



DStream(Discretized Stream)作为Spark Streaming的基础抽象,它代表持续性的数据流。这些数据流既可以通过外部输入源来获取,也可以通过现有的Dstream的transformation操作来获得。在内部实现上,DStream由一组时间序列上连续的RDD来表示。每个RDD都包含了自己特定时间间隔内的数据流,如图7-3所示。
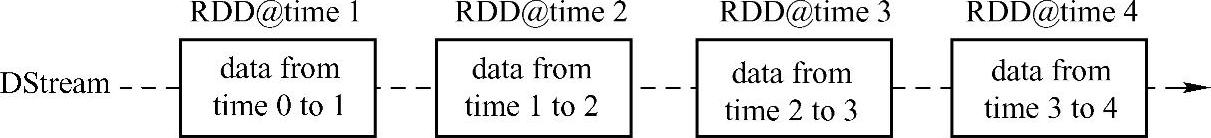
图7-3 DStream中在时间轴下生成离散的RDD序列
对DStream中数据的各种操作也是映射到内部的RDD上来进行的,如图7-4所示,对Dtream的操作可以通过RDD的transformation生成新的DStream。这里的执行引擎是Spark。
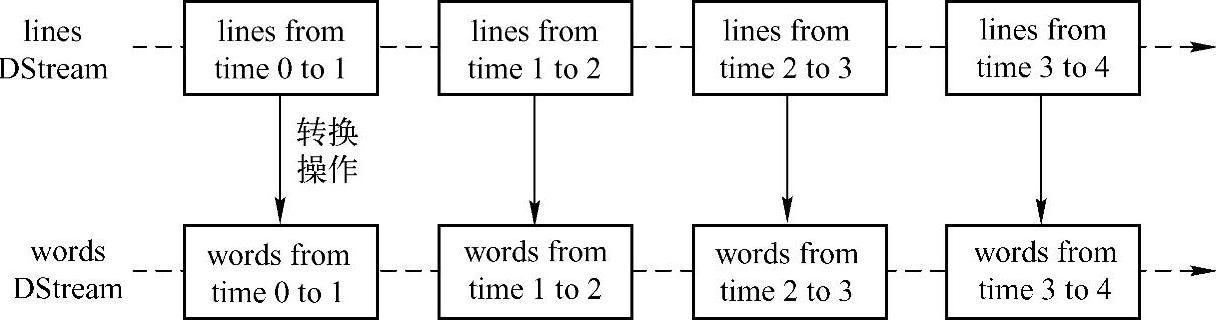
图7-4 DStream的操作流程
1.怎样使用Spark Streaming
作为构建于Spark之上的应用框架,Spark Streaming承袭了Spark的编程风格,对于已经了解Spark的用户来说能够快速地上手。接下来以Spark Streaming官方提供的Word Count代码为例来介绍Spark Streaming的使用方式。
(1)创建StreamingContext对象。同Spark初始化需要创建SparkContext对象一样,使用Spark Streaming就需要创建StreamingContext对象。创建StreamingContext对象所需的参数与SparkContext基本一致,包括指明Master,设定名称(如NetworkWordCount)。需要注意的是参数Seconds(1),Spark Streaming需要指定处理数据的时间间隔,如上例所示的1s,那么Spark Streaming会以1s为时间窗口进行数据处理。此参数需要根据用户的需求和集群的处理能力进行适当的设置。
(2)创建InputDStream。如同Storm的Spout,Spark Streaming需要指明数据源。如代码中所示的socketTextStream,Spark Streaming以socket连接作为数据源读取数据。当然Spark Streaming支持多种不同的数据源,包括Kafka、Flume、HDFS/S3、Kinesis和Twitter等数据源。
(3)操作DStream。对于从数据源得到的DStream,用户可以在其基础上进行各种操作,如上例所示的操作就是一个典型的word count执行流程:对于当前时间窗口内从数据源得到的数据首先进行分割,然后利用map和reduceByKey方法进行计算,当然最后还有使用print()方法输出结果。
(4)启动Spark Streaming。之前所作的所有步骤只是创建了执行流程,程序没有真正连接上数据源,也没有对数据进行任何操作,只是设定好了所有的执行计划,当ssc.start()启动后程序才真正进行所有预期的操作。
至此对于Spark Streaming的如何使用有了一个大概的印象,在后面的章节我们会通过源代码深入探究Spark Streaming的执行流程。
2.DStream的输入源
在Spark Streaming中所有的操作都是基于流的,而输入源是这一系列操作的起点。输入DStreams和DStreams接收的流都代表输入数据流的来源。在Spark Streaming提供两种内置数据流来源:
●基础来源:在StreamingContext API中直接可用的来源。例如:文件系统、Socket(套接字)连接和Akka actors。
●高级来源:如Kafka、Flume、Kinesis、Twitter等,可以通过额外的实用工具类创建。
(1)基础来源。在前面分析怎样使用Spark Streaming的例子中我们已看到ssc.socket-TextStream()方法,可以通过TCP套接字连接,从从文本数据中创建了一个DStream。除了套接字,StreamingContext的API还提供了方法从文件和Akka actors中创建DStreams作为输入源。
Spark Streaming提供了streamingContext.fileStream(dataDirectory)方法可以从任何文件系统(如:HDFS、S3、NFS等)的文件中读取数据,然后创建一个DStream。Spark Stream-ing监控dataDirectory目录和在该目录下任何文件被创建处理(不支持在嵌套目录下写文件)。需要注意的是:读取的必须是具有相同的数据格式的文件;创建的文件必须在dataDi-rectory目录下,并通过自动移动或重命名成数据目录;文件一旦移动就不能被改变,如果文件被不断追加,新的数据将不会被阅读。对于简单的文本文,可以使用一个简单的stream-ingContext.textFileStream(dataDirectory)方法来读取数据。
Spark Streaming也可以基于自定义Actors的流创建DStream,通过Akka actors接受数据流,使用方法streamingContext.actorStream(actorProps,actor-name)。
Spark Streaming使用streamingContext.queueStream(queueOfRDDs)方法可以创建基于RDD队列的DStream,每个RDD队列将被视为DStream中一块数据流进行加工处理。
(2)高级来源。这一类的来源需要外部non-Spark库的接口,其中一些有复杂的依赖关系(如Kafka、Flume)。因此通过这些来源创建DStreams需要明确其依赖。例如,如果想创建一个使用Twitter tweets的数据的DStream流,必须按以下步骤来做:
1)在SBT或Maven工程里添加spark-streaming-twitter_2.10依赖。
2)开发:导入TwitterUtils包,通过TwitterUtils.createStream方法创建一个DStream。
3)部署:添加所有依赖的jar包(包括依赖的spark-streaming-twitter_2.10及其依赖),然后部署应用程序。
需要注意的是,这些高级的来源一般在Spark Shell中不可用,因此基于这些高级来源的应用不能在Spark Shell中进行测试。如果你必须在Spark shell中使用它们,你需要下载相应的Maven工程的Jar依赖并添加到类路径中。
其中一些高级来源如下:
●Twitter:Spark Streaming的TwitterUtils工具类使用Twitter 4J,Twitter 4J库支持通过任何方法提供身份验证信息,你可以得到公众的流,或得到基于关键词过滤流。
●Flume:Spark Streaming可以从Flume中接受数据。
●Kafka:Spark Streaming可以从Kafka中接受数据。
●Kinesis:Spark Streaming可以从Kinesis中接受数据。
需要重申的一点是,在开始编写自己的SparkStreaming程序之前,一定要将高级来源依赖的Jar添加到SBT或Maven项目相应的artifact中。常见的输入源和其对应的Jar包如图7-5所示。

图7-5 输入源和其对应的Jar包
另外,输入DStream也可以创建自定义的数据源,需要做的就是实现一个用户定义的接收器。
2.DStream的操作
与RDD类似,DStream也提供了自己的一系列操作方法,这些操作可以分成三类:一种是普通的转换操作,一种是基于窗口的转换操作,最后是输出操作。
(1)普通的转换操作。首先我们来看普通的转换操作都有哪些,如表7-1所示。(https://www.xing528.com)
表7-1 DStream的普通转换操作
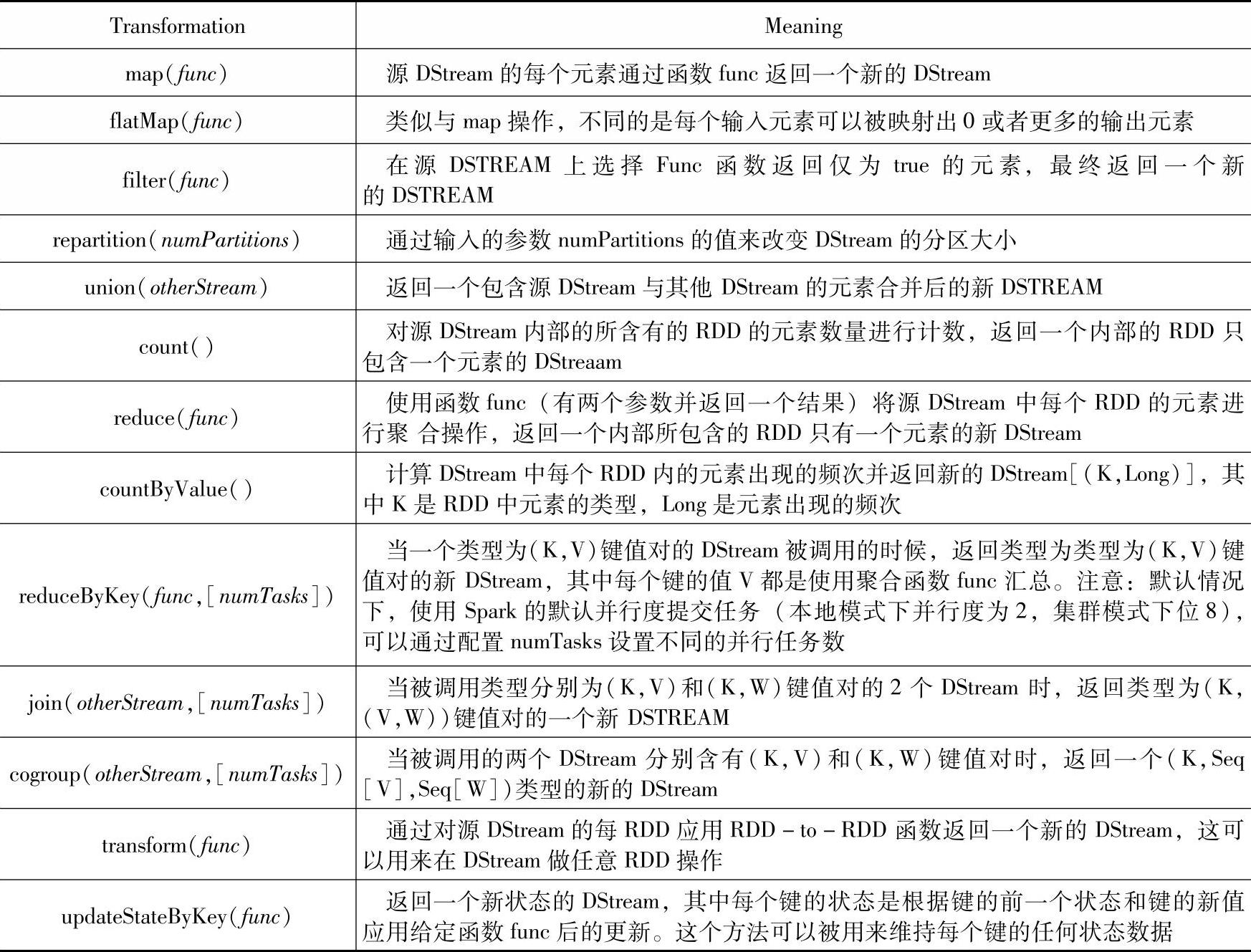
在上面列出的这些操作中,transform()方法和updateStateByKey()方法值得我们深入的探讨一下:
1)transform(func)方法。该transform方法(转换操作)连同其类似的transformWith操作允许DStream上应用任意RDD-to-RDD函数。transform可以被应用于在DStream API中未暴露任何的RDD操作。例如,在每批次的数据流与另一数据集的连接功能不直接暴露在DStream API中,但可以轻松地使用transform操作来做到这一点,这使得DStream的功能非常强大。例如,你可以通过连接预先计算的垃圾邮件信息的输入数据流(可能也有Spark生成的),然后基于此做实时数据清理的筛选,如下面官方提供的伪代码所示。事实上,也可以在transform方法中使用机器学习和图形计算的算法。

2)updateStateByKey方法。该updateStateByKey方法可以让你保持任意状态,同时不断有新的信息进行更新。要使用此功能,必须进行两个步骤:
●定义状态——状态可以是任意的数据类型。
●定义状态更新函数——用一个函数指定如何使用先前的状态和从输入流中获取的新值更新状态。
让我们用一个例子来说明,假设你要进行文本数据流中单词计数。在这里,正在运行的计数是状态而且它是一个整数。我们定义了更新功能如下:

此函数应用于含有键值对的DStream中(如前面的示例中,在DStream中含有(word 1)键值对)。它会针对里面的每个元素(如wordCount中的word)调用一下更新函数,ne-wValues是最新的值,runningCount是之前的值。

(2)窗口操作。Spark Streaming还提供了窗口的计算,它允许你通过滑动窗口对数据进行转换。下面我们先通过表7-2看看都有哪些窗口操作。
表7-2 窗口操作及其含义
下面我们结合图7-6来讲解一下窗口操作的一些概念。
在Spark Streaming中,数据处理是按批进行的,而数据采集是逐条进行的,因此在Spark Streaming中会先设置好批处理间隔(batch duration),当超过批处理间隔的时候就会把采集到的数据汇总起来成为一批数据交给系统去处理。
对于窗口操作而言,在其窗口内部会有N个批处理数据,批处理数据的大小由窗口间隔(window duration)决定,而窗口间隔指的就是窗口的持续时间,在窗口操作中,只有窗口的长度满足了才会触发批数据的处理。除了窗口的长度,窗口操作还有另一个重要的参数就是滑动间隔(slide duration),它指的是经过多长时间窗口滑动一次形成新的窗口,滑动窗口默认情况下和批次间隔的相同,而窗口间隔一般设置的要比它们两个大。在这里必须注意的一点是滑动间隔和窗口间隔的大小一定得设置为批处理间隔的整数倍。
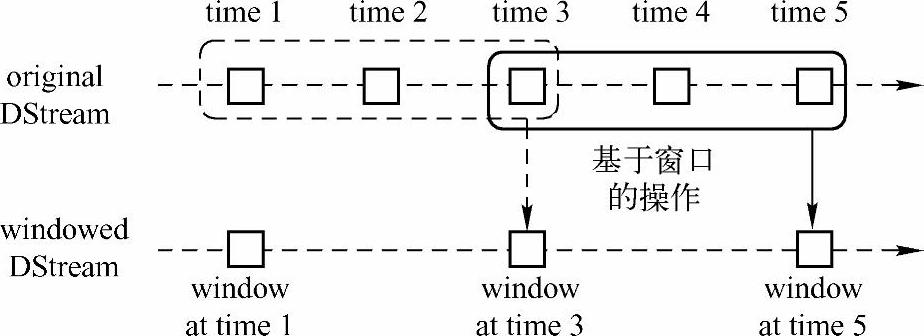
图7-6 批处理间隔示意图
如图7-6所示,批处理间隔是1个时间单位,窗口间隔是3个时间单位,滑动间隔是2个时间单位。对于初始的窗口time1~time3,只有窗口间隔满足了才触发数据的处理。这里需要注意的一点是,初始的窗口有可能流入的数据没有撑满,但是随着时间的推进,窗口最终会被撑满。当每隔两个时间单位,窗口滑动一次后,会有新的数据流入窗口,这时窗口会移去最早的两个时间单位的数据,而与最新的两个时间单位的数据进行汇总形成新的窗口(time3~time5)。
对于窗口操作,批处理间隔、窗口间隔和滑动间隔是非常重要的三个时间概念,是理解窗口操作的关键所在。
(3)输出操作。Spark Streaming允许DStream的数据被输出到外部系统,如数据库或文件系统。由于输出操作实际上使transformation操作后的数据可以通过外部系统被使用,同时输出操作触发所有DStream的transformation操作的实际执行(类似于RDD操作)。以下表7-3列出了目前主要的输出操作:
表7-3 输出操作及其含义

dstream.foreachRDD是一个非常强大的输出操作,它允将许数据输出到外部系统。但是,如何正确高效地使用这个操作是很重要的,下面展示了如何去避免一些常见的错误。
通常将数据写入到外部系统需要创建一个连接对象(如TCP连接到远程服务器),并用它来发送数据到远程系统。出于这个目的,开发者可能在不经意间在Spark driver端创建了连接对象,并尝试使用它保存RDD中的记录到Spark worker上,如下面代码:
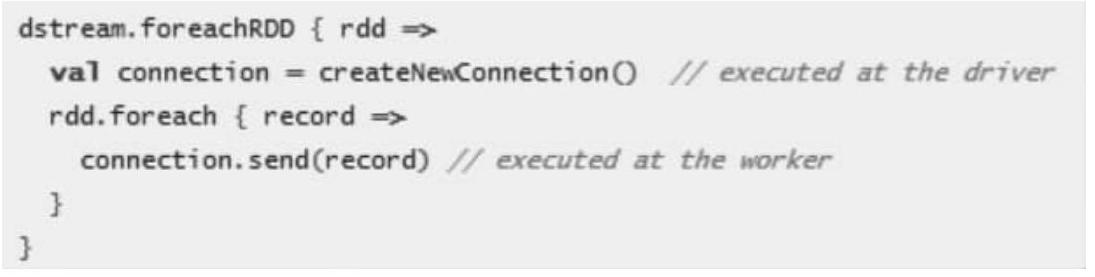
这是不正确的,这需要连接对象进行序列化并从Driver端发送到Worker上。连接对象很少在不同机器间进行这种操作,此错误可能表现为序列化错误(连接对不可序列化),初始化错误(连接对象在需要在Worker上进行需要初始化)等等,正确的解决办法是在Worker上创建的连接对象。
但是,这可能会导致另一个常见的错误,为每条记录创建一个新的连接对象,如下面代码所示。

通常情况下,创建一个连接对象有时间和资源开销。因此,创建和销毁的每条记录的连接对象可能招致不必要的资源开销,并显著降低系统整体的吞吐量。一个更好的解决方案是使用rdd.foreachPartition方法创建一个单独的连接对象,然后使用该连接对象输出的所有RDD分区中的数据到外部系统,如下面代码所示。
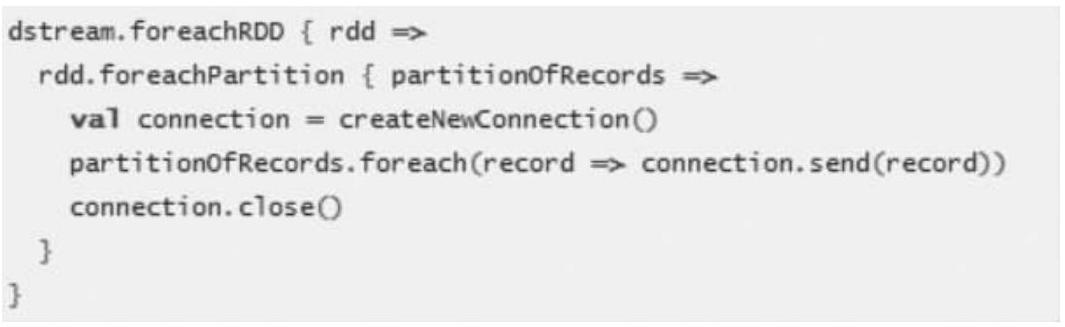
这缓解了创建多条记录连接的开销。最后,还可以进一步通过在多个RDDs/batches上重用连接对象进行优化。一个保持连接对象的静态池可以重用在多个批处理的RDD上将其输出到外部系统,从而进一步降低了开销。

需要注意的是,在静态池中的连接应该按需延迟创建,这样可以更有效地把数据发送到外部系统。另外需要要注意的是:DStreams是延迟执行的,就像RDD的操作是由actions触发一样。默认情况下,输出操作会按照它们在Streaming应用程序中定义的顺序一个个执行。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。