



有状态(Stateful)的操作是指在将不断输入的数据按时间间隔切分成一个个RDD,然后对当前和历史的RDD累加后进行的操作。现在建立一个有状态的Spark Streaming监控。在SparkStreamingExample工程下新建一个用于实现Spark Streaming监控有状态(Stateful)操作的Scala文件SparkStatefulWordCountDemo.scala。
(1)SparkStatefulWordCountDemo.scala的具体实现代码如下:


(2)对上述代码进行解析如下。
1)首先使用匿名函数(values:Seq[Int],state:Option[Int])来定义更新数据状态的操作,第一个参数values:Seq[Int]表示新进来的值,第二个参数state:Option[Int]表示上一次统计的值。这个匿名函数被赋值给变量updateFunc,使updateFunc成为一个值函数,最终值函数updateFunc被传递给实时监控workCounts的updateStateByKey函数来更新监控状态。在匿名函数的函数体里面如果有新的信息来了就会获取新的值,再获取上一次旧的值,最终使用Some(currentCount+previousCount)把新的值添加到旧的值里面,依此来代替之前的旧的值并返回这个值。
2)然后创建StreamingContext的实例ssc,因为是有状态的,需要保存之前的信息,所以使用ssc.checkpoint(".")设定了checkpoint的目录,以防断电后内存数据丢失。这里因为没有设置checkpoint的时间间隔,所以会发现每一次数据块过来就会切分一次,产生一个.checkpoint文件。
3)接着使用ssc.socketTextStream(args(0),args(1).toInt)从socket流里面获取数据,参数args(0)是服务器的名称,参数args(1).toInt是服务器的端口。紧接着使用val words=lines.flatMap(_.split(","))和val wordCounts=words.map(x=>(x,1))进行workcounts的单词统计。
4)最后使用updateStateByKey来更新状态。
(3)配置运行参数来运行SparkStatefulWordCountDemo.scala,配置参数如图7-20。
这里指定了应用的名称是SparkStatefulWordCountDemo,应用的入口类是spark_streaming_example.SparkStatefulWordCountDemo,服务器的名称是localhost,服务器的端口号是8888。(https://www.xing528.com)
现在启动服务器,在命令行中进入/usr/local/spark/spark-1.1.0-bin-hadoop2.4,然后输入java-classpath/usr/local/spark/spark-1.1.0-bin-hadoop2.4/SparkStreamingExam-ple.jar spark_streaming_example.SaleDeviceSimulation/root/user/local/idea/networkdata.txt 8888 2000,如下所示。

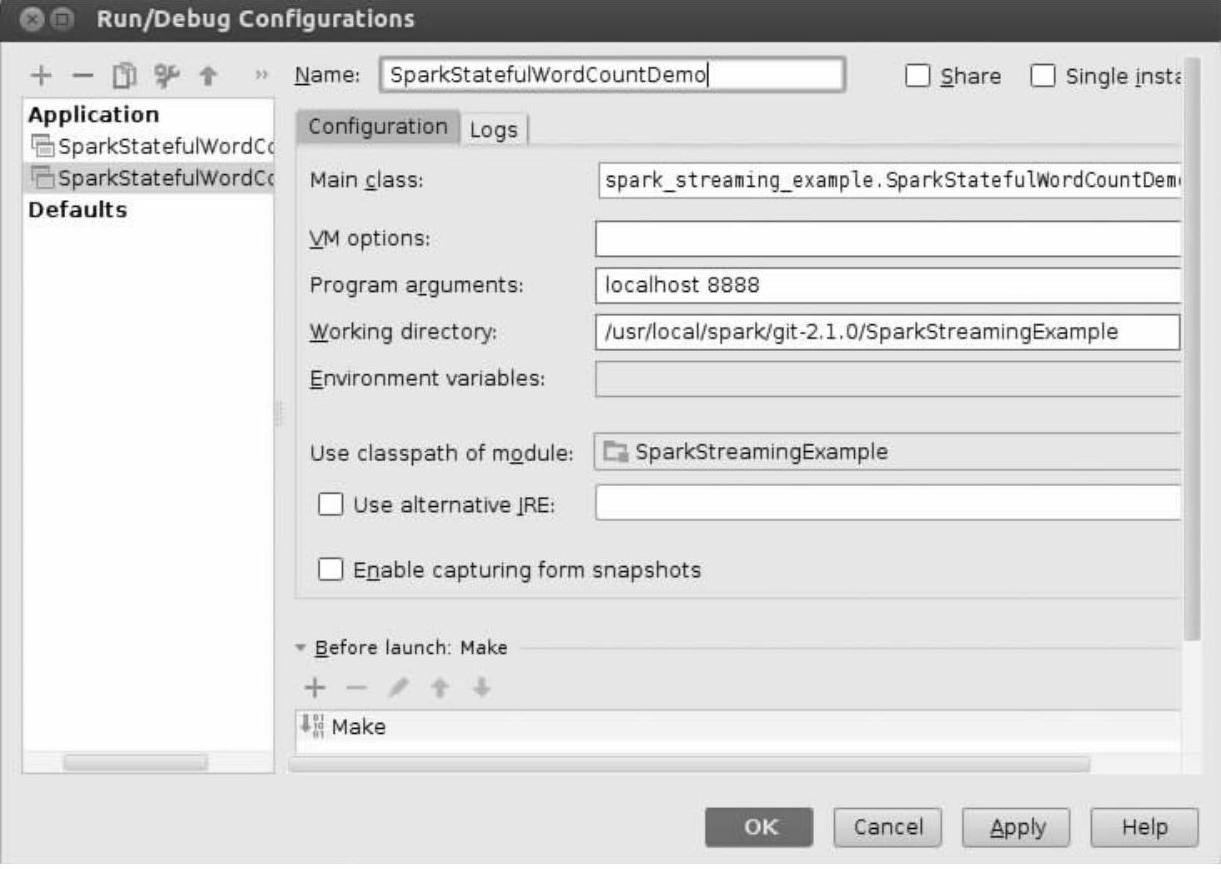
图7-20 配置运行参数
这里使用的是Java的运行模式,首先指定了jar包的classpath路径为/usr/local/spark/ spark-1.1.0-bin-hadoop2.4/SparkStreamingExample.jar;然后指定运行jar包中treaming_ example包下的SaleDeviceSimulation.scala文件;接着使用/root/user/local/idea/networkda-ta.txt指定服务器端向客户端发送的文本文件;紧接着用8888指定服务器端口;最后用2000指定每隔2s向客户端发送一行数据。回车后服务器端一直处于等待监听是否有客户端连接上来的状态,如果有客户端连接上来之后服务器就每隔2s向连接上来的服务器发送一次文本。
(4)运行SparkStatefulWordCountDemo.scala,效果如下:


由于在SparkStatefulWordCountDemo.scala中使用ssc.checkpoint(".")设置了checkpoint所以在IDE中会每隔5s产生一个checkpoint文件,如图7-21所示。
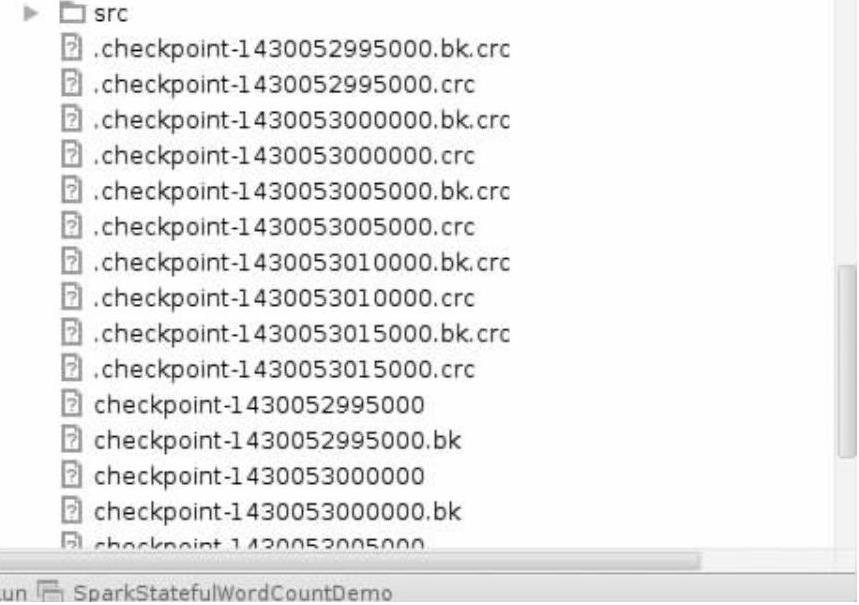
图7-21 checkpoint文件
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。