



(1)首先需要部署一个Hadoop Yarn集群供该模式使用。由于在前面的第2章我们已经进行了Hadoop集群的具体安装,这里只需在Hadoop集群的安装包下更新与Yarn有关的文件信息。
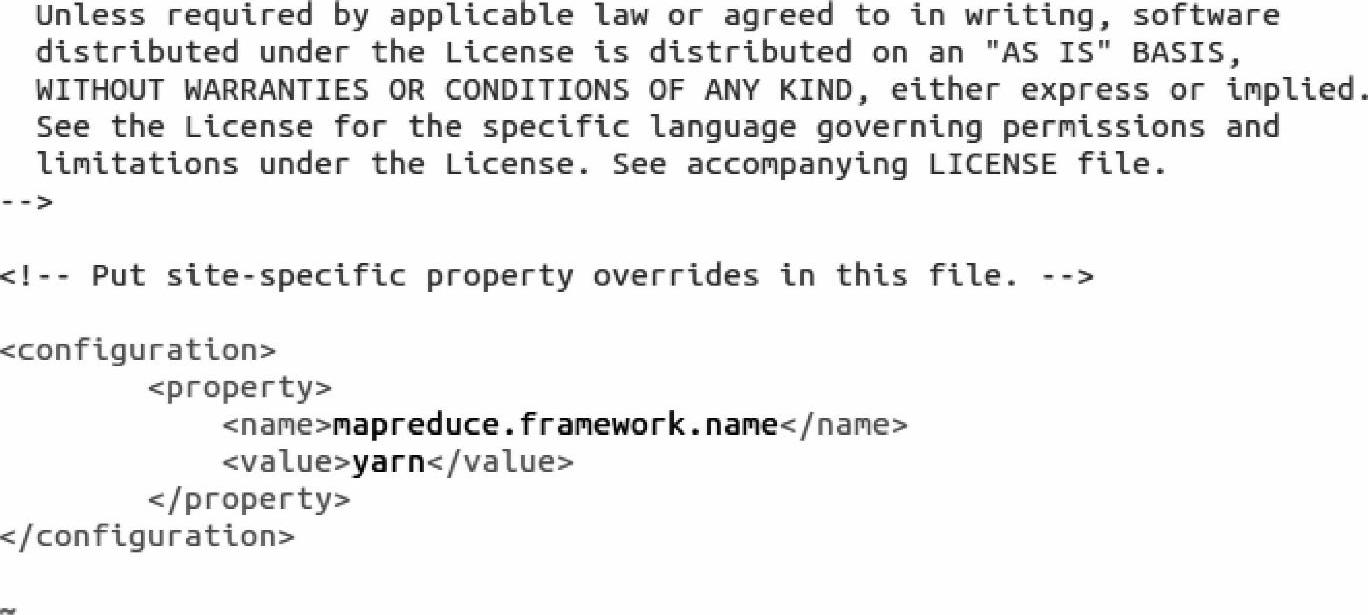
1)用vim命令打开mapred-site.xml文件,配置一个name为mapreduce.framework.name value为yarn的属性,具体内容如下:
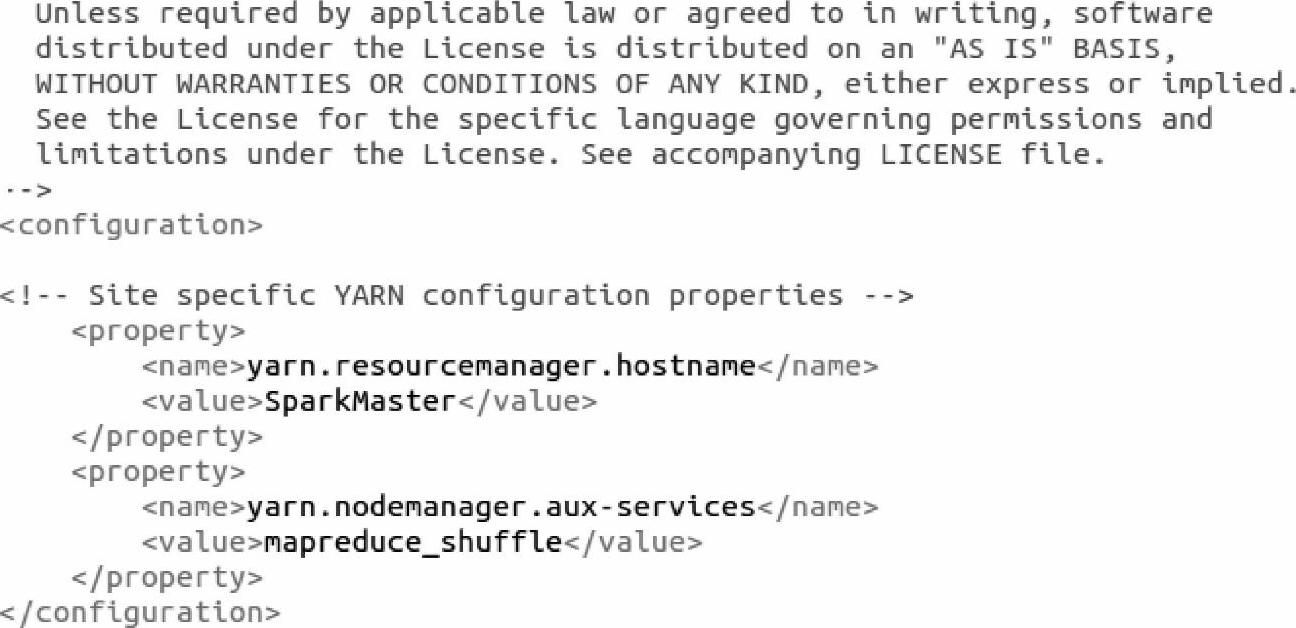
2)同样配置yarn-site.xml文件中的两个属性,Yarn的resourcemanager位于hostname (主机名)为SparkMaster的结点上,也就是Hadoop集群的主结点上(我们的Hadoop集群和Spark集群在安装搭建时,他们的Master结点都在主机名为SparkMaster的机器上)。对于第二个属性名为yarn.nodemanager.aux.services的配置,是因为在Yarn资源管理框架下运行MapReduce程序时,需要让各个NodeManager在启动时加载shuffle server,shuffle server实际上是Jetty/Netty Server,Reduce Task通过该server从各个NodeManager上远程复制Map Task产生的中间结果。上面增加的两个配置均用于指定shuffle serve。在这里我们需要强调的一点是当我们使用Yarn这个资源管理框架的时候,就是为了可以同时使用多套计算框架来执行各自的任务,所以这里的第二个属性配置针对的是MapReduce计算框架。具体配置内容如下:
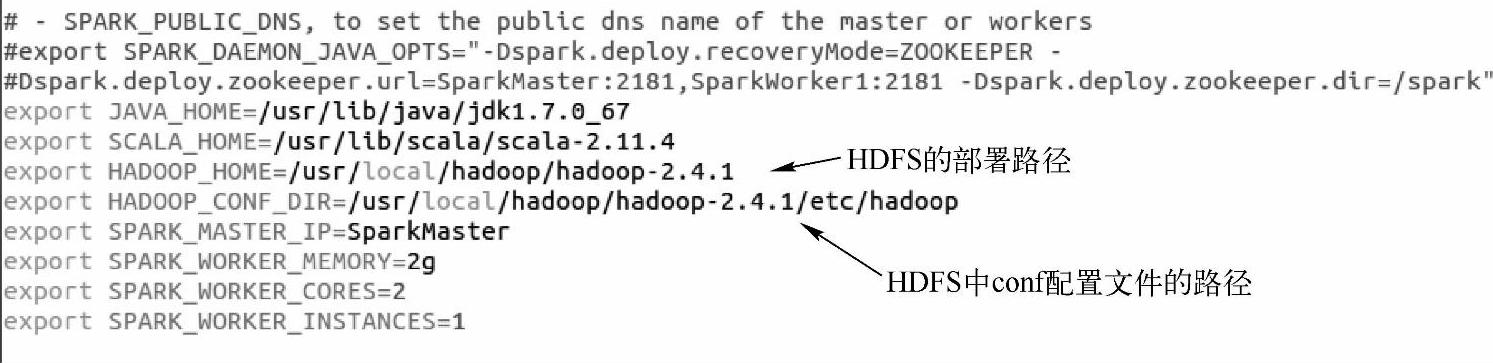
(2)部署Spark on Yarn模式的的时候,仅需要在一台可以提交Spark Application(应用程序)到Yarn集群的客户端结点部署Spark即可,不用每台机器都部署Spark。在客户端的配置文件中需要设置Yarn和HDFS的相关属性,因为需要读取Yarn集群的配置文件。修改$SPARK_HOME/conf/spark-env.sh这个文件中HADOOP_HOME和HADOOP_CONF_DIR这两个环境变量的值,修改的结果如下所示。
(3)Spark自身的Master结点和Worker结点不需要启动,但是Spark的部署包必须是基于对应的Yarn版本正确编译后的,否则会出现Spark和Yarn的兼容性问题。对于Spark的部署包,我们既可以在Spark的官网上下载编译后的安装包,也可以用SBT的方式来打包。比如我们现在使用的是Hadoop 2.4.1,可以在下载下来在Spark根目录下使用如下命令进行打包:
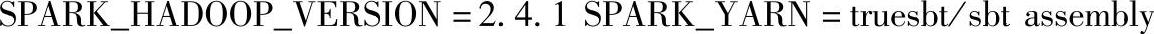
(4)Yarn-Cluster模式还可以通过在$SPARK_HOME/conf目录下的spark-default.conf 文件里或者提交应用的工具(如spark-submit)的附加参数列表写入一些与Yarn有关的属性,来调整Yarn-cluster模式下的运行行为。如果修改$SPARK_HOME/conf/spark-de-fault.conf这个文件,需要配置的可以有如下参数:
1)spark.yarn.applicationMaster.waitTries:ResourceManager(集群资源管理器)等待Spark AppMaster启动的次数,也就是SparkContext初始化次数。超过这个数值,启动失败。默认值是10次。
2)Spark.yarn.submit.file.replication:spark应用程序的依赖文件上传到HDFS上时,在HDFS中存储的副本,默认值是三份。
3)spark.yarn.scheduler.heartbeat.interval-ms:Spark AppMaster发送心跳信息给YARN的ResourceManager的时间间隔。默认值是5000ms。(https://www.xing528.com)
4)Spark.yarn.preserve.staging.files:在Spark应用程序结束后,是否还保存上传的依赖文件。当这个选项的值设置为true时,在Job(作业)结束后,会将上传的依赖文件保留而不是删除。
5)Spark.yarn.max.executor.failures:导致应用程序宣告失败的最大executor失败数。默认值是两倍于executor数。
配置完成后,将Spark部署文件放置到Yarn所在的结点中。
(5)启动yarn集群。进入Hadoop安装包的sbin目录下,使用./start-yarn.sh命令启动Yarn集群,在shell命令终端的演示代码如下:
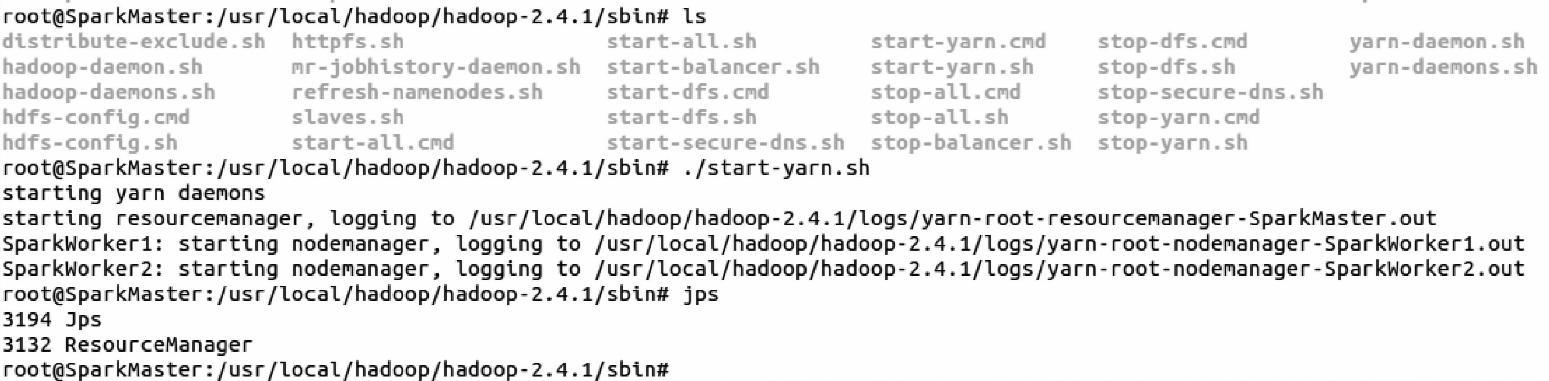
从上面的运行结果中,我们看到了一个进程pid为3132的ResourceManager进程,这说明Yarn集群已经启动。
(6)我们使用Spark Submit的方式进行Spark Application(这里的样例使用Spark官方提供的SparkPi例子)的提交,shell命令端的运行代码如下:

提交过后,可以在Yarn的ResourceManager进程对应的WebUI中查看启动的Application(Spark应用程序)的运行情况(如图4-8所示)。
运行结束后,Yarn-Cluster的运行结果会保存在ApplicationMaster所在结点中(也就是Driver所在的工作结点)的工作目录中的stdout子目录中。可以通过命令“find.-name“*stdout””查找。另外,Application日志会在任务结束后汇集到HDFS文件系统中,可以通过“yarn logs-applicationId”命令查看。
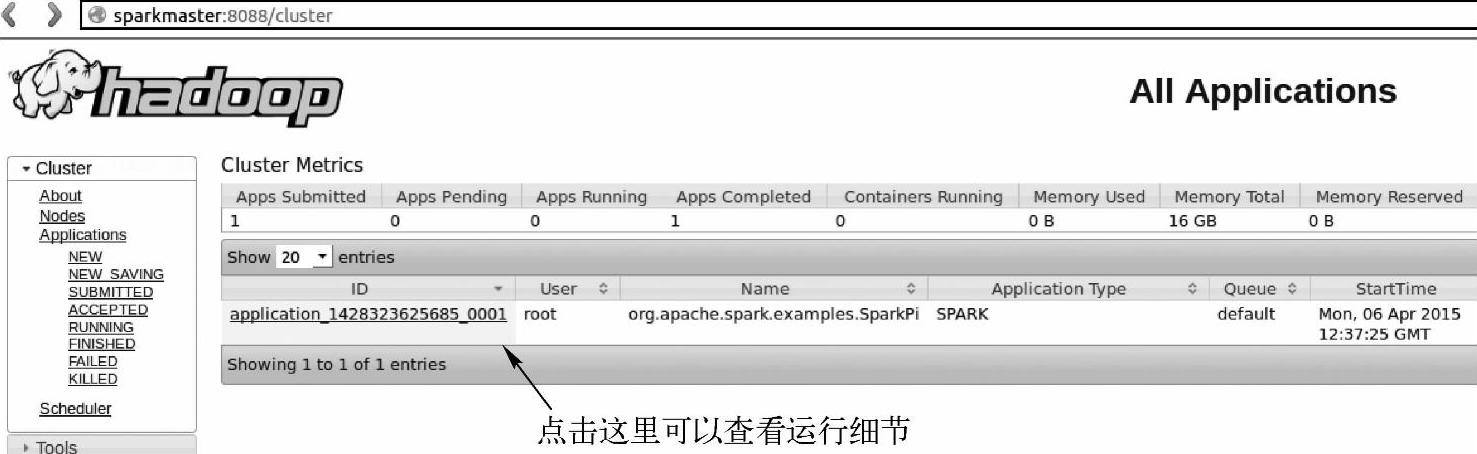
图4-8 Yarn模式下Application的运行情况
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。