



一切问题来自源码,而解决之道同样来自源码,SQL和HQL语句的执行框架也是如此,因此,下面将结合源码,通过具体的案例来详细分析一下SQL语句和Hive SQL语句的执行流程。
1.SQL语句的执行流程
对于用户编写的Spark SQL程序,从Spark SQL到RDD的DAG关系主要可以分为五个步骤,下面我们根据Spark官方提供的Spark SQL的案例(http://spark.apache.org/docs/lat-est/sql-programming-guide.html),结合源码来分析一下SQL语句的执行流程。具体案例代码如下。
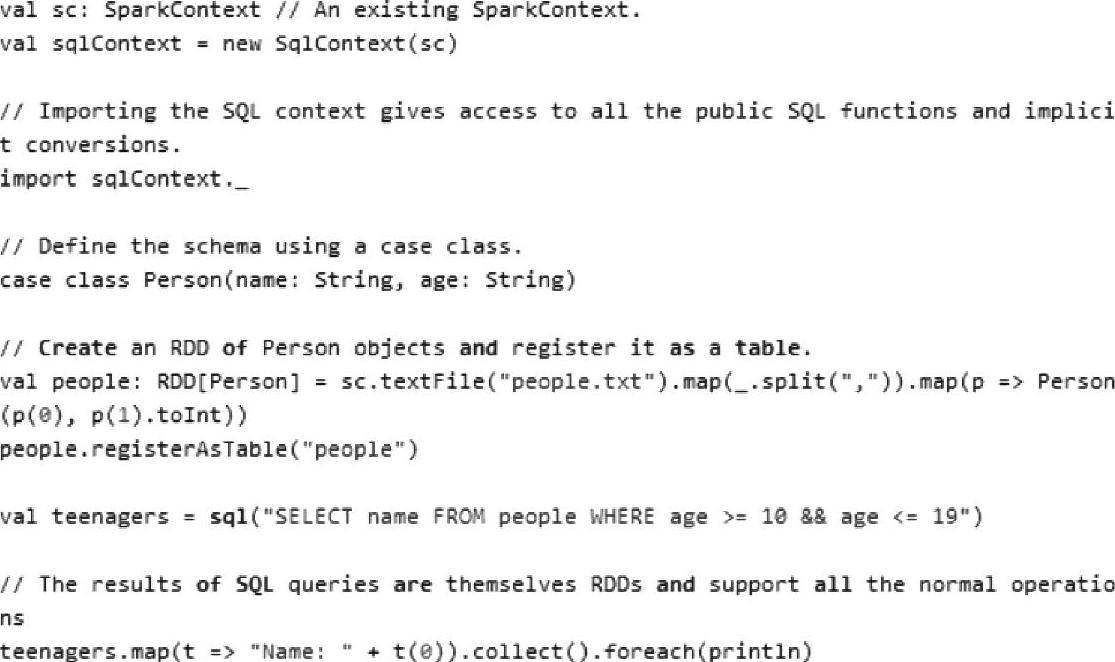
(1)在该案例中,首先初始化SqlContext实例对象,SqlContext包括Spark SQL执行的上下文与流程;定义并注册Table,定义Table的字段与类型,然后注册,注册实际上就是把Table的元数据存储在内存SimpleCatalog对象中。
SQLContext是SQL模块一个总的执行环境,在其内部包含了Catalog、SqlParser、Analy-zer、Optimizer、LogicalPlan、SparkPlanner、QueryExecution等。SQLContext对应的相关源码如下所示。

就是这些对象组成了Spark SQL的运行时,有静态的metadata存储,有分析器、优化器、逻辑计划、物理计划、执行运行时。下面我们结合前面的Spark SQL的示例继续探讨。
(2)在实例化SQLContext之后是构建RDD的代码,代码如下:
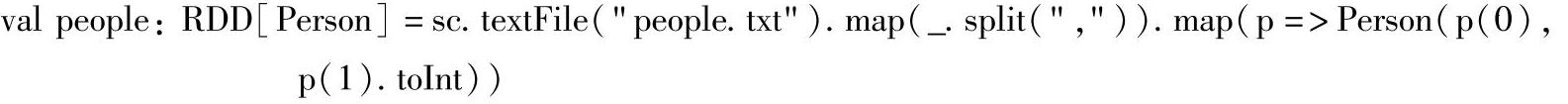
上述代码中通过sc的textFile()方法读取文件,并经过两次map transformation操作生成一个people RDD,由于import sqlContext._之后,把隐式转换函数createSchemaRDD引入了上下文中,因此RDD构建后对应转换成一个SchemaRDD。
SchemaRDD是SQL模块增加的一个RDD实现类,SchemaRDD在new出一个案例的时候需要两部分:SQLContext和逻辑执行计划,对应的源码如下所示。

下面详细描述如何构建SchemaRDD。
1)首先,从SchemaRDD的构建方法开始,将RDD隐式转换成SchemaRDD的隐式转换函数createSchemaRDD,在sqlContext中的源码如下所示。

在上面的createSchemaRDD()方法中,对people这个RDD主要做了三件事情:首先根据A,即Person这个case class(样例类),通过Scala反射出了类的属性,对于table(表)来说就是取到了各个column(判)。下面是根据给定的样本类反射得到属性集合的源码:

2)其次调用StructType的fromAttributes()方法生成一个包含这些属性的case class。

3)接下来调用RDDConversions.productToRowRdd()方法把RDD转化成一个RDD [Row]。

4)最后,通过new SchemaRDD语句构建出SchemaRDD实例。我们看一下在构建Sche-maRDD时,所需的构造参数逻辑执行计划,即LogicalRDD,LogicalRDD是LogicalPlan的子类,在Spark 1.1的时候,这里使用的是SparkLogicalPlan这个具体实现。

构建了逻辑执行计划后,createSchemaRDD()方法就可以构建出我们所需要的Sche-maRDD了,到这里为止,其实都是val people:RDD[Person]=sc.textFile("people.txt").map(_.split(",")).map(p=>Person(p(0),p(1).toInt))这一步发生的事情,结果就是得到了一个SchemaRDD。
(3)继续分析下一步的案例代码:people.registerAsTable("people"),这是SchemaRDD的一个方法,由于SchemaRDD实现了SchemaRDDLike这个特性(Trait),所以registerAsT-able这个方法需要在SchemaRDDLike这个类里找,在SchemaRDDLike类的registerAsTable()方法中可以看到真正注册的表(table)依赖的还是SQLContext,对应的源码如下:

registerAsTable()方法最终执行了SQLContext的registerRDDAdTable()方法,这种表的注册由于信息是在内存里维护的(下面可以看到目前是一个HashMap维护),所以存活时间在SQLContext所存在的生命周期内。查看registerRDDAdTable()方法的源码,如下所示:

可以看到,SQLContext在注册表的时候,使用了Catalog,这是Catalog类的一个实现SimpleCatalog类的实例,继续查看Catalog特质和SimpleCatalog类的源码(下面只是截取了Catalog特质和SimpleCatalog类的源码的一部分内容),如下所示。


上面这部分是package org.apache.spark.sql.catalyst.analysis包里的代码,Catalog是一个维护table信息的类,能把注册新表存储起来,对旧表能进行查询和删除。SimpleCatalog的实现则是把tableName和logicalPlan存放在了一个HashMap里。
(4)在转换好RDD并存储成表之后,接下来执行sql语句:val teenagers=sql("SE-LECT name FROM people WHERE age>=10&&age<=19"),下面继续对这行代码的执行进行深入分析。
1)将sql语句通过解析(SqlParse)生成Unresolved逻辑计划。
sql方法同样是SQLContext的方法,其源码如下:


在调用sql方法里的parseSql(sqlText)后,开始对用户传入的SQL语句进行语法解析。从Spark 1.2开始,SQL语句的语法会首先采用DDLParser的apply方法进行解析,而不是直接采用Spark 1.1时的SqlParser的apply方法进行解析。采用下面源码中的ddlParser进行解析,源码如下:
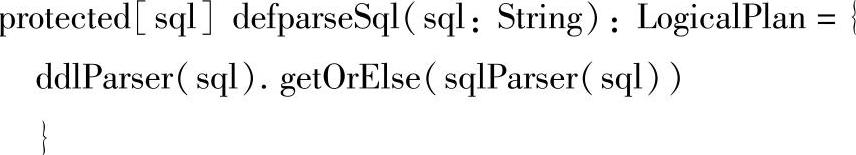
在DDLParser的apply方法中,最关键的一行代码是phrase(ddl)(new lexical.Scanner(input)),该语句就是调用phrase()函数,使用SQL语法表达式ddl,对词法读入器lexical读入的SQL语句进行解析。也可以说,只有输入的SQL语句先满足Lexical中定义的词法规则,它才会接下来使用phrase(ddl)进行语法解析。最终apply方法会返回一个Option[LogicalPlan]类型的值,apply方法的源码如下所示:

在语法解析的这行代码ddlParser(sql).getOrElse(sqlParser(sql))中,ddlParser(sql)解析返回的最终结果是Option[LogicalPlan]类型的值,当从这个Option里取值时,如果结果是None,会采用sqlParser(sql)解析产生的值。这里的sqlParser是SparkSQLParser,会继续调用他的父类的apply方法进行解析。这里我们不再深入追踪下去,大家可以参看Spark 1.2的源码部分。最终语法解析会返回一个未绑定的逻辑计划,下面是语法解析器的源码,在Ab-stractSparkSQLParser这个解析器的抽象类中,可以看到其apply方法返回的就是我们所需要的LogicalPlan,源码如下:

在经过语法解析得到LogicalPlan后,会继续使用Analyzer进一步解析。
2)通过Analyzer将Unresolved LogicalPlan转换成resolved LogicalPlan:Analyzer使用A-nalysis Rules,配合数据元数据Schema catalog,完善Unresolved LogicalPlan的属性而转换成resolved LogicalPlan。
首先分析Analyzer执行的入口点:这个阶段一开始,我们找不到Analyzer解析应该从哪里开始,由于Spark的源码使用Scala语言的Lazy变量,所以只有等到Job被提交后这一系列的plan才开始真正执行,我们知道,在Spark core中,Job执行的时候需要通过调用RDD的getDependencies方法来解决RDD的依赖关系,Spark SQL就借助了这一执行路径对未绑定的逻辑计划(Unresolved LogicalPlan)进行解析和优化。
打开SchemaRDD的getDependencies方法,我们看到了queryExecution.toRdd这句代码,在执行toRdd之前,前面rdd的转换、逻辑执行计划的生成、分析、优化工作都还没有实际进行数据的计算,直到执行了toRdd(lazy val toRdd:RDD[Row]=executedPlan.execute())语句之后,这一系列的plan才真正执行。SchemaRDD的getDependencies方法的源码如下:

在SchemaRDD的getDependencies方法中,构建SchemaRDD父依赖时,调用了queryEx-ecution的toRdd方法,而queryExecution的初始化是在SchemaRDDLike中实现的,最终还是要调用sqlContext.executePlan()方法,SchemaRDDLike中初始化queryExecution的源码如下:


在初始化queryExecution的源码中,继续调用sqlContext.executePlan()方法,该方法会生成一个QueryExecution对象,其中executPlan方法中传入的参数plan正是前面语法解析后生成的未绑定的逻辑计划,即构建SchemaRDD的第二个参数。executPlan方法的源码如下:
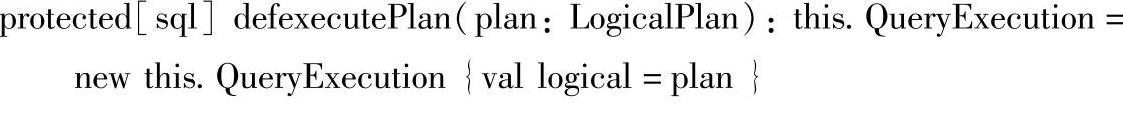
在executPlan方法中初始化QueryExecution成功后,此时最关键的部分来了,因为QueryExecution才真正调用了SQLContext对逻辑执行计划的处理,下面详细解析QueryExecu-tion的源码,源码如下:

在QueryExecution里,首先就是初始化Analyzer(解析器),对未绑定的逻辑计划进行解析。

Analyzer会使用Catalog和FunctionRegistry将UnresolvedAttribute和UnresolvedRelation转换为catalyst里全类型的对象。Analyzer里面有fixedPoint对象,一个Seq[Batch]属性。关键的概念如下。
●FixedPoint:相当于迭代次数的上限。
●Batch:批次,这个对象是由一系列Rule组成的,采用一个策略(策略其实是迭代几次的别名)。
●Strategy:最大的执行次数,如果执行次数在最大迭代次数之前就达到了Fixed Point(定点数),策略就会停止,不再应用了。
Analyzer的源码如下所示。

Analyzer解析主要是根据这些Batch里面定义的策略和Rule来对Unresolved的逻辑计划进行解析的。这里Analyzer类本身并没有定义执行的方法,而是要从它的父类RuleExecutor[LogicalPlan]寻找。(https://www.xing528.com)
RuleExecutor是执行Rule的执行环境,它会将包含了一系列Rule的Batch进行执行,这个过程都是串行的。具体的执行方法定义在RuleExecutor的apply里,对应的源码如下:


可以看到apply方法中包含了一个while循环,每个Batch下的Rules都对当前的plan进行作用,这个过程是迭代的,直到达到FixedPoint或者最大迭代次数。
到此,Analyzer对UnResolve Logical Plan进行解析,生成了Resolved Logical Plan。总结一下流程:
●先实例化一个Analyzer,这里使用的是它的子类SimpleAnalyzer。
●定义一些Batch,然后在RuleExecutor的环境下遍历这些Batch。
●执行Batch里面的Rules,每个Rule会对Unresolved Logical Plan进行Resolve,有些可能不能一次解析出,需要多次迭代,直到达到最大迭代次数或者达到FixedPoint。
这些Rules里比较常用的就是ResolveReferences、ResolveRelations、StarExpansion、GlobalAggregates、typeCoercionRules和EliminateAnalysisOperators。对于各个Rule所代表的具体含义,这里不再过多解释。
3)Optimizer(优化器)的实现和处理方式同Analyzer很相似,只是出于不同的处理阶段,职责不同。Optimizer也继承了RuleExecutor,并实现了一批规则,这批规则会同Analy-zer一样对输入的plan进行递归处理,下面从默认优化器的源码来详细分析优化器的执行过程,源码如下:


从以上源码中可知(Spark 1.2的源码),Optimizer里的Batch包含了4类优化策略:
●Combine Limits合并Limits。
●ConstantFolding常量合并。
●Decimal Optimizations。
●Filter Pushdown过滤器下推,每个Batch里定义的优化伴随对象都定义在Optimizer里。
Optimizer的优化策略不仅有对Logical Plan进行优化,而且对Logical Plan中的Expression也进行了优化,究其原理就是遍历树,然后应用优化的Rule,但是注意一点,对Logical Plan trans-from是先序遍历(pre-order),而对Expression transfrom是后序遍历(post-order)。
在这里简单介绍与Expression相关的类,主要是用到了references方法和outputSet方法,references方法主要是Logical Plan或Expression结点的所依赖的那些Expressions,而outputSet是Logical Plan所有的Attribute的输出,例如,Aggregate是一个Logical Plan,它的references方法的实现就是group by的表达式和aggreagate的表达式的并集去重。

对于Optimizer过程中用到的各个Rule的含义这里也不作详解了。总结一下整个流程:Optimizer采用基于规则(Rule)集的优化框架,将规则作用于Logical Plan及其内部的Ex-pression,从而达到优化逻辑计划的目的。其中主要的优化的策略总结起来是合并、列裁剪过滤器下推几大类。
4)Planner使用Planning Strategies(规划策略),对optimized LogicalPlan进行转换(transform),生成可以执行的SparkPlan(物理计划)。物理计划转换为RDD,通过调用SparkPlan.execute把树形结果的物理计划转换为RDD的DAG关系。
Optimizer对输入的Analyzed Logical Plan优化后,会有SparkPlanner来对Optimized Logi-cal Plan进行转换,生成Physical plans。在下面代码中,planner的初始化对象就是Spark-Planner对象。planner(optimizedPlan)方法实际上调用的是SparkPlanner的基类QueryPlan-ner的apply方法,然后会返回一个Iterator[PhysicalPlan]。

SparkPlanner继承了SparkStrategies,SparkStrategies继承了QueryPlanner。SparkStrategies包含了一系列特定的Strategies,这些Strategies是继承自QueryPlanner中定义的GenericStrate-gy,它定义接受一个Logical Plan,生成一系列的Physical Plan。


QueryPlanner是SparkPlanner的基类,定义了一系列的关键点,如GenericStrategy、plan-Later和apply。QueryPlanner的源码如下:

SQLContext类中的prepareForExecution变量其实是一个RuleExecutor[SparkPlan],它会调用RuleExecutor的apply方法对前面生成的PhysicalPlan应用Rule进行匹配,最终生成一个Spark Plan。Spark Plan是Catalyst里经过所有Strategies apply的最终的物理执行计划的抽象类,它只是用来执行Spark job的。
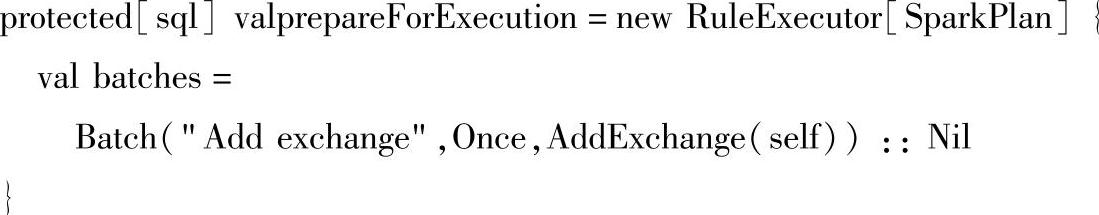
Spark Plan继承Query Plan[Spark Plan],里面定义了Spark SQL的sql语句启动执行的execute方法。

最后,execute方法执行完之后返回的是一个RDD,然后就可以使用RDD的transforma-tion和action来进行Spark SQL的真正执行了。
2.HiveQL语句的执行流程
图6-8是HiveQL的运行流程图:
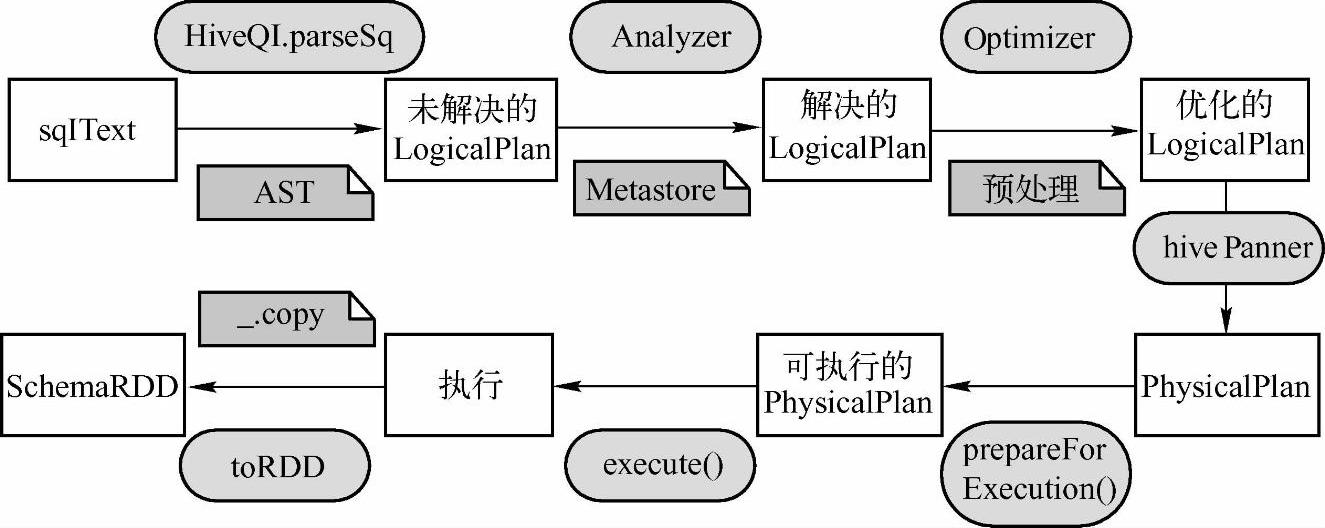
图6-8 HiveQL的运行流程图
在HiveQL的执行流程图中,首先根据dialect值,将sql语句或者hiveql语句解析成Un-resolved LogicalPlan,其次由Analyzer解析器将Unresolved LogicalPlan转换为Resolved Logical-Plan,然后由Optimizer对resolved LogicalPlan进行优化,生成Optimized LogicalPlan,接着使用hivePlanner将LogicalPlan转换成PhysicalPlan,最后将PhysicalPlan转换成SparkPlan(可执行物理计划),并执行该物理计划,生成SchemaRDD。
下面我们结合Spark的源代码来分析HiveQL语句的执行流程。
(1)首先sql语句或者hiveql语句通过HiveQl.parseSql(hqlQuery)解析成Unresolved LogicalPlan。
在HiveContext中,提供了sql()方法和hiveql()方法两种查询语句。首先来看sql查询语句的源码。

在上述源码中,if(dialect=="sql")时,会调用SQLContext的sql方法进行解析:if(di-alect=="hiveql")时,才会使用HiveQL解析器。在这里我们只拿HiveContext的hiveql方法来分析整个执行过程。
对于hiveql方法,它的语法解析采用的是HiveQl.parseSql(hqlQuery)。

其中parseSql方法会通过hqlParser(sql)继续调用AbstractSparkSQLParser的apply方法来进行解析,这里的hqlParser实际上是ExtendedHiveQlParser,它也是AbstractSparkSQLParser的子类。
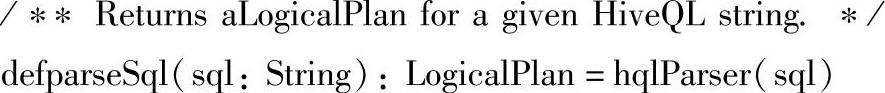
打开AbstractSparkSQLParser的apply方法,我们可以看到它的语法解析和SQL查询的语法解析几乎是一样的。这里不做详谈。

需要注意的是,在这个解析过程中,hiveql语句会通过getAst()方法获取AST树,然后根据AST树中的关键字继续进行解析。其中nativeCommands表示的是非select语句,这类语句的执行时间不会因为条件的不同而有很大的差异,基本上都能在较短的时间内执行完,这种情况下的语句会转换成command类型的LogicalPlan,而非nativeCommands。selec语句会通过NodeToPlan方法生成Logical Plan。

(2)Analyzer解析器结合Hive的元数据Metastore进行绑定,生成Resolved LogicalPlan。这里的Catalog的实例就是HiveMetastoreCatalog。

hiveql的解析过程和sql相似,这里关键是找到QueryExecution类,对于hiveql而言,它选取的是一个新的QueryExecution类,其他的解析过程和sql的解析一样。

(3)Optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan,除了Query相关的操作,其他的优化依然使用的是Hive自身的执行引擎。
(4)使用hivePlanner将LogicalPlan转换成PhysicalPlan,这里的hivePlanner继承自SparkPlanner并实现了Hivestrategies特质。


(5)通过prepareForExecution()方法将PhysicalPlan转换成SparkPlan(可执行物理计划),再调用executedPlan.execute()方法执行SparkPlan,最后使用map(_.copy)将结果导入SchemaRDD。

以上就是对Spark SQL中的sql语句和hiveql语句执行流程的源码解析,熟悉sql语句和hiveql的源码,对于我们在生产环境下使用Spark SQL遇到各种各样的问题时,能很方便地去查找问题原因。同时有利于我们对Spark SQL的性能调优。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。