



自从亚马逊公司公布了协同过滤算法后,在推荐系统领域,它就占据了很重要的地位。不像传统的内容推荐,协同过滤不需要考虑物品的属性问题、用户的行为和行业问题等,只需要建立用户与物品的关联关系即可,可以物品之间更多的内在关系,类似于经典的啤酒与尿不湿的营销案例。所以,讲到推荐必须要首先分享协同过滤。对于协同过滤及其经典算法ALS(交替最小二乘法),在介绍MLlib的四大算法里面我们已经讲过,这里我们直接使用ALS算法来根据某用户对电影的打分进行电影的推荐。
1.数据准备
这里我们使用的是MoiveLens的数据集,下载地址是:http://www.grouplens.org/data-sets/movielens/。它提供了100KB到100多MB大小的数据,我们这里选择1MB大小的数据。对下载的数据解压之后,会出现很多文件,我们需要使用ratings.dat、users.dat和mov-ies.dat文件中的数据。详细的数据说明可以参见README.txt文件。
(1)ratings.dat文件是用户对电影的评分数据,数据格式为:UserID(用户ID)::Mov-ieID(电影ID)::Rating(评分)::Timestamp(时间戳),样本数据如下所示。


(2)users.dat文件是用户的个人信息,数据格式是:UserID(用户ID)::Gender(性别)::Age(年龄)::Occupation(职业)::Zip-code(邮政编码),样本数据如下所示。

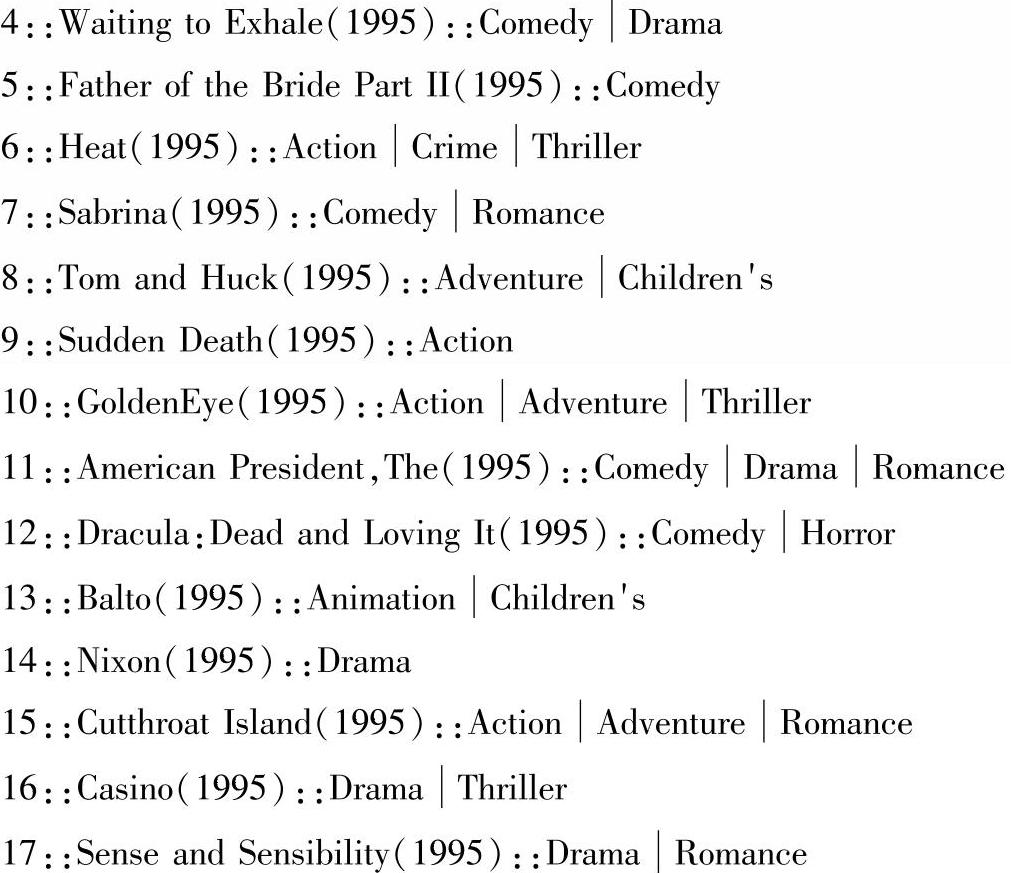
(3)movies.dat文件是电影的详细信息,数据格式为:MovieID(电影ID)::Title(电影名)::Genres(电影类型),样本数据如下:
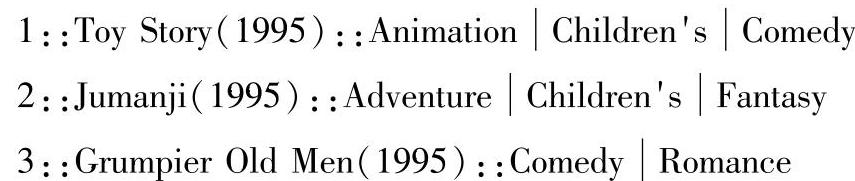
2.实现的功能
这里有10万条用户对电影的评分,从1分到5分,1分表示差劲,5分表示非常好看根据用户对电影的喜好,给用户推荐可能感兴趣的电影。
3.实现思路
(1)装载由评分由评分器生成的用户评分数据。
(2)装载样本评分数据,其中最后一列Timestamp取除10的余数作为key,Rating为值,即(Int,Rating)。这里的Rating是MLlib中实现的一个case class。
(3)训练不同参数下的模型,并在校验集中验证,获取最佳参数下的模型。
(4)用最佳模型预测测试集的评分,并计算和实际评分之间的均方根误差。
(5)推荐前十部最感兴趣的电影,注意要剔除用户已经评分的电影。
4.代码实现
(1)评分器生成用户评分的代码,如下所示。


(2)电影推荐系统的代码,如下所示。


 (https://www.xing528.com)
(https://www.xing528.com)


5.运行
此次我们选择把在IntelliJ IDEA中建立的关于MovieLensALS协同过滤工程进行打包,然后再在Spark集群中进行运行。在IntelliJ IDEA中构建项目以及Spark集群的启动我们在前面的章节已经讲过,这里不再具体演示。
(1)首先我们在/home//IdeaProjects/machine-learning/目录下会有一个名称为personal-Ratings.txt.template的文件,在用评分器进行评分的时候会在这个文件的基础之上生成一个名称为personalRatings.txt的评过分数的文件。该文件里面的内容如下:

(2)在Spark集群运行关于MovieLensALS的工程之前,我们先在Ubuntu的shell命令终端执行以下代码来调用用户评分器文件(rateMovies),然后生成一个用户进行评分的文件。
(3)执行上述bin/rateMovies命令后在Shell终端会输出“Please rate the following movie(1-5(best),or O if not seen):”,这时陆续点击回车键输出每部电影,并对其进行评分。(从1分到5分,1分表示差劲,5分表示非常好看),如图9-9所示。
图9-9 用评分器对电影进行评分
(4)评完11部电影的分数后,会在/home//IdeaProjects/machine-learning/目录下生成一个名称为personalRatings.txt的用户评分文件,如图9-10所示。
图9-10 用户评分文件personalRatings.txt
(5)最后就是在shell命令终端用spark-submit工具来提交任务了,首先要进入Spark的$HOME目录下,执行以下命令:

在这里我们简单介绍一下submit的参数列表的含义:
1)Master我们选择的是Standalone运行模式下主机名为SparkMaster的Master,主机名就是用户自己配置的Master结点的主机名;
2)mlmovie.MovieLensALS mlmovie.jar指的是要运行的含有Main方法的打过包的jar文件;
3)file:///home//IdeaProjects/machine-learning/movielens/medium是要加载的样本数据的目录,目录下面有我们要加载的ratings.dat和movies.dat文件;
4)/home//IdeaProjects/machine-learning/personalRatings.txt就是用户通过评分器生成的评过分的文件。
(6)运行结果。从如图9-11的运行结果中我们看到加载进来的样本数据有6040位用户对3706部电影做了1000209个评分;有602252条评分数据用来做Training(训练),198919条评分数据做validation(评估),199049条数据用来做test(测试);在对8种情况的参数组合进行最佳数据模型的测试后,得出最好的数据模型是参数rank=8、lambda=10.0、numIter=20的模型;最终向使用评分器对提供的11部电影进行过评分的用户推荐了10部电影。
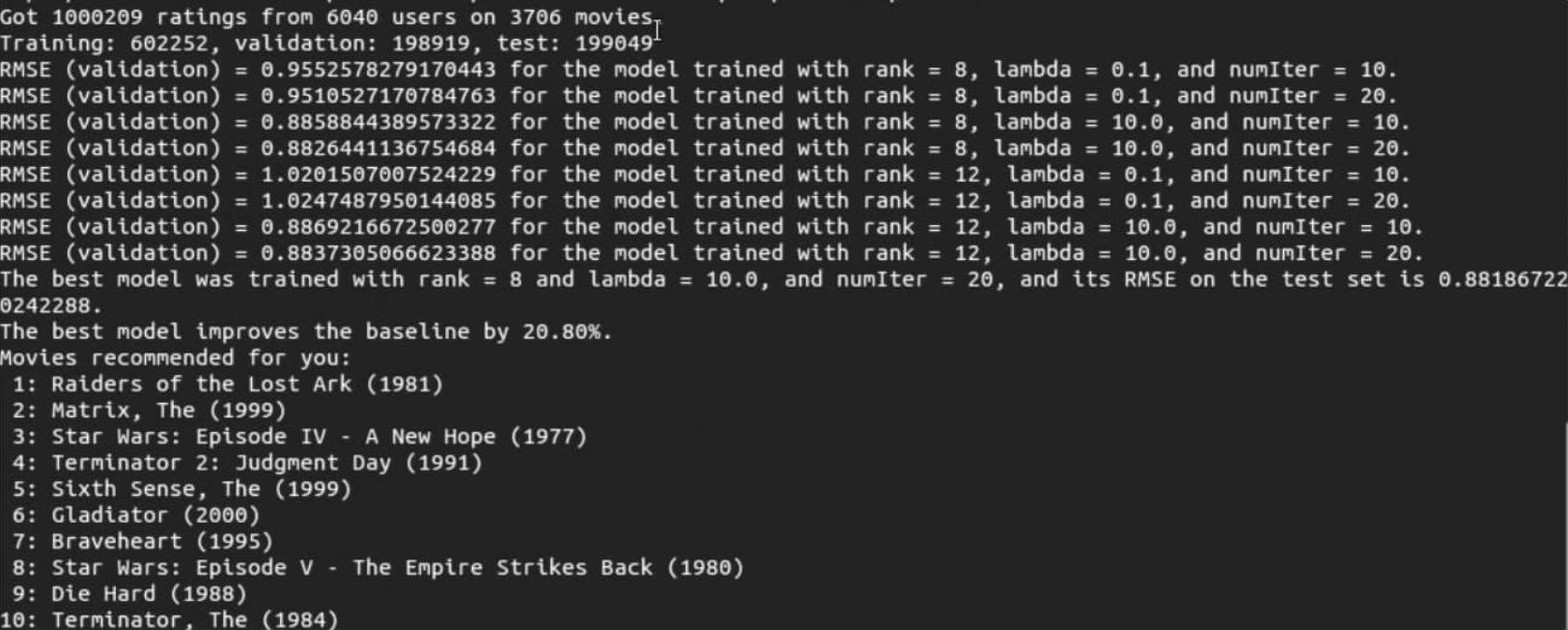
图9-11 电影推荐系统的运行结果
至此,协同过滤算法的案例实战操作已经讲完,这里最重要的就是object MovieLensALS中的代码实现了,希望读者多看几遍这部分的代码,并在自己搭建的Spark系统下亲自运行操作。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。