



从图9-3中可以看出,MLlib的架构主要包含三个部分:
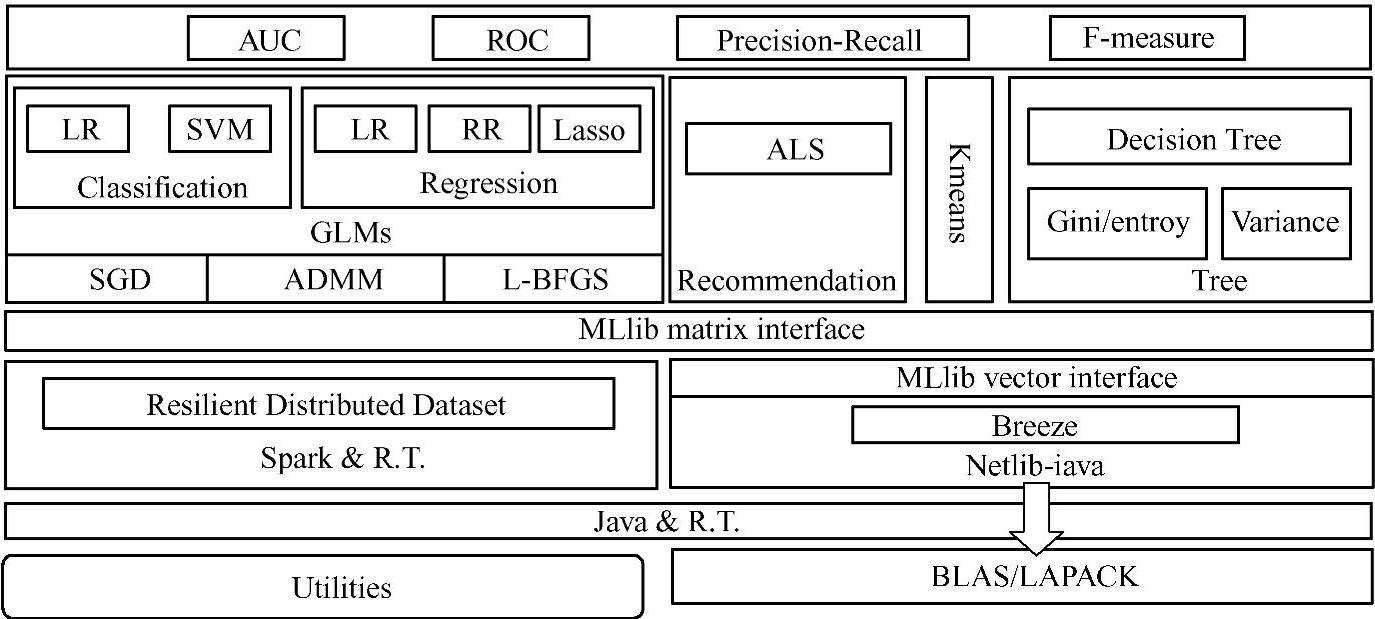
图9-3 MLlib的架构图
1.底层基础
MLlib的底层基础包括Spark的运行库、矩阵库和向量库等。具体来讲包括:
(1)BLAS/LAPACK:BLAS,全称Basic Linear Algebra Subprograms,即基础线性代数子程序库,里面拥有大量已经编写好的关于线性代数运算的程序。LAPACK,其名为Linear Algebra PACKage的缩写,是一以Fortran编程语言写就,用于数值计算的函式集。LAPACK提供了丰富的工具函式,可用于诸如解多元线性方程式、线性系统方程组的最小平方解、计算特征向量、用于计算矩阵QR分解的Householder转换、以及奇异值分解等问题。
(2)Java&R.T.:指的是Java Runtime,也就是俗称的JVM虚拟机。
(3)Spark&R.T.:指的是Spark Runtime。
(4)Resilinet Distributed Dataset:就是RDD了,它是Spark的核心抽象。
(5)Brezze:Brezze是伯克利大学发行的用scala编写的矩阵计算库,Breeze库是scalanlp中三大支柱性项目之一,breeze库提供了vector/matrix的实现以及相应计算的接口。(https://www.xing528.com)
(6)Netlib-java:Netlib-java相当于一层JNI接口,使Breeze可以调用底层的BLAS LAPACK库。
(7)MLlib vector interface:MLlib vector interface是MLlib中自带向量的接口。
(8)MLlib matrix interface:在RDD和MLlib vector interface之上封装了一层MLlib matrix interface,从这里可以看出MLlib的vector是本地的vector,而MLlib的matrix既可以是本地的matrix又可以是分布式的matrix。
2.算法库
包含广义线性模型、推荐系统、聚类、决策树和评估的算法等。在MLlib matrix interface之上的就是Spark机器学习算法的多种多样的库,具体来讲,包括:
(1)左侧的Classification,是用来做分类的,它包括LR和SVM两种算法,其中LR(Logistic Regression,逻辑回归)是用来做分类中的逻辑回归,同样我们可以看到非常经典的分类算法SVM(Support Vector Machine,支持向量机)。而Regression是用来做回归迭代计算的,包括LR、RR(Ridge Regression,岭回归)、Lasso(least absolute shrinkage and selec-tion operator)三种算法。Classification和Regress的底层都是GLMs,即广义线性模型,其优化算法有三种,即SGD(Stochastic Gradient Descent,随机梯度下降)、ADMM(Alternating Direction Method of Multipliers)、L-BFGS(Limited-memory BFGS,拟牛顿法的多个变种之一)。
(2)在MLlib算法库中,中间部分是Rcommendation,即推荐算法,这里实现的是ALS(Alternating Least Square)算法。推荐算法右侧是聚类的实现算法Kmeans,在聚类右侧是决策树(Decision Tree)相关的内容,然后在整个架构图的最上面是MLlib中已经实现的对算法评价的方法,例如AUC(Area Under roc Curve)、ROC(Receiver Operating Characteris-tic)、Precision-Recall和F-measure。
3.实用程序
包括数据的验证器、Label的二元和多元的分析器、多种数据生成器和数据加载器等,这些内容在MLlib的util包中。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。