



1.Parquet文件读取和保存
Spark SQL同样支持对parquet文件的读取和保存。parquet文件的一个优势是它天生保留了元数据(Schema)信息,在读取的时候不需要使用隐式转换来生成SchemaRDD,它可以直接转换成SchemaRDD,当然也可以直接把SchemaRDD以parquet文件格式直接保存到外部文件存储系统中去,下面我们承接上一节的运行示例来读取和保存Parquet文件。
下面的操作同样在spark-shell交互式界面中运行。
(1)首先我们把people.registerAsTable("people")操作后已经注册成表的SchemaRDD保存到HDFS的data目录下,这里的SchemaRDD指的还是people。可以在spark-shell交互式界面中使用以下命令保存文件:
people.saveAsParquetFile("hdfs://SparkMaster:8000/data//people.parquet")
(2)可以在HDFS的WebUI中查看保存的Parquet文件,如图6-10所示。
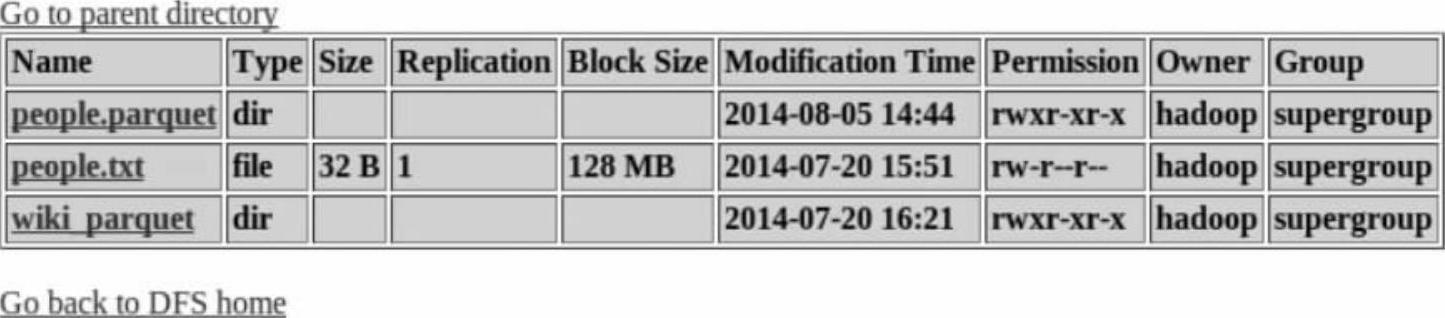
图6-10 保存在HDFS上的Parquet文件
(3)我们从HDFS中读取Parquet文件,在spark-shell交互式界面中输入读取命令,命令如下:
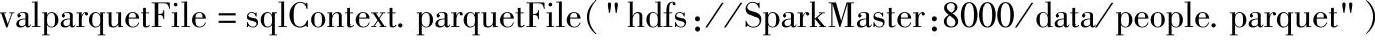
(4)这时读取进来的Parquet文件不需要使用case class来定义表结构,直接把parquet-File注册成表。
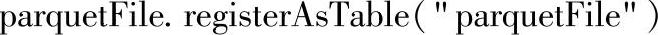
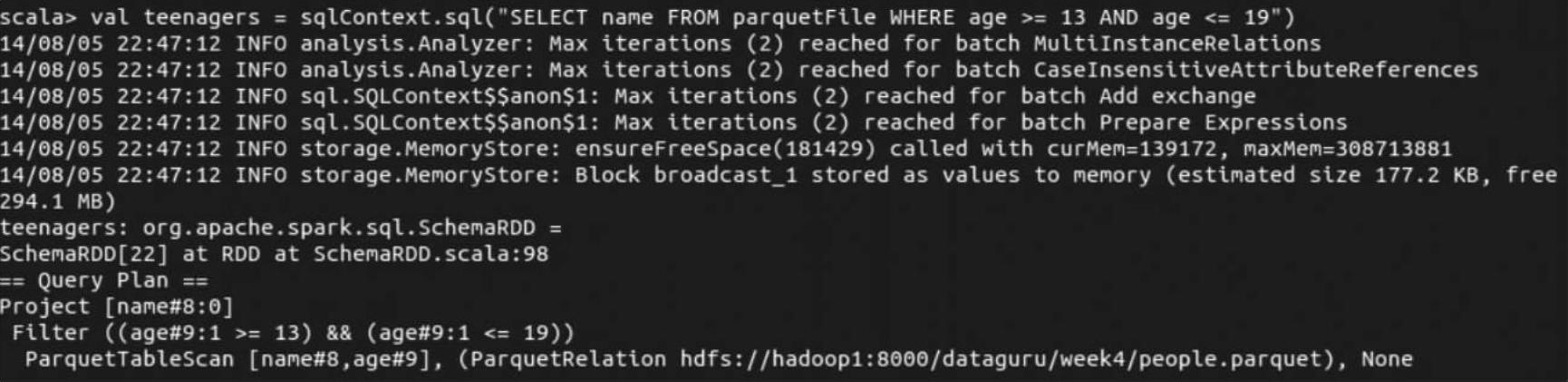
(5)使用“val teenagers=sqlContext.sql("SELECT name FROM parquetFile WHERE age>=13 AND age<=19")”进行查询操作,查询结果如下。
(6)使用“teenagers.map(t=>"Name:"+t(0)).collect().foreach(println)”命令触发查询操作,查询结果如下。
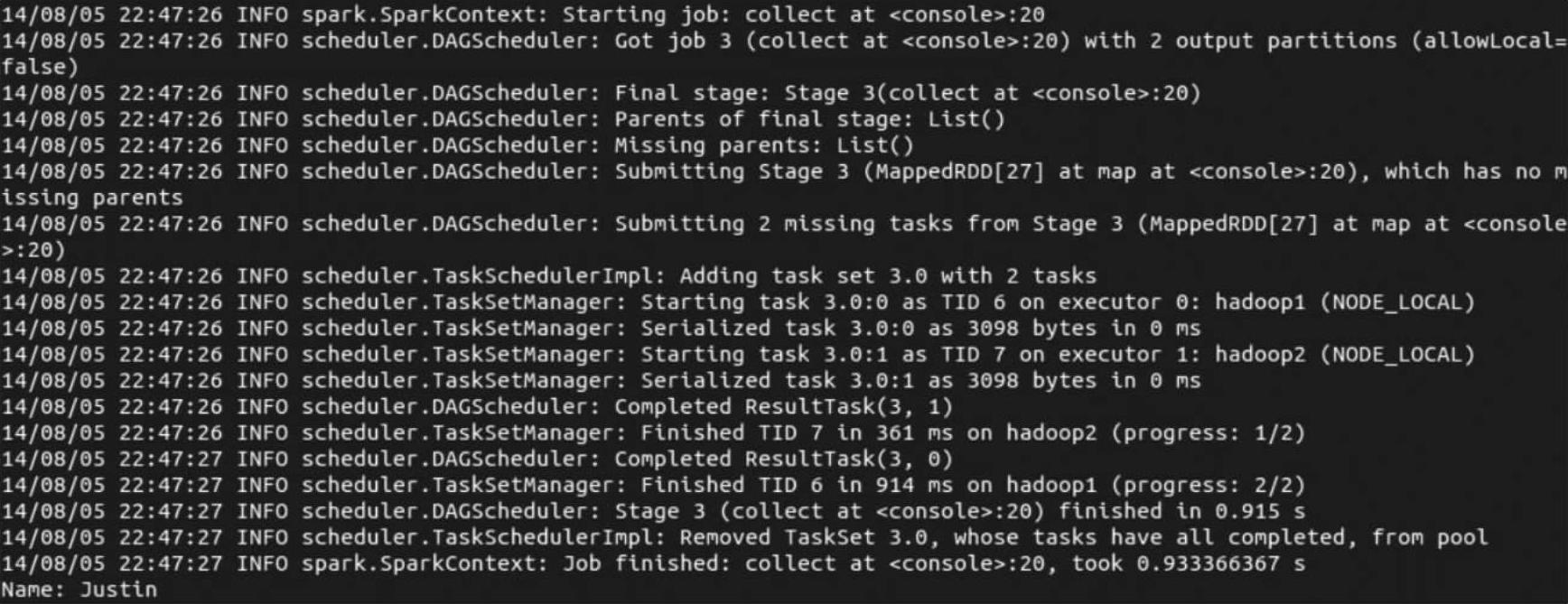
(7)最后介绍在sqlContext的查询中,还可以将来自不同数据源的表进行混合查询,比如将来自文本文件的数据(对应people)和来自Parquet文件的数据(对应parquetFile)进行混合查询,命令如下:

我们把上述命令复制到spark-shell交互式终端进行执行,下面可以查看运行结果:
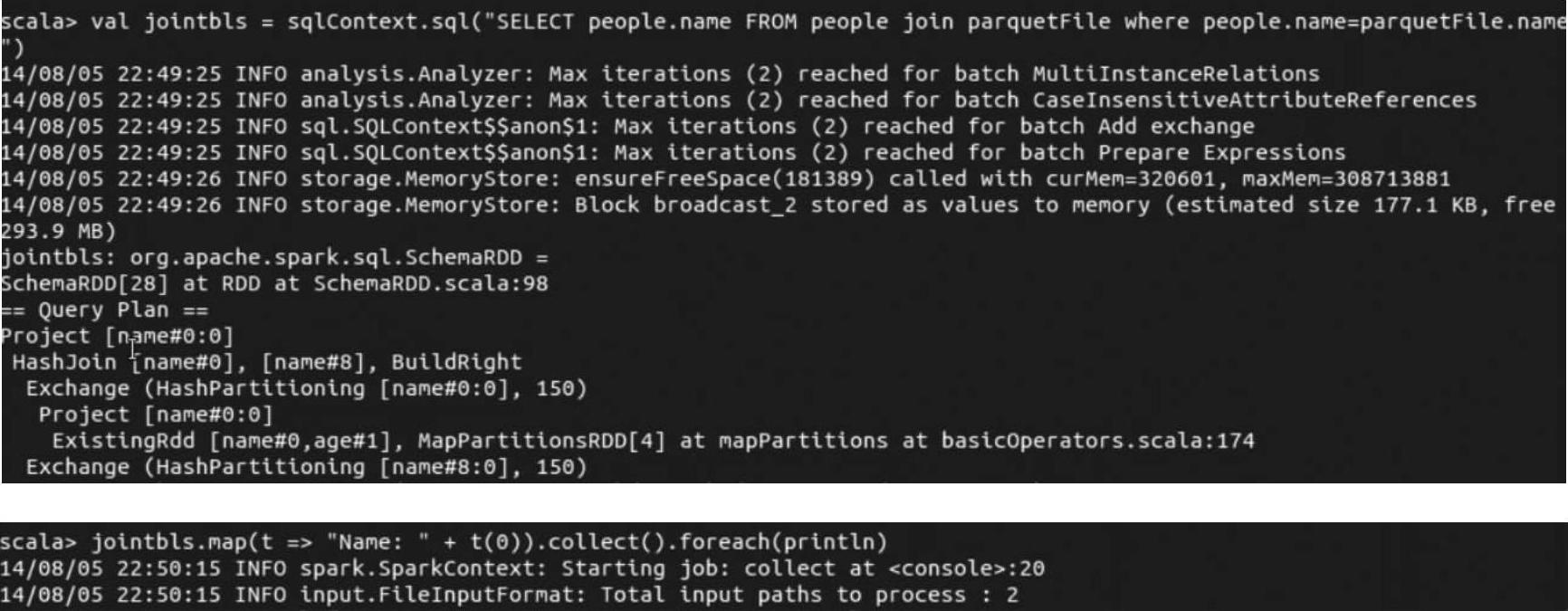 (https://www.xing528.com)
(https://www.xing528.com)
2.JSON文件的读取操作
Spark SQL从Spark 1.1版本开始增加了对JSON文件格式的支持,并且在Spark 1.2版本中进行了加强,它的目的就是在Spark中使得查询和创建JSON数据变得非常简单。随着Web和手机应用的流行,JSON格式的数据已经是Web Service API之间通信以及数据的长期保存的事实上的标准格式了。但是使用现有的工具,用户常常需要开发出复杂的程序来读写分析系统中的JSON数据集。而Spark SQL中对JSON数据的支持极大地简化了使用JSON数据的终端的数据加载与存储操作。
Spark SQL提供了内置的语法来查询这些JSON数据,并且在读写过程中自动地推断出JSON数据的模式。Spark SQL可以解析出JSON数据中嵌套的字段,并且允许用户直接访问这些字段,而不需要任何显示的转换操作。
在编写Spark SQL应用程序的时候,对于JSON文件格式的数据的读取可以通过SQL-Context提供的jsonRDD方法和jsonFile方法,使用这两个方法,就可以利用提供的JSON数据集来创建SchemaRDD对象,并且将SchemaRDD注册成表。下面的代码就是通过SQLCon-text的jsonFile方法加载外部的JSON文件目录中的数据,其中JSON文件的每一行是一个JSON对象。

而对于SQLContext的jsonRDD方法,它是通过从现有的RDD加载数据,需要注意的是RDD中的每个元素包含一个JSON对象的字符串。
下面演示使用SQLContext的jsonFile方法来读取数据并对加载的数据进行操作。
(1)首先使用“hadoop fs-copyFromLocal/root/Downloads/people.json/data”把/root/ Downloads目录下的people.json文件复制到HDFS的data目录下。people.json文件的内容如下:

(2)查看HDFS中上传的文件,如图6-11所示。
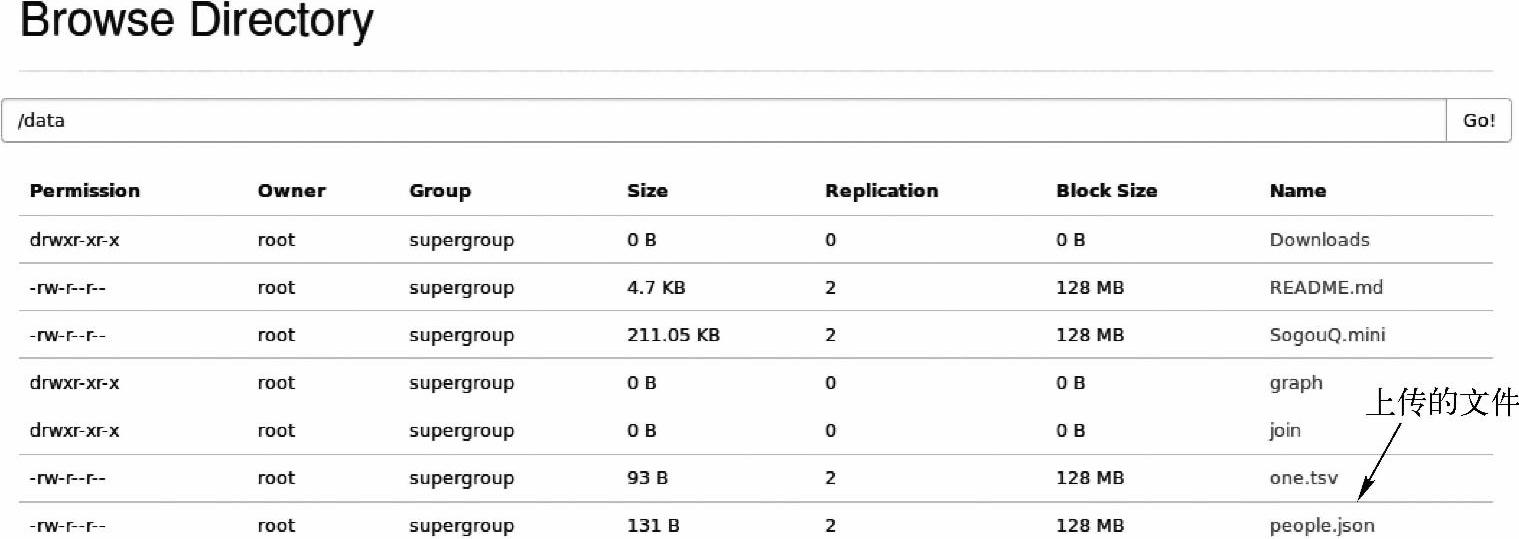
图6-11 上传到HDFS上的people.json文件
(3)在spark-shell中输入以下代码:
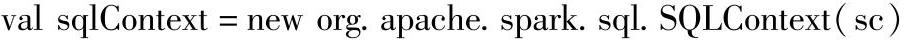

(4)运行结果如下:

(5)查询的结果可以直接使用,或者是被其他的Spark子框架使用,比如Spark的Ml-lib。将SchemaRDD对象保存成JSON文件是通过调用SchemaRDD的toJSON方法实现的,由于SchemaRDD可以通过很多其他格式的数据源进行创建,比如Hive tables、Parquet文件、JDBC、Avro文件以及其他SchemaRDD的结果,这就意味着用户可以很方便地将数据写成JSON格式,而不需要考虑到源数据集的来源。
同时,JSON数据集可以通过Spark SQL内置的内存列式存储格式进行存储,也可以存储成其他格式,比如Parquet或者Avro。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。