



一般图的分布式存储总体上有边分割和点分割两种存储方式(如图8-3所示)。2013年,GraphLab2.0将其存储方式由边分割变为点分割,在性能上取得重大提升,目前点分割的存储方式基本上已经被业界广泛接受并使用。
边分割和点分割的两种存储形式如图8-4所示。
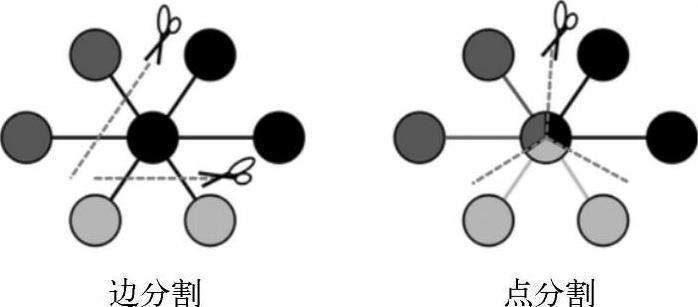
图8-4 图的边分割和点分割
下面比较一下两种分割方式的优缺点。
边分割(Edge-Cut):每个顶点都存储一次,但有的边会被打断分到两台机器上。这样做的好处是节省存储空间,坏处是对图进行基于边的计算时,对于一条两个顶点被分到不同机器上的边来说,要跨机器通信传输数据,内网通信流量大。
点分割(Vertex-Cut):每条边只存储一次,都只会出现在一台机器上。邻居多的点会被复制到多台机器上,增加了存储开销,同时会引发数据同步问题。好处是可以大幅减少内网通信量。
虽然两种方式互有利弊,但现在是点分割占主流,各种分布式图计算框架都将自己底层的存储形式变成了点分割。主要原因有两个:磁盘价格下降,存储空间不再是问题,而内网的通信资源没有突破性进展,集群计算时内网带宽是宝贵的,时间比磁盘更珍贵,这点就类似于常见的空间换时间的策略;在当前的应用场景中,绝大多数网络都是“无尺度网络”,遵循幂律分布,不同点的邻居数量相差非常悬殊,而边分割会使那些多邻居的点所相连的边大多数被分到不同的机器上,这样的数据分布会使得内网带宽更加捉襟见肘,于是边分割存储方式被渐渐抛弃了。(https://www.xing528.com)
SparkGraphX的分布式存储采用点分割的模式,它的特点是任何一条边只会出现在一台机器上,每个点有可能分布到不同的机器上。通过调用GraphImpl的PartitonBy方法,由用户指定不同划分策略(PartitonStrategy)作为PartitonBy方法的参数进行分割,划分策略会将边分配给各个EdgePartiton,顶点Master(主点)分配到各个VertexPartiton,EdgePartition也会缓存本地关联点的Ghost副本。划分策略的不同会影响需要缓存的Ghost副本数量,以及每个EdgePartiton分配的边的均衡程度,需要根据图的结构特征选取最佳策略。目前有Edge-Partition2D、EdgePartition1D、RandomVeertexCut和CanonicalRandomVertexCut这四种分割策略。
图8-5展示了Property Graph(属性图)采取EdgePartition2D的划分策略进行点分割的方式,可以看到对顶点A和顶点D切割后形成了Part.1和Part.2两个边分区,其中Part.1中的顶点A是主点,Part.2中的顶点A是虚点,Part.1中的顶点D是虚点,Part.2中的顶点D是主点。划分后的数据以RDD的方式分布式地存储在集群中的各个结点上,从表Vertex Table中可以看到图的顶点RDD(VertexRDD)被分成两个分区,表Edge Table中可以看到边RDD(EdgeRDD)也被分成了两个分区,每个分区中记录了不同的边。
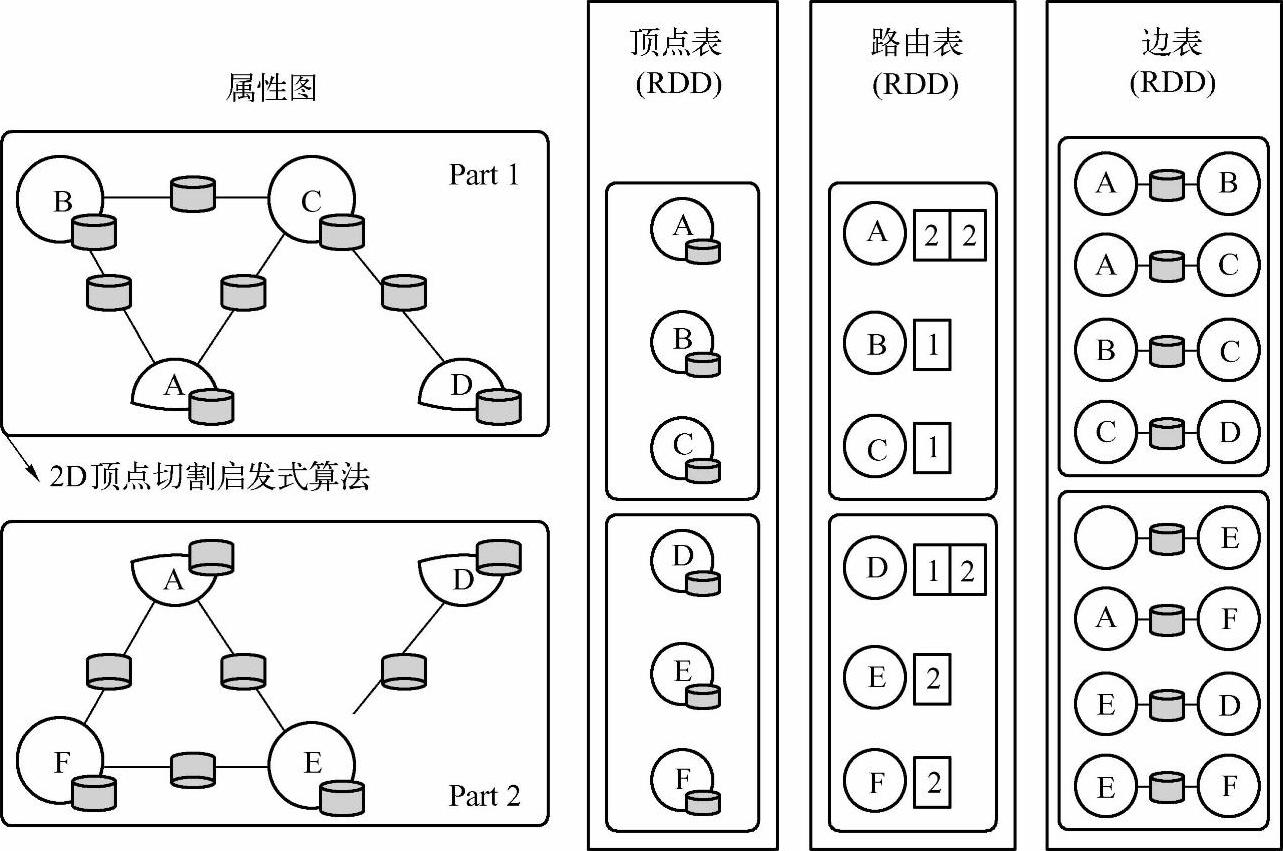
图8-5 图的划分和存储示例
在图计算的时候,如果顶点A的数据发生了变化,可以先更新Part.1中顶点A的数据,然后将所有更新好的数据发送到Part.2的顶点A更新它的数据。这样做的好处是在边的存储上是没有冗余的,而且对于某个顶点与它的邻居的交互操作,只要满足交换律和结合律,比如求顶点的所有边的条数这样的操作,可以在不同机器上并行进行,只要把每台机器上的结果进行汇总就可以了,网络开销也比较小,代价是每个顶点可能要存储到多份,更新顶点要有数据同步开销。
这里有个重要的概念就是Routing Table(路由表),Routing Table里记录着结点的路由信息,也就是图在进行计算时将顶点RDD(VertexRDD)发送给边RDD(EdgeRDD)的路由信息。这样做的好处是在有些图计算的过程中(比如mapVertices操作和mapEdges等操作),图的内部结构不会改变,所以可以通过使用Routing Table重用顶点数据。考虑到Rou-ting Table可能在图计算过程中会被多次使用,因此它在建立后即被缓存起来。在图8-5中,表Vertex Table中的一个Partition对应着Routing Table中的一个Partition,Routing Table记录了一个顶点会涉及哪些Edge Table Partition(边分区)。
最后需要强调的一点是,图的Table View和Graph View两种视图底层共用的物理数据由VertexRDD和EdgeRDD这两个RDD组成,点和边实际都不是以表Collection[tuple]的形式存储的,而是由VertexPartiton/EdgePartition在内部存储一个带索引结构的分片数据块,以加速不同视图下的遍历速度。不变的索引结构在RDD转换过程中是共用的,降低了计算和存储的开销。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。