



Spark Standalone运行模式是一种典型的Master-Slave架构,在这种模式下,主要包括三个组件:Master、Worker、Driver。这里我们指定的是Driver运行在客户端的Client模式。
(1)首先我们会在spark的sbin目录下使用“./start-all”脚本来启动集群:
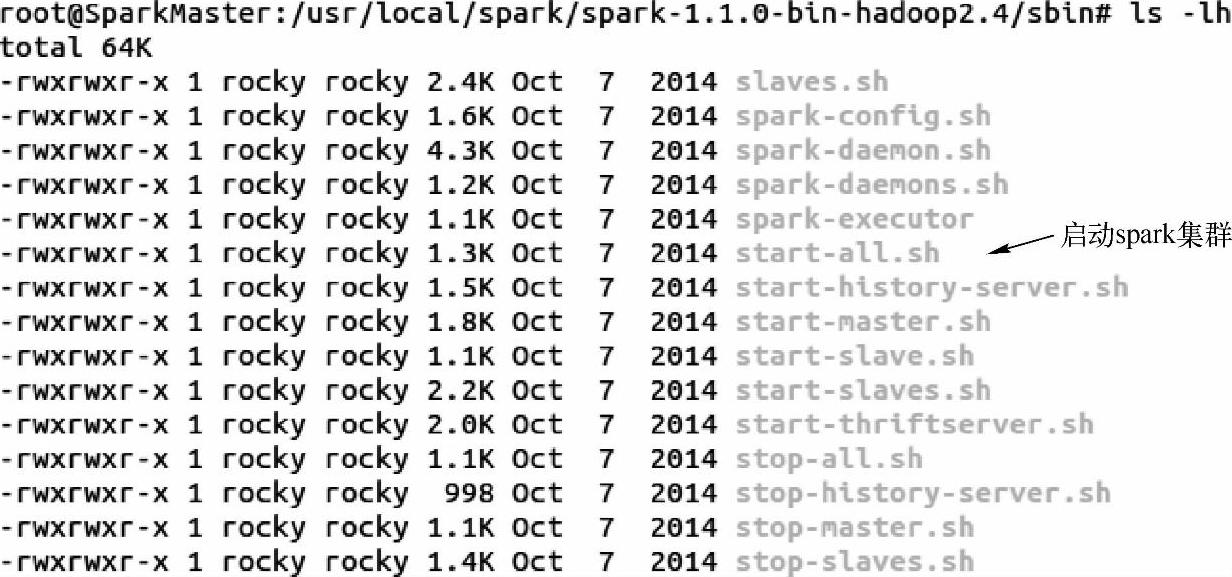
1)用vim打开start-all.sh这个脚本文件,会看到在文件里接着会调用“start-master.sh”和“start-slaves.sh”脚本。

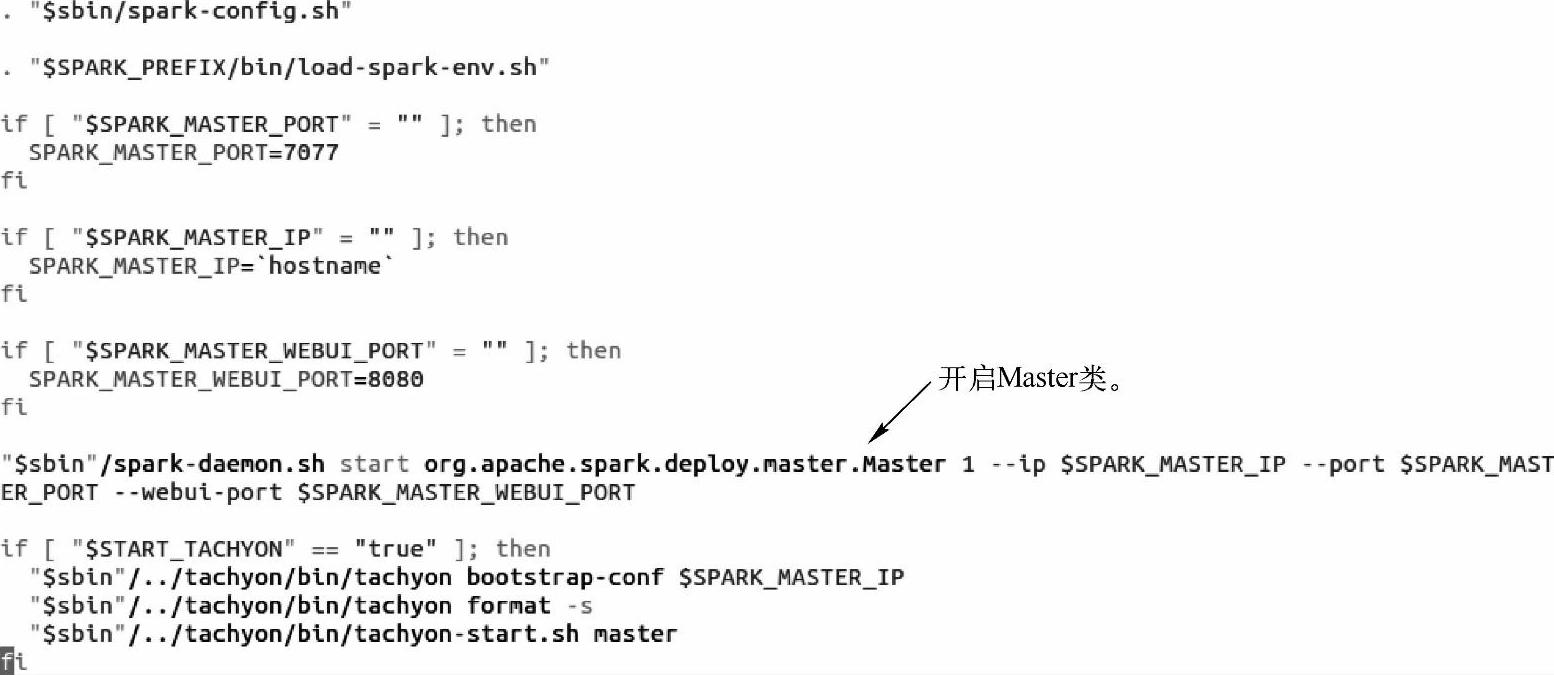
2)在start-master.sh脚本文件中,会启动org.apache.spark.deploy.Master类来完成集群Master结点的启动。
3)而在start-slaves.sh脚本文件中会经过连续两个脚本的调用,开启与Master对应的org.apache.spark.deploy.worker.Worker类。

这时候,Spark集群的Master结点和Worker结点已经全部开启,Worker会向Master完成注册,并定时向Master发送心跳(heartbeat),使得Master结点可以知道该Worker结点属于活跃状态。关于Master和Worker之间的AKKA通信,我们会在5.5小节讲AKKA通信框架的时候专门分析。
(2)当我们在命令终端用Spark Submit工具向集群提交Spark Application的时候,首先会调用spark的bin目录下的spark-submit脚本文件。
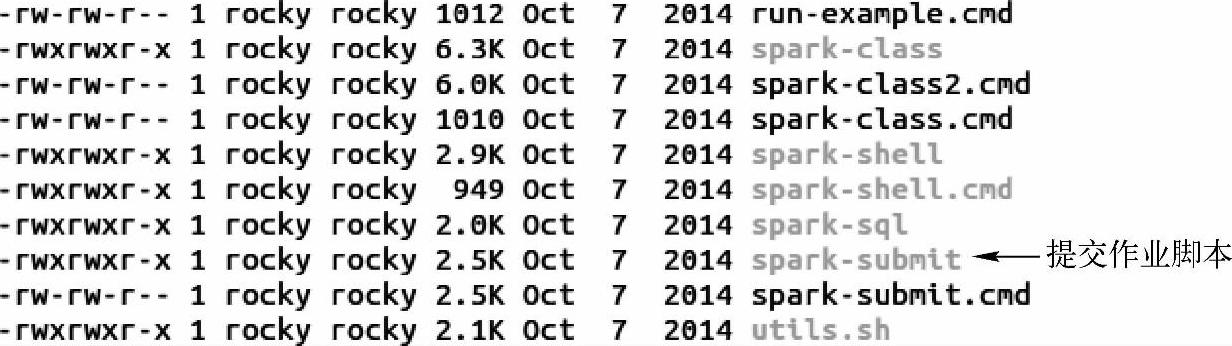
1)用vim打开spark-submit脚本文件,我们知道这个脚本最终会启动org.apache.spark. depoloy.SparkSubmit类。
2)在SparkSubmit对象的main方法中,首先会获取spark-submit的参数列表,根据参数列表创建启动环境。然后完成Spark Application的提交。

3)我们打开createLaunchEnv方法,由于我们选择的是Client模式,所以最终选择的childMainClass是我们写的Spark应用的mainClass。


4)我们进入SparkSubmit对象的launch方法,发现它最终会通过Java语言的反射机制启动Spark应用mainClass的main方法。

(3)每个Spark应用都会对应着唯一的一个SparkContext,当调用mainClass的main方法时,也完成了SparkContext的初始化。SparkContext是Spark应用创建时的上下文对象,是一个重要的入口类,在其内部会进行一系列的重要操作,其中最重要的是创建TaskScheduler和DAGScheduler实例。
1)创建SparkConf对象来管理spark应用的属性设置。SparkConf类比较简单,是通过一个HashMap容器来管理key/value类型的属性。

2)在SparkContext类中对于创建的SparkConf会进行验证和克隆,一旦SparkConf的设置最终确定,在Spark程序运行时是不会改动的。

3)在SparkContext类中创建LiveListenerBus监听器。

这是典型的观察者模式(如图5-3所示),SparkListener向LiveListenerBus类注册不同类型的SparkListenerEvent事件,SparkListenerBus会遍历它的所有监听者SparkListener,然后找出事件对应的接口进行响应。
4)创建SparkEnv运行环境。SparkEnv类用于封装所有Spark运行时的环境对象,如Se-rializer、ActorSystem、BlockManager、MapOutputTrackerMasterActor、HttpFileServer等一系列对象。

5)创建SparkUI。通过SparkUI方便我们观察Spark集群的运行情况和Spark应用运行时的状况。


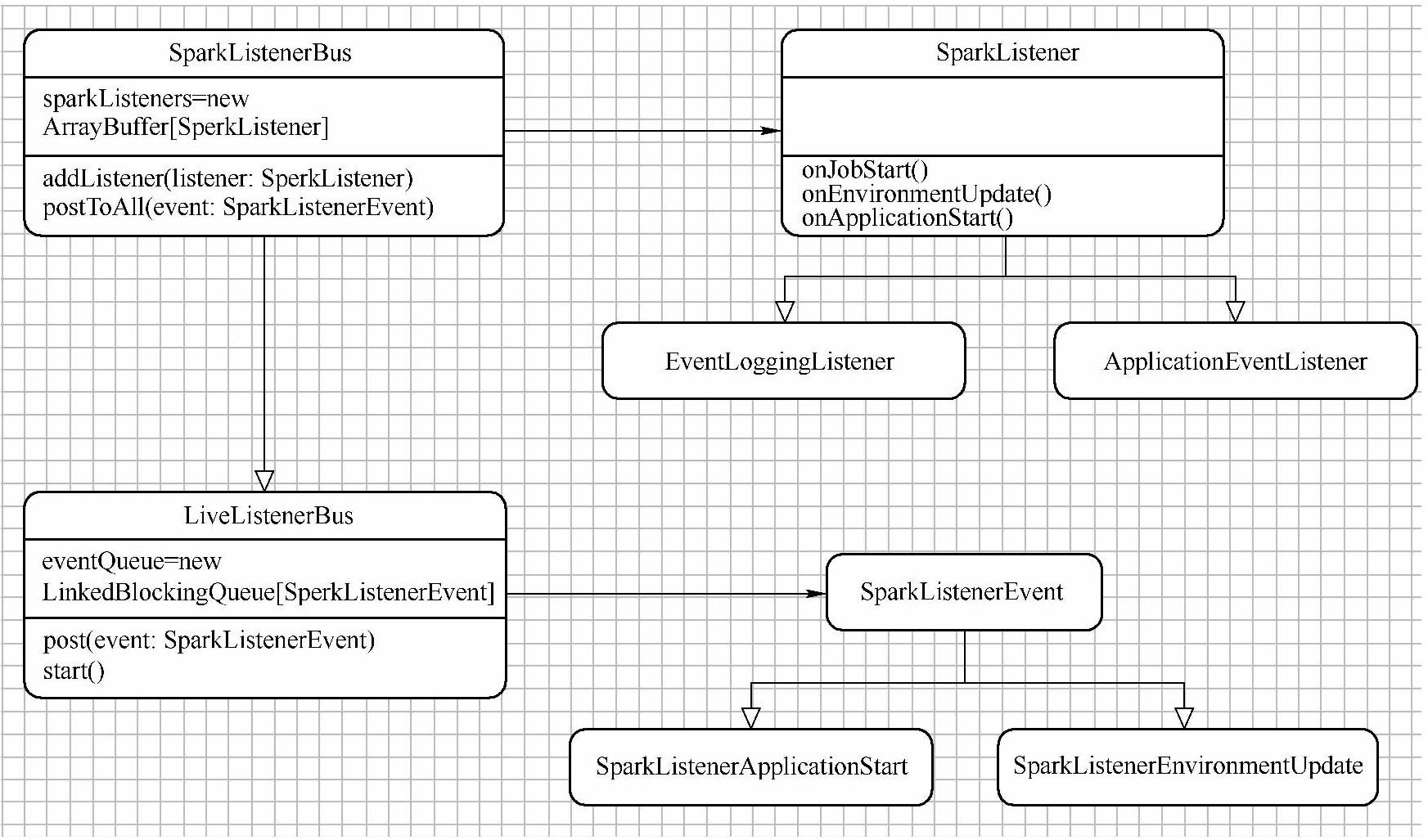
图5-3 观察者模式
6)在SparkUI对象initialize()方法中,attachTab方法中添加的对象正是我们在Spark Web页面中看到的那些标签。

7)在SparkUI的create方法中,注册了JobProgressListener监听器,负责监听Job运行时的变化及时地展示到Sparkweb页面上。
 (https://www.xing528.com)
(https://www.xing528.com)
8)添加EventLoggingListener监听器,这个默认是关闭的,可以通过spark.eventLog.enabled配置开启。它主要功能是以json格式记录发生的事件。

9)加入SparkListenerEvent事件。往LiveListenerBus中加入了SparkListenerEnvironmen-tUpdate、SparkListenerApplicationStart两类事件,对这两种事件监听的监听器就会调用onEn-vironmentUpdate、onApplicationStart方法进行处理。

10)创建了TaskScheduler和DAGScheduler调度器。

11)TaskScheduler是通过不同的SchedulerBackend来调度和管理任务,它包含资源分配和任务调度。它实现了FIFO调度和FAIR调度,基于此来决定不同jobs之间的调度顺序。在SparkContext的createTaskScheduler方法中,会根据不同的部署方式选择不同的Scheduler-Backend。我们这里的master选取的是Spark Standalone运行模式,模式匹配对应的是“SPARK_REGEX(sparkUrl)”,首先这里的scheduler是TaskScheduler的实现子类Task-SchedulerImpl,schedulerbackend选择的是SparkDeploySchedulerBackend,它是CoarseGrained-SchedulerBackend的子类。

(4)SparkDeploySchedulerBackend是Standalone模式下的SchedulerBackend。它装备好启动Executor的必要参数后创建AppClient,可以向Standalone的Master注册Application,然后Master会通过Application的信息为它分配Worker,包括每个worker上使用CPU core的数目等。
1)在SparkContext初始化的过程中,TaskSchedulerImpl的start方法也被调用。打开TaskScheduler的start方法我们看到它会继续调用SparkDeployScheduleBackend的start方法。

2)在SparkDeploySchedulerBackend的start方法中,会初始化Appclient类,完成Spark应用向Master的注册。


(5)AppClient向Master提交Application。
1)AppClient是Application和Master交互的接口。它包含一个类型为org.apache.spark. deploy.client.AppClient.ClientActor的成员变量actor。它负责了所有的与Master的交互。当AppClient调用start方法后,会启动一个ClientActor。

2)ClientActor首先向Master注册Application。如果超过20s没有接收到注册成功的消息,那么会重新注册;如果重试超过3次仍未成功,那么本次提交就以失败结束了。


3)如果Application注册成功,ClientActor的receiveWithLogging方法(消息循环系统)会受到来自Master发送的RegisteredApplication信息,并进行处理。


(6)Master接收到AppClient的registerApplication的请求后,处理逻辑如下:
1)Master接受到ClientActor发送的Application注册信息后,会调用scheduler方法为待分配的Application分配资源,在每次有新的Application加入时都会调用scheduler方法。

2)在scheduler方法这种为Application分配资源选择worker(executor)有两种策略:
第一是尽量的“打散”,即一个Application尽可能多的分配到不同的结点。这个可以通过设置spark.deploy.spreadOut来实现。默认值为true,即尽量的打散;第二是尽量的集中,即一个Application尽量分配到尽可能少的结点。对于同一个Application,它在一个worker上只能拥有一个executor,当然了,这个executor可能拥有多于1个core。对于第一种策略,任务的部署会慢于第二种策略,但是GC(Garbage Collection)的时间会更快。其主要逻辑如下:


3)在选择了worker和确定了worker上的executor需要的CPU core数后,Master会调用launchExecutor(worker:WorkerInfo,exec:ExecutorInfo)向Worker发送请求,向AppClient发送executor已经添加的消息。同时会更新master保存的worker的信息,包括增加executor,减少可用的CPU core数和memory数。Master不会等到真正在worker上成功启动executor后再更新worker的信息。如果worker启动executor失败,那么它会发送FAILED的消息给Mas-ter,Master收到该消息时再次更新worker的信息即可。这样是简化了逻辑。

(7)Worker根据Master的资源分配结果来创建Executor。
1)Worker接收到来自Master的LaunchExecutor的消息后,会创建org.apache.spark.deploy. worker.ExecutorRunner。Worker本身会记录本身资源的使用情况,包括已经使用的CPU core数,memory数等;但是这个统计只是为了web UI的展现。Master本身会记录Worker的资源使用情况,无需Worker自身汇报。Worker与Master之间传送的心跳的目的仅仅是为了汇报自己处于活跃状态,不会携带其他的信息。


2)接下来就启动org.apache.spark.deploy.ApplicationDescription中携带的org.apache.spark. executor.CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后,会首先通过传入的driverUrl这个参数向在org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend::DriverActor发送RegisterExecutor(executorId,hostPort,cores),DriverActor会回复RegisteredEx-ecutor,此时CoarseGrainedExecutorBackend会创建一个org.apache.spark.executor.Executor。至此,Executor创建完毕。


免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。