



Spark需要运行在三台机器上,这里先安装Spark到SparkMaster这台机器上,另外两台的安装方法一样,也可以使用SSH的“scp”命令把SparkMaster机器上的安装好的Spark目录复制到另外两台机器相同的目录下。
(1)从Spark官网下载Spark安装包,笔者用的是spark-1.1.0。下载完后解压,并存放到自己指定的存储目录下:

(2)配置环境变量,打开“~/.bashrc”文件,添加“SPARK_HOME”,并把Spark的bin目录添加到PATH中:

保存并退出,并使用“source~/.bashrc”命令使配置文件的修改生效。
(3)配置Spark。需要配置spark-env.sh文件和slaves文件,首先需要在当前目录下复制spark-env.sh.template文件为spark-env.sh文件,如下所示:

用vim打开spark-env.sh文件,配置的内容如下:

保存并退出后,记得使配置信息生效。配置信息所表示的意义分别为:
1)JAVA_HOME指的是Java的安装目录;
2)SCALA_HOME指的是Scala的安装目录;
3)HADOOP_HOME指的是Hadoop的安装目录(或者说HDFS的部署路径,因为Spark需要和HDFS中的结点在一起工作);
4)HADOOP_CONF_DIR指的是Hadoop集群的配置文件的目录;
5)SPARK_MASTER_IP指的是Spark集群的Master结点的IP地址;
6)SPARK_WORKER_MEMORY指的是每个Worker结点能够最大分配给Exectors的内存大小;
7)SPARK_WORKER_CORES指的是每个Worker结点所占有的CPU核数目。
8)SPARK_WORKER_INSTANCE指的是每台机器上开启的Worker结点的数目。
接下来配置slaves文件,把Worker结点的主机名都添加进去,修改后的内容为:
 (https://www.xing528.com)
(https://www.xing528.com)
可以看到我们只设置了两台机器作为工作结点。
(4)SparkWorker1和SparkWorker2采用与SparkMaster结点相同的安装配置,可以使用SSH通信直接复制Spark的安装目录和“~/.bashrc”文件到另外两台机器相同的目录下,这里不再详解。
(5)启动并测试集群的状况。
1)当前我们只使用Hadoop的HDF文件系统,所以可以只启动Hadoop的HDFS文件系统。进入Hadoop的sbin目录下,然后在shell命令终端输入:./start-dfs.sh命令,可以看到SparkMaster启动了namenodes,SparkWorker1和SparkWorker2都启动了datanode,表示HDFS文件系统已经启动。

2)用Spark的sbin目录下的“start-all.sh”命令启动Spark集群,这里需要注意的是在命令终端必须写成“./start-all.sh”,因为在Hadoop的sbin目录下也有一个“start-all.sh”可执行文件。
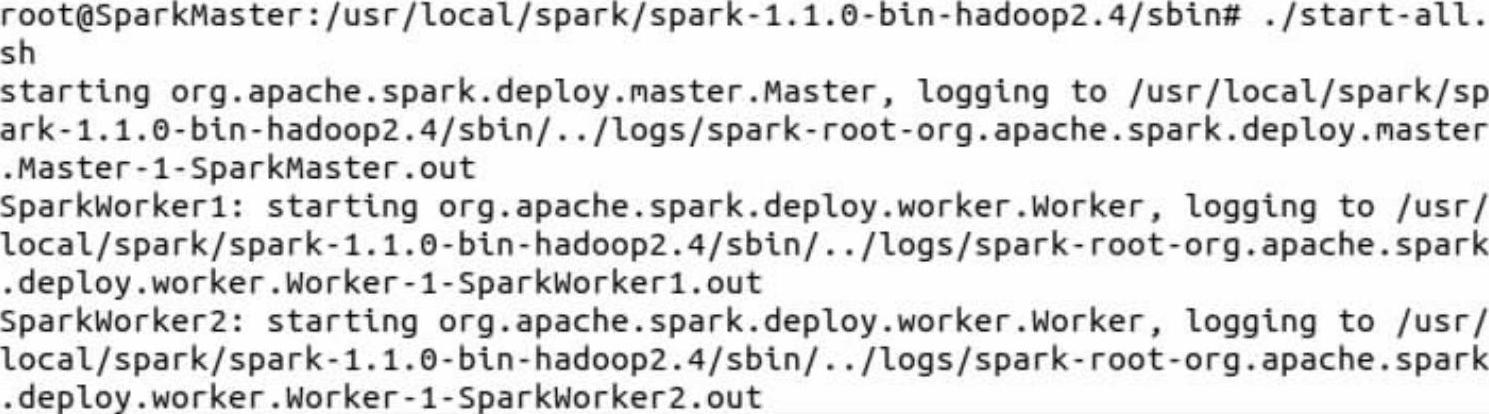
3)此时使用JPS在SparkMaster结点、SparkWorker1和SparkWorker2结点分别可以查看到新开启的Master和Worker进程。

4)可以进入Spark的WebUI页面,访问“SparkMaster:8080”,如图2-18所示(8080为Spark的WebUI监听端口,7077是Spark集群的Master的内部监听端口)。

图2-18 SparkMaster的WebUI
从图2-18可以看出有两个正在运行的Worker结点。
5)进入Spark的bin目录(当然因为我们已经把Spark的bin目录设置在~/.bashrc文件中,可以直接在其他目录下使用spark-shell命令),使用“spark-shell”命令可以进入spark-shell控制台:


我们也可以在WebUI页面输入“http://SparkMaster:4040”从Web的角度了解Spark-Shell(如图2-19所示)。
图2-19 Spark-Shell的WebUI页面
这时,Spark集群部署成功,下面进行集群的测试。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。