



1.用PageRank算法找出最有影响力的文章
(1)算法设计。PageRank是Google用来标识网页的等级/重要性的一种方法,是Google用来衡量一个网站的好坏的唯一标准。PageRank是Google最核心的算法,目前很多重要的链接分析算法都是在PageRank算法基础上衍生出来的。在揉合了诸如Title标识和Keywords标识等所有其他因素之后,Google通过PageRank来调整结果,使那些更具“等级/重要性”的网页在搜索结果中令网站排名获得提升,从而提高搜索结果的相关性和质量。其级别从0到10级,10级为满分。PR值越高说明该网页越受欢迎(越重要)。PageRank的基本算法如图8-11所示。

图8-11 PageRank的基本算法
我们假设有1、2、3、4共四张网页,PageRank会把每一个网页的权重设置为,例如ID为1的网页指向ID分别为2、3、4这三个网页,则ID为2、3、4的网页则分别获得来自ID为1的网页的1/3的权重,其他类似,这四个网页之间的应用关系构成了一个矩阵,然后该矩阵和PageRank中的向量进行相乘得出新的向量,新的向量继续和矩阵进行相乘,不断的迭代,Google已经证明该迭代过程是收敛的,可以设定具体停止收敛的参数,例如前后迭代的误差小于0.001可以停止收敛,收敛完毕得出的PageRank值就是各个网页的PageRank值。实际应用中PageRank的实现会有多种,开发者可以根据自己的需要进行选择。SparkGraphX在pregel图计算算法引擎中自带了PageRank算法,可以直接应用PageRank相关的处理中。
本案例中的数据是来自经过处理的维基百科的数据,通过ETL(Extract-Transform-Load)把所有含有或者指向“Berkeley”字段的标题文章保留下来,最终形成顶点的文件“graphx-wiki-vertices.txt”和边的文件“graphx-wiki-edges”,顶点文件“graphx-wiki-verti-ces.txt”的格式是文章VertexID和文章标题title的形式,内容如下所示。

边的文件“graphx-wiki-edges”的格式就是源顶点与目标顶点的VertexID的信息,如下所示。

通过PageRank的计算,找出最有价值的、包含“Berkeley”字段标题的文章。
(2)实现代码。代码使用scala实现,如下:


(3)代码分析如下。
1)屏蔽日志:通过调用Java语言中的Logger的两个getLogger()方法创建两个Logger对象,然后调用它的setLevel()方法设置日志消息输出的级别分别是Level.WARN和Lev-el.OFF,在各自的Logger对象中,低于设置的Logger级别的日志信息将被丢弃。
2)设置运行环境:通过val conf=new SparkConf().setAppName("PageRank").setMaster("local[2]")和val sc=new SparkContext(conf)这两行代码来初始化SparkConf和SparkCon-text对象。
3)读取数据:分别调用sc.textFile()方法从/root/Downloads/graphx-wiki目录下读取顶点文件graphx-wiki-vertices.txt和边的文件graphx-wiki-edges.txt。
4)接下来装载顶点和边:把读进来的两个文件进行map()转换操作后生成vertices和edges两个RDD,这样就装载成两个关于顶点和边的RDD。
5)根据装载的顶点和边来构建图:调用val graph=Graph(vertices,edges,"").persist()来构建图,并且在这里要对构建好的图进行一下cache操作,persist()默认的缓存策略就是cache。需要格外注意的是因为在进行PageRank的时候需要进行不断的迭代,所以需要把Graph进行cache缓存操作,在这里使用以StorageLevel.MEMORY_ONLY为参数的persist或则cache都可以,但是不要使用其他类型的StorageLevel(缓存策略),因为使用其他类型的persist会与PageRank内部的cache缓存类型产生冲突。
6)接下来我们调用graph.triplets.take(5).foreach(println(_))来显示五个Triplets的信息到控制台,看一下是不是都具有“Berkeley”这个关键字,如图8-12的运行代码所示,可以发现目标顶点都是含有“Berkeley”关键字的文章。
7)接下来进行PageRank的计算:由于PageRank算法里面的时候使用了cache(),故前面调用persist()方法进行缓存的时候只能使用MEMORY_ONLY。调用val prGraph=graph.pageRank(0.001).cache()这行代码进行PageRank的计算。我们给PageRank传入的参(https://www.xing528.com)

图8-12 获取五个triplet信息的运行代码
数是0.001,也就是说前一次迭代和后一次迭代误差如果小于0.001的时候,我们就结束迭代,从而返回计算出的PageRank值的集合。
8)返回来后的含有PageRank值的顶点的集合因为没有顶点的属性,也就是说没有文章的标题,所以要调用val titleAndPrGraph=graph.outerJoinVertices(prGraph.vertices){(v,title,rank)=>(rank.getOrElse(0.0),title)}这段代码进行连接操作。
9)然后调用titleAndPrGraph.vertices.top(10){Ordering.by((entry:(VertexId,(Double,String)))=>entry._2._1)}.foreach(t=>println(t._2._2+":"+t._2._1))这段代码进行顶点的排序,并获取最有价值的前10名的文章。
10)最后调用sc.stop()关闭SparkContext,在调用SparkContext的stop()方法的时候会完成Spark驱动和任务调度系统中的DAGScheduler和TaskScheduler等内容资源释放和清理等工作。
(4)程序运行过程。程序运行过程截图如图8-13所示。
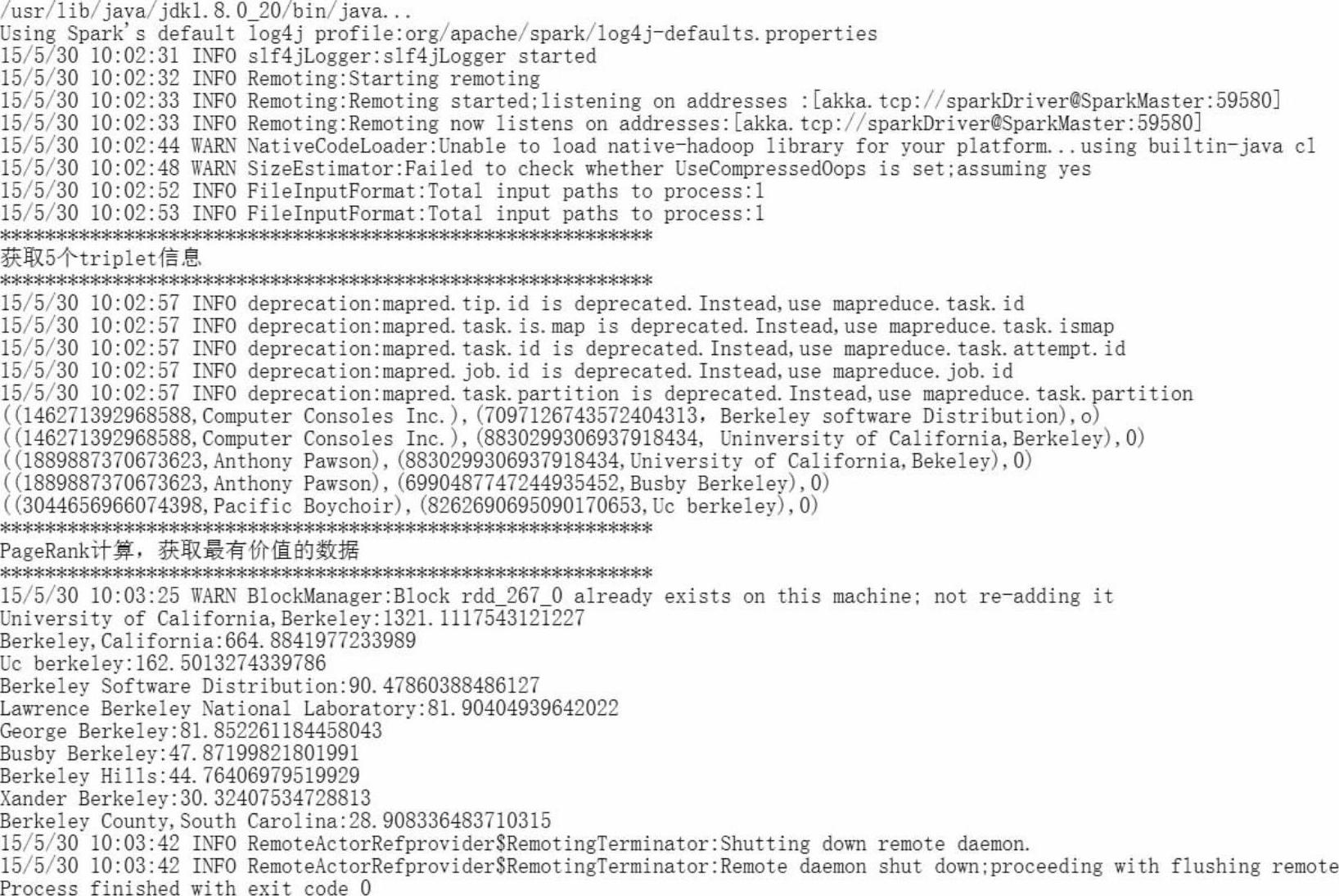
图8-13 找出最有影响力的文章的运行结果
程序运行结果会按照PageRank值由大到小的顺序打印出10条记录。PageRank值越大,说明该文章影响力越大。从上述程序运行结果可以发现,被应用最多而影响力最大的题目为“University of California,Berkeley”这篇文章。
(5)性能改进方案。因为图计算中一般涉及的顶点和边非常多,一般会到达上千万甚至过亿的顶点,所以如果要改进性能一个比较好的方式是打开序列化器并采用Google的Kryo序列化器,我们可以把Spark安装目录中的conf目录下的“spark-defaults.conf.template”复制成“spark-defaults.conf”:

然后打开“spark-defaults.conf”:
在“spark-defaults.conf”中加入如下内容:
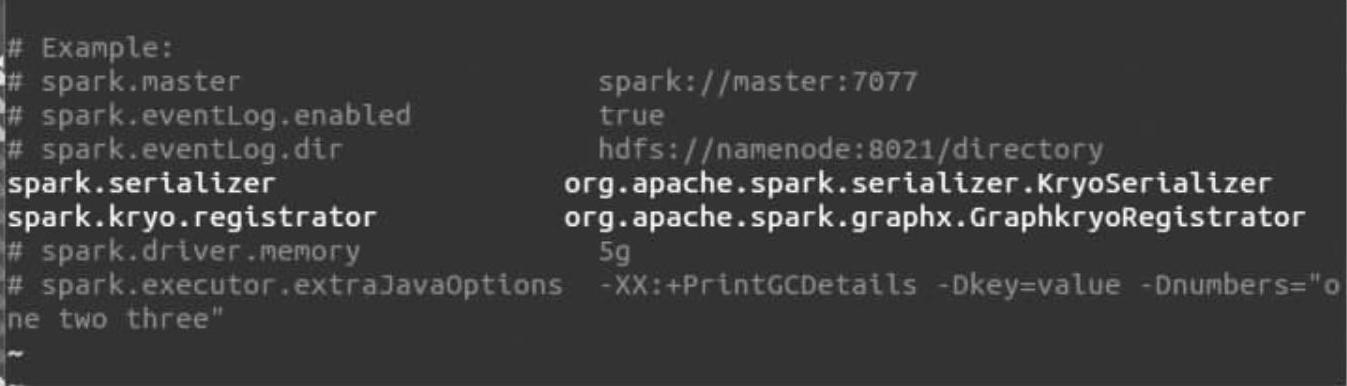
这样就为Spark GraphX配置好了应给Kryo序列化器。
(6)可复用性。本算法广泛适用于一般的社交网络、电子商务、视频推荐等内容,例如FaceBook、微信、微博、Twitter、LinkedIn、淘宝、京东商城等,获取到相关的数据后可以使用Spark SQL进行ETL,获取到满足格式要求的业务关注数据,就可以计算出每个Item的影响力值,评价Item的影响力。
(7)程序扩展。在实际的生产环境中,IT系统一般会采集用户的行为数据以日志文件的方式存储,当日志文件导入到Spark所支持的分布式存储系统后,可以使用Spark SQL进行ETL产出目标数据,然后使用本案例中的类似算法进行数据的深度挖掘,来达到从数据中提取出更有价值的信息来更好的支持业务的目的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。