



1.K-Means算法解析
在前面介绍MLlib的算法时,我们已经简单介绍过K-Means算法,K-Means是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。给定数据样本集Sample和应该划分的类数K,对样本数据Sample进行聚类,最终形成K个聚类,其相似的度量是某条数据与中心点的“距离”(距离可分为绝对值距离、欧式距离、闵可夫斯基距离、切比雪夫距离和马氏距离。这里所说的距离是欧式距离,欧氏距离(Euclidean distance)也称欧几里得距离,它是一个通常采用的距离定义,它是在m维空间中两个点之间的真实距离)。
对于K-Means算法,它的执行过程可分为以下4步:
(1)选择K个点作为初始中心;
(2)将每个点指派到最近的中心,形成K个簇(聚类);
(3)重新计算每个簇的中心;
(4)重复(2)~(3),直至中心不再发生变化。
2.K-Means算法实例操作
(1)数据准备。在kmeans_data.txt文件中,我们准备了以下数据:

(2)实现思路如下。
1)屏蔽不必要的日志显示在终端上。
2)设置运行环境。
3)装载kmeans_data.txt数据集。
4)将数据集聚类(聚成两个类),进行20次迭代计算,形成数据模型。
5)在控制台打印数据模型的两个中心点。
6)使用误差平方之和来评估数据模型。
7)使用模型测试单点数据。
8)交叉评估1,只返回结果。
9)交叉评估2,返回数据集和结果。
(3)代码实例如下。
 (https://www.xing528.com)
(https://www.xing528.com)

(4)运行结果
1)加载进来的数据首先会把每行向量化赋值给parsedData,然后会调用Kmeans类的train()方法把向量化数据迭代20此并分成2个聚类。最终在控制台打印数据模型的两个中心点(两个中心点都是向量),从图9-4的运行结果可以看到中心点分别为向量[0.10000000000000002,0.10000000000000002,0.10000000000000002]和向量[9.1,9.1,9.1]。
调用model.computeCost(parsedData)对形成的数据模型model使用误差平方之和来评估,可以看到评估结果的值是0.11999999999994547。
2)使用数据模型进行单点数据的测试,这里的单点数据指的是一个向量,这里提供了三个单点向量(向量[0.2,0.2,0.2],向量[0.25,0.25,0.25],向量[8,8,8]),分别对其进行测试。
图9-5是运行结果的截图。这里需要注意的是由于每次求出中心点并打印在控制台上时显示的顺序不一样(当然聚类中心点的索引是从0开始递增的),所以接下来显示单点数据所属有的中心点时会参考前面求出的中心点的顺序。从图9-5中可以看出向量[0.2,0.2,0.2]属于中心点索引为1的向量[0.10000000000000002,0.10000000000000002,0.10000000000000002],向量[0.25,0.25,0.25]进行数据模型预测后也属于中心点索引为l的向量[0.10000000000000002.0.10000000000000002,0.10000000000000002,而向量[8,8,8]属于中心点索引为o的向量[9.1,9.1,9.1]。
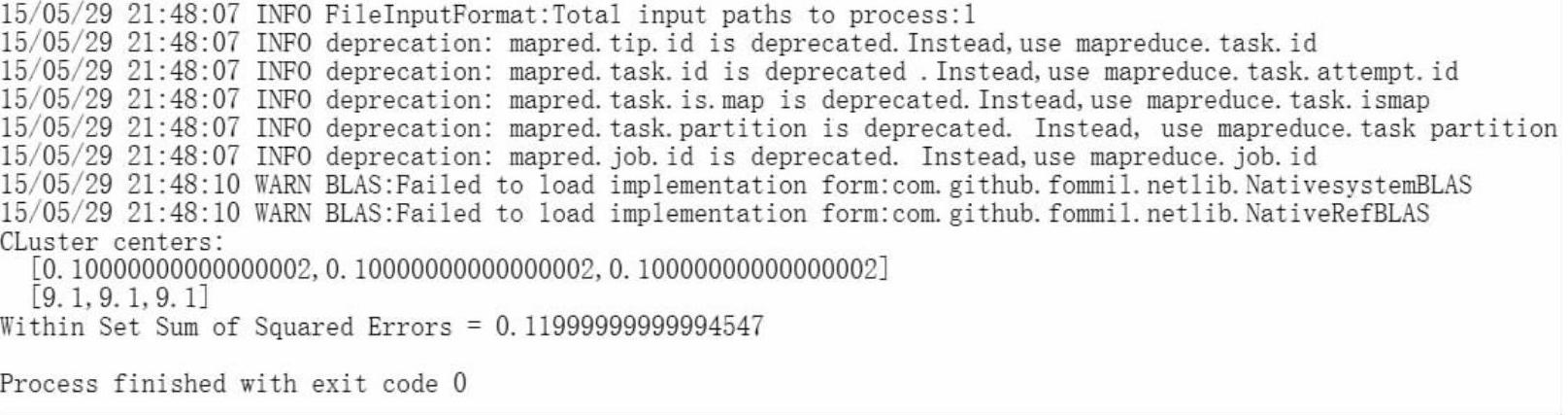
图9-4 打印数据模型的中心点

图9-5 使用数据模型进行单点数据测试
3)对于交叉评估1,需要使用模型进行预测的数据testdata是通过对从本地文件目录加载进来的数据data进行map操作,在map操作内部的函数会把data中的每行数据转换为一个向量。接着调用model.predict(testdata),并把预测的结果resultl保存到本地的文件目录下(如图9-6)。打开resultl文件可以看到结果只显示了每个向量所属的聚类索引号,我们并不知道到底是哪个向量属于哪个聚类,因此交叉评估l的结果不是我们先要看到的。
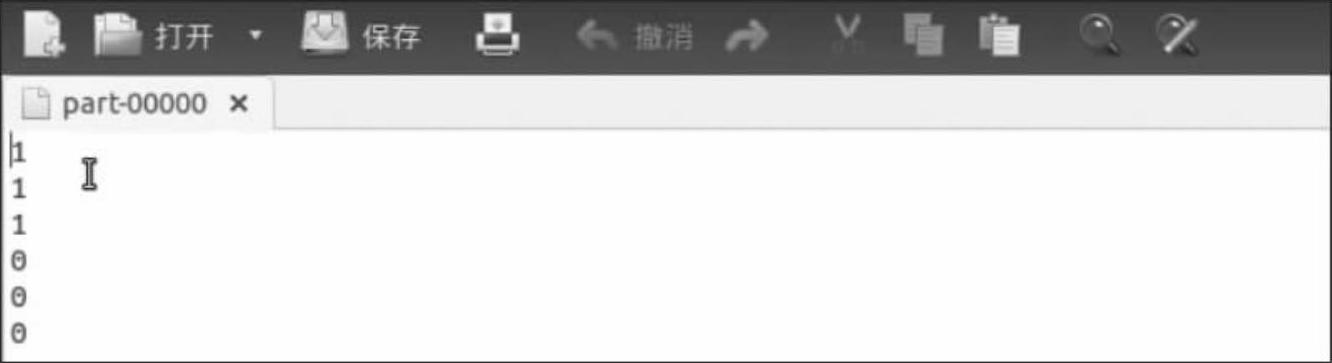
图9-6 交叉评估1的运行结果
4)接着进行交叉评估2的操作,在交叉评估2的实现代码中,最关键的实现是在数据集data调用的map操作内的函数实现,在map操作的函数中,会对每行数据line进行向量。
化并直接使用数据模型对向量进行测试(预测),这样最终的操作结果是返回数据集和它所属的中心点的索引值(如图9-7所示)。

图9-7 交叉评估2的运行结果
当然这时候在控制台显示的聚类顺序如图9-8所示,这样我们很清楚地知道向量[0,0,0属于索引值为0的向量[0.10000000000000002,0.10000000000000002,0.10000000000000002],向量[9.0,9.0,9.0]属于中心点索引值为1的向量[9.1,9.1,9.1]。

图9-8 控制台显示的聚类顺序
到此,K-Means算法解析和实践的讲解暂时告一段落,考虑到K-Means算法在生产环境中的重要性,还是希望大家彻底掌握它。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。