



Spark SQL是Spark 1.0.0版本中新加入的组件,是Spark生态系统中最活跃的组件之一。它能够利用Spark进行结构化数据的存储和操作,结构化数据既可以来自外部结构化数据源(当前支持Hive、JSON和Parquet等操作,同时Spark 1.2版本开始对JDBC/ODBC提供支持)。
Spark SQL提供了方便的调用接口,用户可以同时使用Scala、Java、Python开发基于Spark SQL API的数据处理程序,并通过SQL语句来与Spark代码交互。当前Spark SQL使用Catalyst优化器来对SQL语句进行优化,从而得到更有效的执行方案,并且可以将结果存储到兼容Parquet格式的外部存储系统中。还有更重要一点,基于Spark的RDD,Spark SQL可以和Spark Streaming、GraphX、MLlib等子框架无缝集成,这样就可以在一个技术堆栈中对数据进行批处理、实时流处理和交互式查询等多种业务处理。
提到Spark SQL,不得不提Hive和Shark,Hive是Shark的前身,Shark是Spark SQL的前身。根据伯克利实验室提供的测试数据,Shark在基于内存计算的性能上比Hive高出100倍,即使是基于磁盘计算,它的性能也比Hive高出10倍,而Spark SQL的性能比Shark又高出一到两个数量级。
Hive是建立在Hadoop上的数据仓库基础构架,也是最早运行在Hadoop上的SQL-on-Hadoop工具。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive还定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户查询数据。同时,这个语言也允许熟悉MapReduce的开发者开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的、复杂的分析工作。正是由于Hive大大简化了对大规模数据集的分析门槛,所以它很快就流行起来,成为Hadoop生态系统重要的一份子。但是MapReduce在计算过程中大量的中间磁盘落地过程消耗了大量的I/O资源,这大大降低了SQL-on-Hadoop的运行效率,基于此,多种SQL-on-Hadoop工具出现了,其中表现最为突出的工具之一就是Shark。
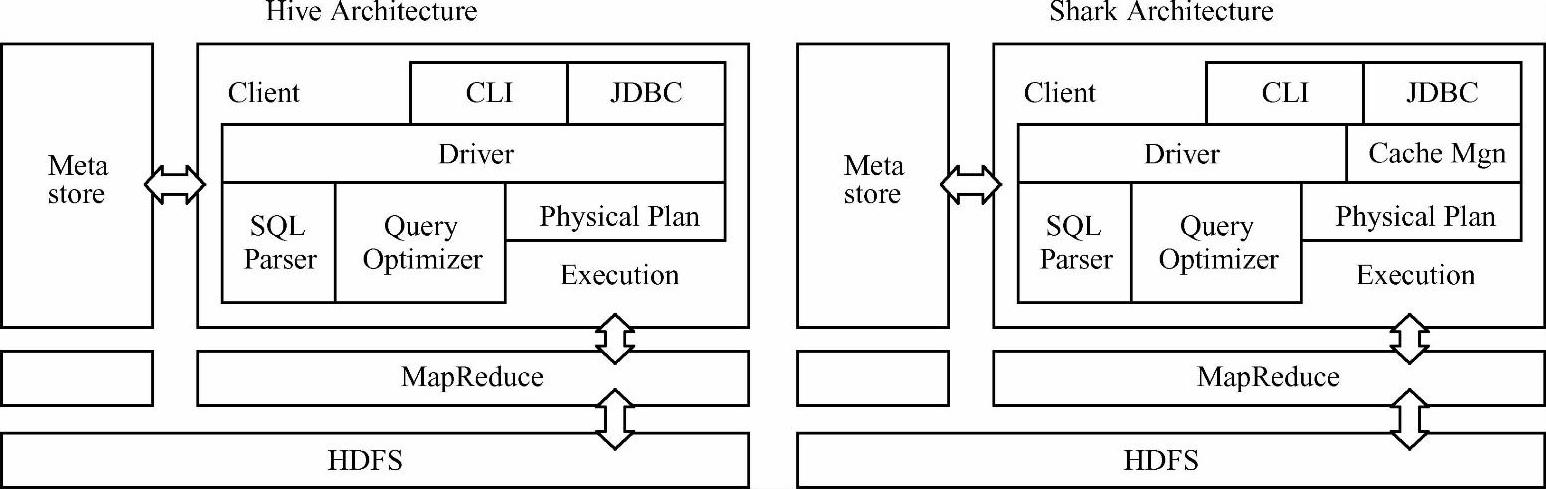
Shark也是由伯克利实验室技术团队开发的Spark生态环境组件之一,它扩展了Hive,并修改了Hive架构中的内存管理、物理计划、执行三个模块,并使之可以运行在Spark引擎上,大大加快了在内存和磁盘上的查询速度(如图6-1所示)。Shark直接建立在Apache/ Hive代码库上,所以它自然支持几乎所有Hive的特点。它支持现有的Hive SQL语言,Hive数据格式(SerDes,序列化和反序列化),用户自定义函数(UDF),调用外部脚本查询,并采用Hive解析器、查询优化器等。但正是由于Shark的整体设计架构对Hive的依赖性太强,难以支持其长远发展,比如不能和Spark的其他组件进行很好的集成,无法满足Spark的一栈式解决大数据处理的需求。Databricks公司在Spark Summit 2014上宣布Shark已经完成了其学术使命,全面转向Spark SQL。
 (https://www.xing528.com)
(https://www.xing528.com)
图6-1 Hive和Shark的架构
相比于Shark对Hive的过度依赖,Spark SQL在Hive兼容层面仅依赖HQL Parser(解析器)、Hive Metastore(元数据存储仓库)和Hive SerDe。也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。执行计划生成和优化都由Catalyst负责。借助Scala的模式匹配等函数式语言特性,利用Catalyst开发执行计划优化策略比Hive要简洁得多。此外,除了兼容HQL、加速现有Hive数据的查询分析以外,Spark SQL还支持直接对原生RDD对象进行关系查询。同时,除了HQL以外,Spark SQL还内建了一个精简的SQL Parser,以及一套Scala DSL。也就是说,如果只是使用Spark SQL内建的SQL方言或Scala DSL对原生RDD对象进行关系查询,用户在开发Spark应用时完全不需要依赖Hive的任何东西。当然,在重新实现Spark SQL代码的时候,Spark SQL技术人员还吸取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)等,这些优点使得Spark SQL无论在数据兼容性、性能优化、组件扩展等方面都得到了极大的改善。
值得一提的是,Hive社区也推出了一个Hive on Spark的项目——将Hive的执行引擎换成Spark(如图6-2所示),该图清晰地说明Shark的开发已经彻底结束,从Shark转向了Spark SQL;而Spark SQL作为一个新的SQL引擎从底层到上层都是基于Spark而实现的,另外Hive on spark则用于帮助Hive用户从Hadoop无缝转换到Spark。不过从目标上看,Hive on Spark更注重于针对Hive彻底地向下兼容性,而Spark SQL更注重于与Spark其他组件的互操作和多元化数据处理。

图6-2 Spark SQL和Hive on Spark
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。