



1.Hive简介
Hive是由Facebook提供的一款开源的ETL(Extraction-Transformation-Loading)工具,最初用于解决海量结构化的日志数据统计问题。它构建于Hadoop的HDFS和MapReduce之上,用于管理和查询结构化/非结构化数据的数据仓库。
Hive设计的目的是让SQL功能良好,但Java技能较弱的分析师可以查询海量数据,因为虽然Hadoop的HDFS和MapReduce已经能够很好地解决大数据的存储和分析问题,但是对于传统的数据分析人员来说,他们还面临着以下挑战:理解MapReduce计算模型、自行开发代码实现业务逻辑。Hive的出现完美地解决了传统数据分析人员所面临的问题:Hive使用了类SQL查询语法,最大限度地实现了和SQL标准的兼容;同时JDBC接口和ODBC接口也使得开发人员更易于开发应用。Hive使用HQL作为查询接口,使用HDFS作为底层存储系统,使用MapReduce作为计算引擎,可以与Pig、Presto等共享数据。可以说Hive应运而生,是当时唯一运行在Hadoop上的SQL-on-Hadoop工具。
当然Hive本身也有很多缺点,比如Hive的HQL表达能力有限,有些复杂的运算用HQL不易表达;HQL调优困难,粒度较粗;但最重要的一点是Hive自动生成MapReduce作业,而MapReduce在计算过程中大量的中间磁盘落地过程消耗了大量的I/O操作,降低了运行效率,这也直接导致了其他更加优秀的SQL-on-Hadoop工具的产生,比如Drill、Im-pala和我们前面提到过的Shark。但是对于Hive本身而言,如果它要改进效率,最关键的就是替换一个比MapReduce更高效的计算引擎,而Spark正好可以满足这一点,这也是Hive社区主推Hive on Spark技术的原因。
2.Hive的运行架构
Hive的运行架构如图6-6所示,下面从元数据存储、驱动(Driver)、支持接口和Ha-doop几个方面来分析Hive的运行架构。
(1)元数据存储仓库(Metastore):Hive的元数据存储在Metastore元数据存储仓库,像数据库和表的定义这些内容就属于元数据这个范畴。使用的存储引擎可以是Derby或者MySQL存储引擎,默认采用的是Derby存储引擎。
(2)驱动器(Driver):Driver负责将用户指令翻译转换为对应的MapReduce作业。用户通过接口提交Hive给Driver,由Driver进行HQL语句解析,此时从Metastore中获取表的信息,先生成逻辑计划,再生成物理计划,再由Executor生成Job交给Hadoop运行,然后由Driver将结果返回给用户。
●编译器(Compiler):编译器是Hive的核心,它由以下四个模块组成:a,语义解析器(ParseDriver),将查询字符串转换成解析树表达式;b,语法解析器(Semantic Analyzer),将解析树转换成基于语句块的内部查询表达式;c,逻辑计划生成器(Logical Plan Generator),将内部查询表达式转换为逻辑计划,这些计划由逻辑操作树组成,操作符是Hive的最小处理单元,每个操作符处理代表一道HDFS操作或者是MR作业;d,查询计划生成器(Query Plan Generator),将逻辑计划转化成物理计划(MR Job)。
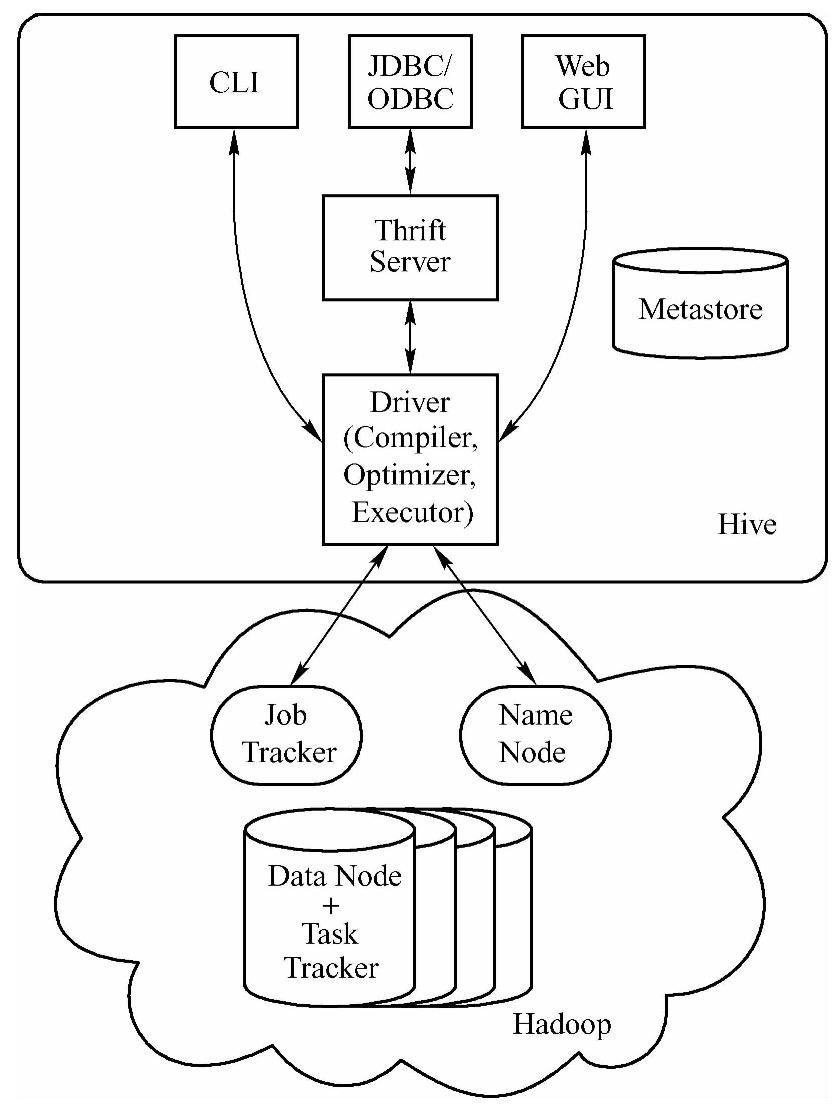
图6-6 Hive的运行架构
●优化器(Optimizer):优化器是一个演化组件,当前它的规则是列修剪,谓词下压。
●执行器(Executor):编译器将操作树切分成一个Job链(DAG),执行器会顺序执行其中所有的Job;如果Task链不存在依赖关系,可以采用并发执行的方式进行Job的执行。
(3)支持接口
●CLI(Common Line Interface):为命令行工具,是默认服务。启动方式为bin/hive或bin/hive--service cli。
●HWI(Hive WebInterface):为Web接口,可以通过浏览器访问Hive,默认端口为9999,启动方式为bin/hive--service hwi。
●ThriftServer:通过Thrift对外提供服务,默认端口为10000,启动方式为bin/hive--service hiveserver。
(4)Hadoop(https://www.xing528.com)
●用MapReduce进行计算。
●用HDFS进行存储。Hive中的所有数据存储在HDFS上,包括数据模型中的Table(表)、Partition(分区)、Bucket(桶);Hive的默认数据仓库目录是/user/hive warehouse,在hive-site.xml中由hive.metastore.warehouse.dir项定义;除了Ex-ternal Table,每个Table在数据仓库下都有一个相应的存储目录;当数据被加载至表中时,不会对数据进行任何转换,只是将数据移动到数据仓库目录;Table被删除时,表数据和元数据都被删除;External Table被删除时,元数据都被删除,表数据不删除;表中的一个Partition对应表下的一个子目录;每个Bucket对应一个文件。
至此,我们对Hive的运行架构进行了简单分析,Hive的运行过程概括为:首先由客户端提供查询语句,提交给Hive,Hive再交给Driver处理(1,编译器先编译,编译时要从Metastore中获取元数据信息,生成逻辑计划;2,生成物理计划;3,由Driver进行优化;4,Executor执行时对物理计划再进行分解成Job,并将这些Job提交给MR的JobTracker运行,提交Job的同时,还需要提取元数据信息关联具体的数据,这些元数据信息送到NameNo-de),JobTracker拆分成各个Task进行计算,并将结果返回或写入HDFS。
3.Hive on Spark的部署
(1)安装和配置Hadoop集群。在前面的第2章,我们已经成功搭建好了Hadoop集群,并配置了SSH免密码登录。这里不再讲解Hadoop集群的搭建。
(2)编译支持Hadoop和Hive版本的Spark。Spark的编译工具有很多,这里我们使用sbt来对下载的源码进行编译。在下载的Spark源码的HOME目录下,输入以下命令:
SPARK_HADOOP_VERSION=2.4.0 SPARK_YARN=true SPARK_HIVE=truesbt/sbt assembly
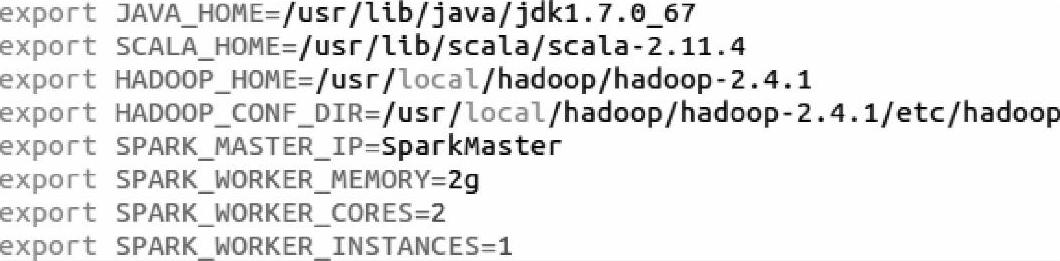
sbt会自动下载插件或依赖的jar包,运行完成之后会生成一个发布包:spark-1.1.0-bin-2.4.0.tgz。然后将spark-1.1.0-bin-2.4.0.tgz复制到集群的各个结点上,解压到指定目录后,修改Spark的/SPARK_HOME/conf目录下的spark-env.sh文件的信息,修改后的内容如下所示。
(3)测试Hive on Spark。可以在Spark Shell下对Hive on Spark的部署做测试。spark shell启动成功之后分别执行以下三行命令:

如果执行成功,说明Hive on Spark部署成功。
4.Hive on Spark的原理
在分布式系统中,由于历史原因,很多数据已经定义了Hive的元数据,Spark技术团队针对这一点,开发了Hive on Spark项目来兼容Hive。在这个框架中,HiveContext是Spark提供的用户接口,SparkSQL使用HiveContext很容易实现对Hive中数据的访问。而且HiveCon-text继承自SQLContext,所以在HiveContext的运行过程中除了override的函数和变量,还可以使用和SQLContext一样的函数和变量。像SQL一样,HiveSQL也是程序的入口,我们可以根据图6-7来简单比较一下SQLContext和HiveContext运行过程的异同。

图6-7 SQL和Hive SQL运行过程的比较
通过观察图6-7,我们可以知道,HiveContext的运行过程和SQLContext的运行过程基本一致,只是根据Hive本身的特征进行了符合Hive的重新实现,比如HiveContext的Catalog指向的是Hive Metastore,在Analyzer过程中使用的是新的Catalog和functionRegistry等。关于HiveQL的查询过程,会在下一节结合源码进行详细的解析,这里只做简单介绍,让大家有个印象。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。