



Spark的作业和任务调度系统是Spark的核心,Spark的性能如此优良的最重要的原因就是它的作业和任务调度系统的设计非常精良和扩展性好,使得它对低层到顶层的各个模块之间的调用和处理显得游刃有余。Spark有多种运行模式,这里为了清晰明了的讲清楚Spark的调度系统,我们选择Spark自身的Standalone模式,并且是Driver运行在客户端的Client模式来讲解。
我们先通过图5-2从整体上对Spark的作业和任务调度系统做一下分析:
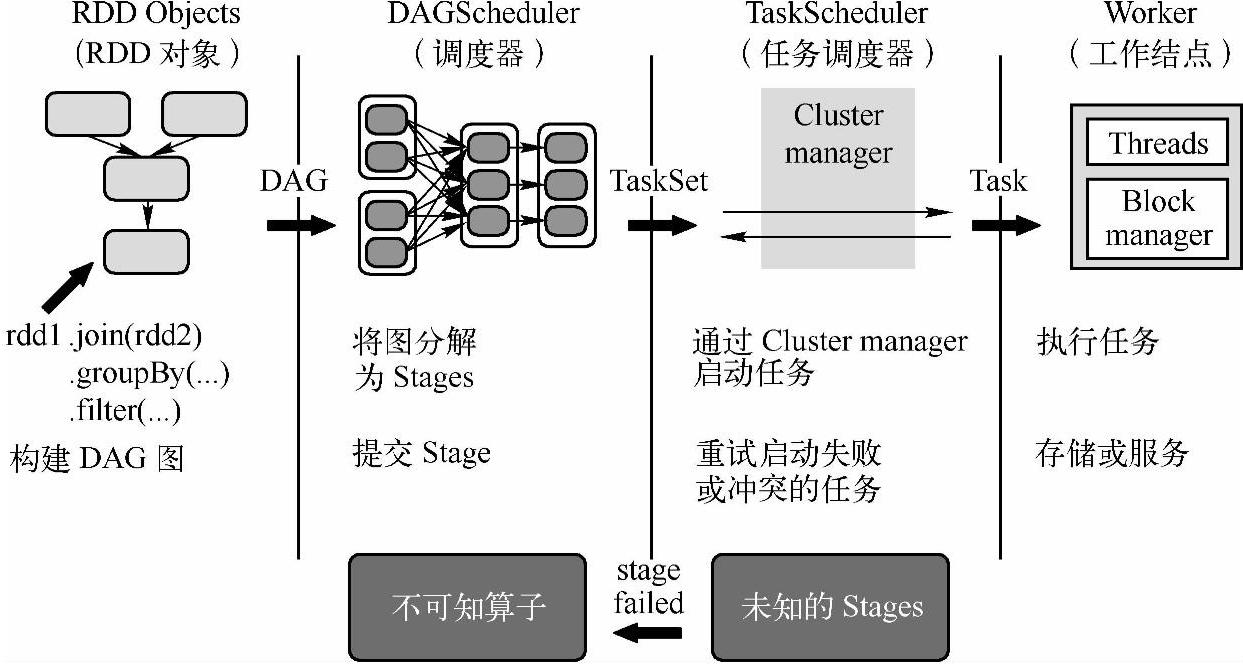
图5-2 Spark的作业和任务调度系统
(1)Spark应用程序进行各种RDD的transformation操作的计算,最后通过RDD的ac-tion操作触发Job。图5-2中的join操作、groupBy操作和filter操作都是transformation操作。
(2)提交之后首先根据RDD之间的依赖关系构建DAG图(Directed Acyclic Graph,有向无环图),比如图5-2中groupBy操作依赖于join操作生成的RDD,filter操作依赖于groupBy操作生成的RDD,这种RDD的依赖关系就形成了一个有向无环图,即DAG图。然后DAG图提交给DAGScheduler进行解析,就进入了DAGScheduler阶段。(https://www.xing528.com)
(3)DAGScheduler是面向Stage的高层级的调度器,DAGScheduler把DAG拆分成很多的Tasks,每组的Tasks都是一个Stage,解析时是以Shuffle为边界反向解析构建Stage(Stage之间也有依赖关系),每当遇到Shuffle就会产生新的Stage,然后以一个个TaskSet(TaskSet等同于Stage,是对Stage的一次封装)的形式提交给底层调度器TaskScheduler。另外DAGScheduler需要记录哪些RDD被存入磁盘等物化动作,同时要寻求Task的最优化调度,例如数据本地性等。DAGScheduler还需要监视因为Shuffle输出导致的失败,如果发现这个Stage失败,可能就要重新提交该Stage。
(4)一个TaskScheduler只为一个SparkContext实例服务,TaskScheduler接受来自DAG-Scheduler发送过来的TaskSet,TaskScheduler收到TaskSet后负责把任务集以Task的形式一个个分发到集群Worker结点的Executor中去运行。如果某个Task运行失败,TaskScheduler 要负责重试,另外如果TaskScheduler发现某个Task一直未运行完,就可能启动同样的任务运行同一个Task,哪个任务先运行完就用哪个任务的结果。
(5)Executor收到TaskScheduler发送过来的Task后,以多线程的方式运行,每一个线程负责一个Task。Task运行结束后要返回给DAGScheduler,不同类型的Task,返回的方式也不同。ShuffleMapTask返回的是一个MapStatus对象,而不是结果本身;ResultTask根据结果大小的不同,返回的方式又可以分为两类,这个在下面的5.2.5小节里再详细讲。
通过上面的五个步骤,对Spark的作业和任务调度系统整体上有了初步的认识后,下面我们结合Spark 1.2的源代码一步步深入地分析其工作原理和流程。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。