期。各操作阶段的功能如下:
1)程序预取指(P):将下一条指令的地址放在程序地址总线(PAB)上。
2)程序取指(F):从程序总线(PB)上取指令字,并将该指令字放入指令寄存器(IR)中。
3)译码(D):将指令寄存器(IR)中的内容译码,确定要访问存储器的类型以及数据地址产生单元(DAGEN)和CPU的控制时序。
4)访问(A):数据地址产生单元(DAGEN)在数据地址总线(DAB)输出要读的操作数的地址。如果还有第二个操作数,则在另一个数据地址总线CAB上输出相应的地址。同时更新间接寻址模式下的辅助寄存器(ARx)和堆栈指针(SP)。
5)读数(R):从数据总线DB和CB上读取操作数,完成操作数的读取。同时,操作数的写入开始。如果需要写数据,则写数据的地址放在数据写地址总线(EAB)上。对存储器映射寄存器而言,数据是从存储器中读取,写数据时通过DB写入选择的存储器映射寄存器。
6)执行(X):在这个阶段完成指令的执行,并将数据放在数据写总线(EB)上完成操作数的写入。
流水线的前两个阶段(预取指和取指)是指令取指的系列动作。前面一个机器周期,一条新指令的地址被加载;紧接着的一个机器周期,读出这条指令。如果是多字指令,就需要几个机器周期才能将一条指令读出来。在流水线的第三个阶段(译码)是对所取得的指令进行译码,产生执行指令所需要的一系列控制信号。其后的两级阶段(访问和读数)是操作数读取的系列动作。如果指令需要,就在访问阶段加载一个或两个操作数的地址,紧接着读出一个或两个操作数。在读数时,还可以加载一个写操作数的地址,以便在流水线的最后一个阶段(执行)将数据送到数据存储空间。
由上可见,TMS320C54x流水线中的存储器存取操作都分两步来进行。第一步,存储器地址被送上一条地址总线;第二步,相应的数据总线从存储器地址读取数据或是向存储器地址写入数据。图3-34给出了TMS320C54x流水线存储器操作的各种情况。这里假设图中所有的存储器操作都是单周期、单字长指令访问片内双访问存储器(DARAM)的情况。

图3-34 TMS320C54x流水线中的存储器存取操作
a)取指令字(1个周期)b)执行单操作数读取指令(例如:LDAR1,A;1个周期)c)执行双操作数读取指令(例如:
MAC*AR2+,*AR3,A或DLD*AR2,A;1个周期)d)执行单操作数写回指令(例如:STHA,*AR1;1个周期)e)执行双操作数写回指令(例如:DSTA,*AR1;2个周期)f)执行单操作数读和写指令(例如:STA,*AR1||LD*AR3,B;1个周期)
下面以跳转语句为例说明流水线的工作情况。假设有下面一段程序,左边第一列为地址,左边第二列为指令代码,最后一列为注释:

那么流水线的工作图如图3-35所示,为便于分析,流水线图用一组彼此错开的行来描述,其中每一行表示一个指令字通过流水线的各个段的情况。每一行的左边都有一个标注,这个标注可以是一条指令、一个操作数、一条多周期指令或者是流水线刷新,最上面一行的数字代表单指令的周期数;每个方格代表流水线在不同阶段的相关动作。阴影部分表示一条指令的全部操作。
由图可知:
周期1:用跳转指令的地址a1加载PAB。
周期2和3:取出跳转指令的两个指令字(取指)。(https://www.xing528.com)
周期4和5:i3和i4指令取指。由于这两条指令处在跳转指令的后面,虽然已经取指,但不能进入译码段,且最终被丢弃。跳转指令进入译码段,用新的值(b1)加载PAB。指令i3和i4只是起到流水线刷新的作用。
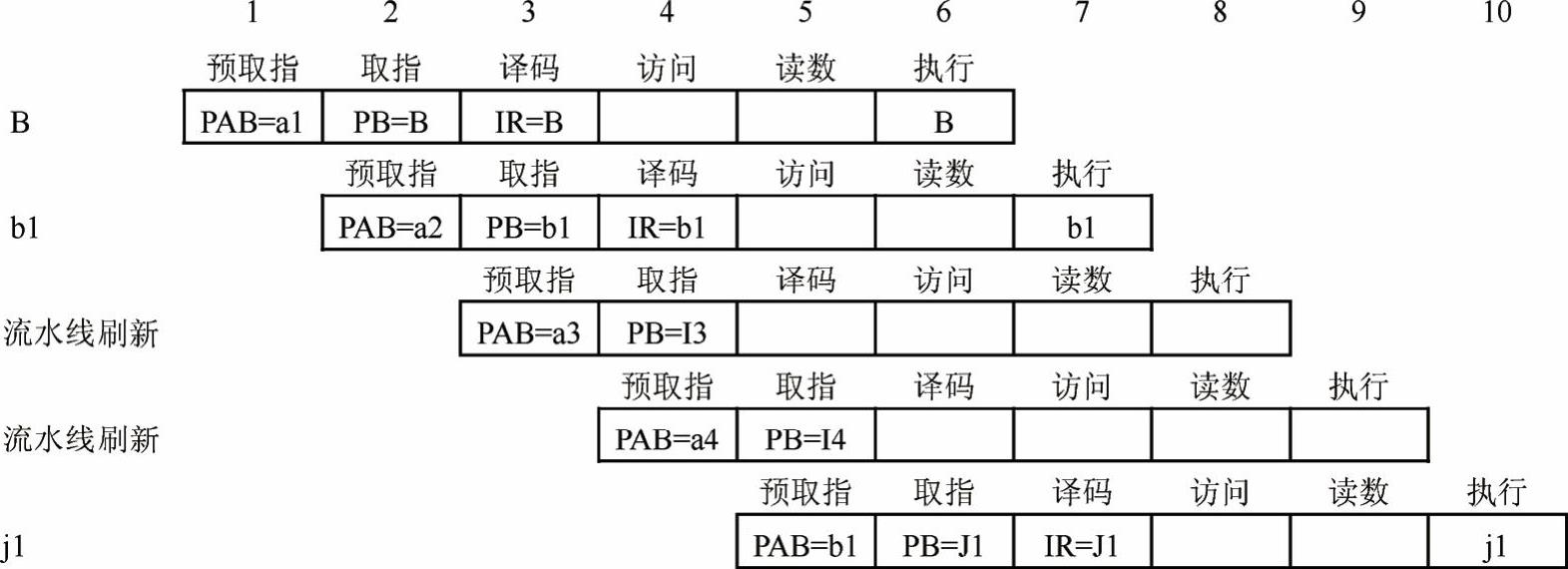
图3-35 跳转指令的流水线图
周期6和7:跳转指令的两个指令字进入执行阶段,同时在周期6中,j1指令取指。
周期8和9:由于i3和i4指令是不允许执行的,所以这两个周期中,跳转指令的流水线执行阶段无任何动作,这两个周期被消耗掉。所有跳转指令需要4个周期(周期6~9)才能执行完成。
周期10:执行j1指令。
TMS320C54x的流水线允许多条指令同时访问CPU资源,提高了指令执行的效率。但是由于CPU的资源毕竟是有限的,当某个CPU资源(如AR0辅助寄存器)同时被一个以上流水线阶段所占用时,就有可能会产生流水线冲突。其中的一些流水线冲突可以由CPU自动插入延迟来解决,例如下面语句:
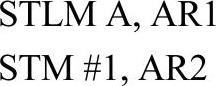
其中第一条指令在流水线的执行阶段更新AR1,而第二条指令又试图在读数阶段更新AR2,因此就与第一条指令产生了流水线冲突。此时CPU将更新AR2的操作自动延时1个周期,从而避免了冲突。
但是还有一部分的冲突不能由CPU自动解决,而必须由程序员来解决。此时程序员可以采用调整程序语句的次序或在两条有冲突的指令中间插入一定数量的NOP指令(即不执行任何操作的指令)来避免冲突,也可以只用那些不产生任何流水线冲突的指令或在某些寄存器被访问之前观察必要的延迟来避免冲突。例如下面语句:

其中,第三条指令使用了与第二条指令相同的辅助寄存器(AR3)来进行间接寻址。运行时,第二条指令在流水线的读数阶段写入AR3,而此时第三条指令处于流水线的访问阶段。由于第二条指令还没有更新AR3,所以此时AR3间接寻址的单元是错误的,这就产生了流水线冲突。解决方法一是在第二条指令和第三条指令之间插入一个NOP指令:

解决方法二是重新调整程序语句,使得第二条指令和第三条指令之间有一个延迟:
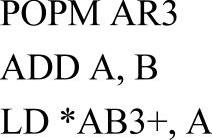
有些存储器映射寄存器,如果在流水线中同时对它们访问,就有可能发生CPU不能自动解决的流水线冲突。这些存储器映射寄存器包括辅助寄存器(AR0~AR7);循环缓冲区长度寄存器(BK);堆栈指针(SP);暂存器(T);处理器工作方式状态寄存器(PMST);状态寄存器(ST0和ST1);块重复计数器(BRC)和存储器映射累加器(AG、AH、AL、BG、BH、BL)。
因此在使用这些寄存器时,应选择合适的指令,并注意该指令对后续指令的要求,避免发生流水线冲突;在访问某个寄存器之前还要注意该寄存器是否满足必需的延迟时间。
图3-36说明了可能发生流水线冲突的地方和不会发生冲突的地方。

图3-36 流水线冲突情况分析
由图3-36可以看出,如果TMS320C54x系统的源程序是用C语言编写的,经过编译生成的代码是没有流水线冲突问题的。如果是汇编语言程序,凡是CALU操作,或者早在初始化期间就对MMR进行设置,也不会发生流水线冲突。因此,大多数TMS320C54x程序是不需要对其流水线冲突问题进行特别关注的,只有某些MMR写操作才需要注意。基于此,本节不再对流水线作过多阐述,关于冲突的详细解决方法可参考TIDSP技术手册“TMS320C54x DSP Refernce Set Volume1:CPU and Peripherals”。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。