



Shuffle的写操作(Shuffle writer)是将MaPTask操作后的数据写入到磁盘中,Spark中shuffle输出的ShuffleMapTask会为每个ReduceT ask创建对应的Bucket(桶),ShuffleMapTask产生的结果会根据设置的partitioner(分区)得到对应的BucketId(桶编号),然后填充到相应的Bucket中去。每个ShuffleMapTask的输出结果可能包含所有的ReduceTask需要的数据,所以每个ShuffleMapTask创建Bucket的数目是和ReduceTask的数目相等的(如图5-7所示)。

图5-7 Spark Shuffle流程
ShuffleMapTask创建的Bucket对应于磁盘上的一个文件,用于存储结果,此文件也被称为BlockFile。通过spark.shuffle.file.buffer.kb属性配置的缓冲区就是用来创建FastBuffered-OutputStream输出流的。如果在配置文件中设置了spark.shuffle.consolidateFiles属性为true,则ShuffleMapTask所产生的Bucket就不一定单独对应一个文件了,而是对应文件的一部分,这样做会大量减少产生的BlockFile文件数量(如图5-8所示)。
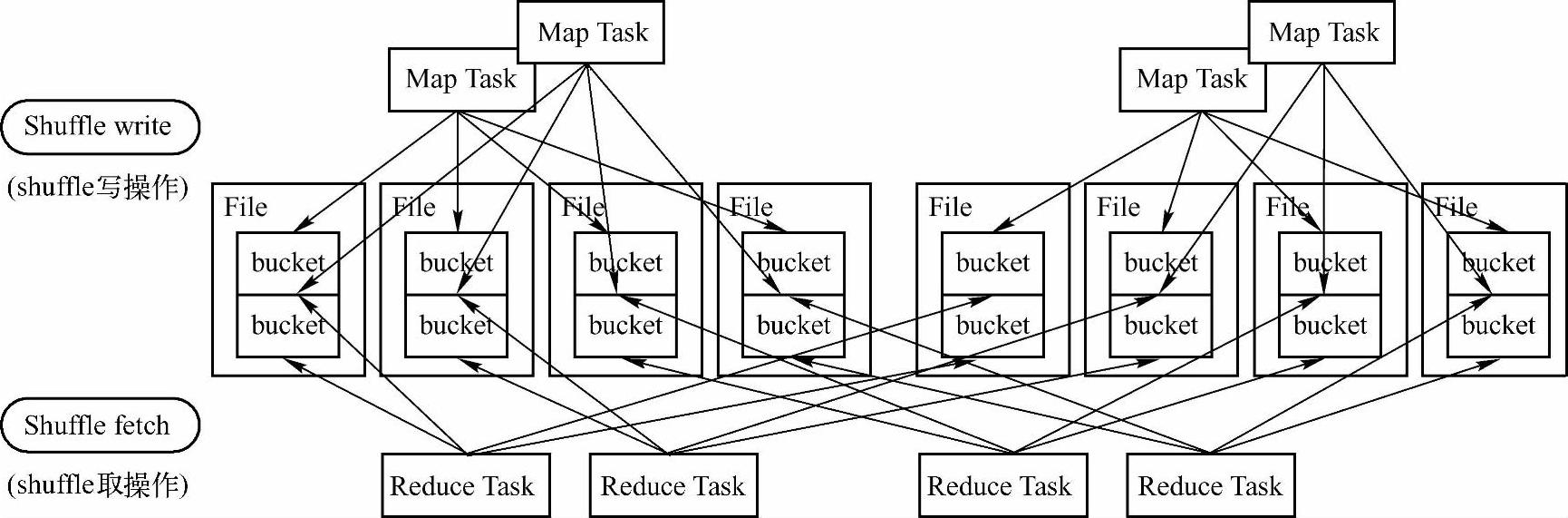
图5-8 shuffle文件聚合示意图
ShuffleMapTask在某个结点上第一次执行时,会为每个ReduceTask创建一个输出文件,并把这些文件组织成ShuffleFileGroup,当这个ShuffleMapTask执行完后,当前创建的Shuffle-FileGroup可以释放掉,进行循环利用。当又有ShuffleMapTask在这个结点上执行时,不需要创建新的输出文件,而是在上次的ShuffleFileGroup中已经创建的文件里追加写一个Segment(片段),如果当前的ShuffleMapTask还没执行完,此时又在此结点上启动了新的Shuf-fleMapTask,那么新的ShuffleMapTask只能又创建新的输出文件再组成一个ShuffleFileGroup来进行结果输出的。
下面我们结合Spark中ShuffleMapTask的源代码来分析一下Shuffle的写操作。
(1)首先在ShuffleMapTask的runTask()方法中,通过SparkEnv.get.shuffleManager这行代码生成一个ShuffleManager实例对象,ShuffleManager对象调用getWriter方法得到Shuffle-Writer对象,由于ShuffleWriter本身是个Trait(特质),具体执行的时候使用的是它实现的子类,这里采用的是ShuffleWriter的默认值HashShuffleWriter。通过HashShuffleWriter的writ-er方法把RDD的计算结果写入磁盘。(https://www.xing528.com)


(2)继续跟踪HashShuffleWriter类的writer()方法,些方法会判断要不要在Map端对数据进行聚合操作。最后会继续调用ShuffleWriterGroup的writers(bucketId)得到一个Disk-BlockObjectWriter对象。然后继续调用DiskBlockObjectWriter的writer()方法来完成RDD数据的磁盘写入。

(3)在DiskBlockObjectWriter的writer()方法中,会调用系统配置的序列化器把数据写磁盘。系统默认的序列化器是JavaSerializationStream。

以上内容即是结合源代码对Spark中Shuffle的写操作过程进行的一些分析。下面我们继续探讨Shuffle的读操作。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。