



Spark最初是由伯克利大学的AMPLab于2009年提交的一个项目,现在已经是Apache软件基金会旗下最活跃的开源项目之一。对于Spark,Apache Spark官方给出的定义:Spark是一个快速和通用的大数据处理引擎。可以通俗地将Spark理解为一个分布式的大数据处理框架,它基于RDD(弹性分布式数据集),立足于内存计算,在“One stack to rule them all”的思想引领下,打造了一个可以进行流式处理(Spark Streaming)、机器学习(MLlib)、即时查询(SparkSQL)、图计算(GraphX)等各种大数据处理、无缝连接的一栈式计算平台。由于Spark在性能和扩展性上有快速、易用、通用等特点,使它正在加速成为一体化、多元化的大数据通用计算平台和库。
Spark的一栈式解决方案有很多优势,具体如下。
(1)快速处理。图1-1展示了使用逻辑回归算法处理同样大小的数据,Hadoop使用的时间是110s,而Spark仅仅使用了0.9s,这里Spark的速度几乎是Hadoop的100倍。
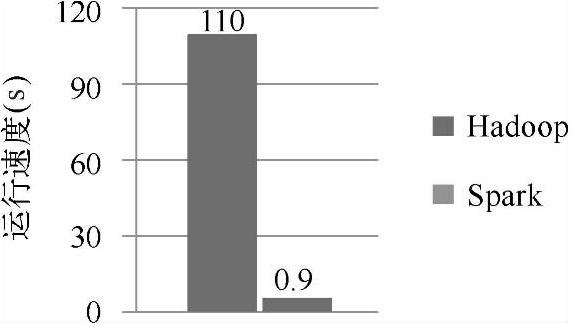
图1-1 逻辑回归算法在Hadoop和Spark上处理的性能比较
Spark之所以比Hadoop快的原因之一是Spark是基于内存进行计算的,而Hadoop是基于磁盘进行计算的。Hadoop每一次读取数据后的计算结果都会直接存储到磁盘上,然后再从磁盘读取上次计算的结果进行第二次计算,依此类推,这样就产生了非常大的I/O处理工作量,所以速度就慢下来了。而Spark把数据读取处理后的计算结果直接放入内存里面,然后再在内存中使用这个结果进行第二次计算,依此进行下去。所以在迭代计算上Spark明显比Hadoop占据优势。
Spark比Hadoop之所以快的另外一个原因是Hadoop的计算是按部就班一步一步进行的,而Spark的计算是具有预先筹划的,Spark把数据读取进来之后在使用这些数据计算之前会把整个运算过程绘制成一幅图,这个图叫作DAG图(有向无环图),然后计算的时候按图索骥,这样就有了方向性,进而有了优化的运算路径,减少大量的I/O读取操作。当然,Spark比Hadoop快的原因还有很多,例如容错机制和高效可靠的任务调度等。
(2)易于使用,支持多语言编程。Spark易用性的直接表现就是代码量少,例如计算同样的一个文件中有多少个单词时,Spark使用三行代码即可完成,如下所示。
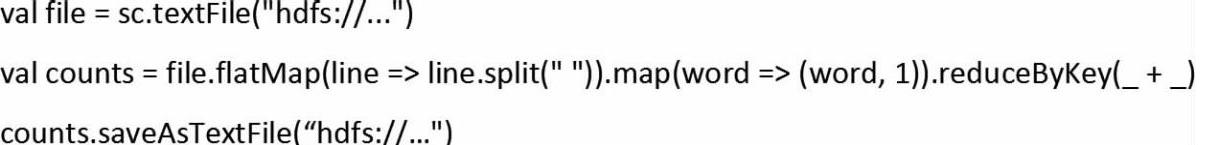
而完成同样的工作Hadoop却需要60多行代码(如下所示),两相对比,Spark可以让开发者节省大量的开发时间,并且维护起来也方便很多。
 (https://www.xing528.com)
(https://www.xing528.com)

同时,Spark本身是用Scala语言写的,但它也提供了多语言(包括Java、Scala、Py-thon)的API,能够快速实现应用。安装部署也无须复杂的配置,使用API可以轻松地构建分布式应用程序。
(3)通用性强。Spark提供了一个强大的技术堆栈,是一个可以进行流式处理、机器学习、即时查询、图处理等多种无缝大数据处理连接的计算平台,如图1-2所示。Spark之所以可以实现这些通用性是源于它的RDD(弹性分布式数据集),Spark提供了各种不同的RDD对不同的数据进行处理。而Hadoop的技术堆栈则相对独立也较为复杂,各个框架都是独立的系统,给集成带来了很大的复杂性和不确定性。

图1-2 Spark的技术堆栈
(4)可以与Hadoop和已存的Hadoop数据集成。Spark可以独立运行,除了可以运行在Mesos、Yarn等集群资源管理系统之外,它还可以读取已有的任何Hadoop数据,这是个非常大的优势,它可以运行在任何Hadoop数据源上,如Hive、HBase、HDFS等。同时如果你已经安装了第二代的Hadoop集群,即可以直接运行Spark。图1-3展示了一些可以与Spark集成的框架。

图1-3 Spark支持的技术框架
(5)活跃和迅速壮大的社区。Spark起源于2009年,至今已有超过50个机构、250个工程师贡献过代码。Spark的创始团队成立了Databricks公司,全力支持Spark的生态发展。同时Spark非常重视社区活动,组织也极为规范,定期或不定期地举行与Spark相关的会议。随着Spark的发展势头日趋迅猛,它已被广泛应用于Yahoo!、Twitter、阿里巴巴、百度、网易、英特尔、腾讯等各大公司的生产环境中。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。