



数字电路一般对工艺波动有更好的适应性。然而,有一些数字电路,包括自计时电路和匹配时延的电路,都对工艺波动极为敏感。自计时主要用于像缓存这样的嵌入式存储器中。在时钟频率较低时,其应用非常广泛。为了减小存储器的存取时间,自计时技术用于产生边沿,从而为读出放大器(Sense Amplifier,SA)提供(内部)时钟,这样在时钟周期的开始阶段,就可以准备好存储器数据,从而能够实现一个周期完成读取,包括对存储器数据的逻辑操作,进而实现更好的性能。随着(内部)时钟频率的升高,嵌入式SRAM的存取时间小于时钟周期,这样可以有大量的边沿用来对SA实现钟控。因此,在这种情况下,不需要强制自计时产生大量边沿。其他唯一需要自计时的情况是,通过地址改变之前不对SA提供时钟的方式节省功耗,而时钟设计也要求通过钟控门以减小时钟功耗。对SA进行钟控仍然比自计时更简单且更具鲁棒性。人们设计了许多的方案,可以在必须采用自计时的情况下,能够缓解波动对设计鲁棒性的影响。下面讨论一种用于SRAM的自计时方案。
自计时策略 传统的自计时存储器依赖于单个SRAM单元来驱动伪位线,然后转变为完全的CMOS电平及扇出以驱动SA的时钟线[28]。如图11-24所示,单个单元的自计时方法对工艺波动非常敏感,这些工艺波动引起单元驱动波动,导致更高的自计时时延波动。为了避免由于更高的自计时路径的时延波动引起的失效,就需要更大的裕量——这需要以性能为代价。
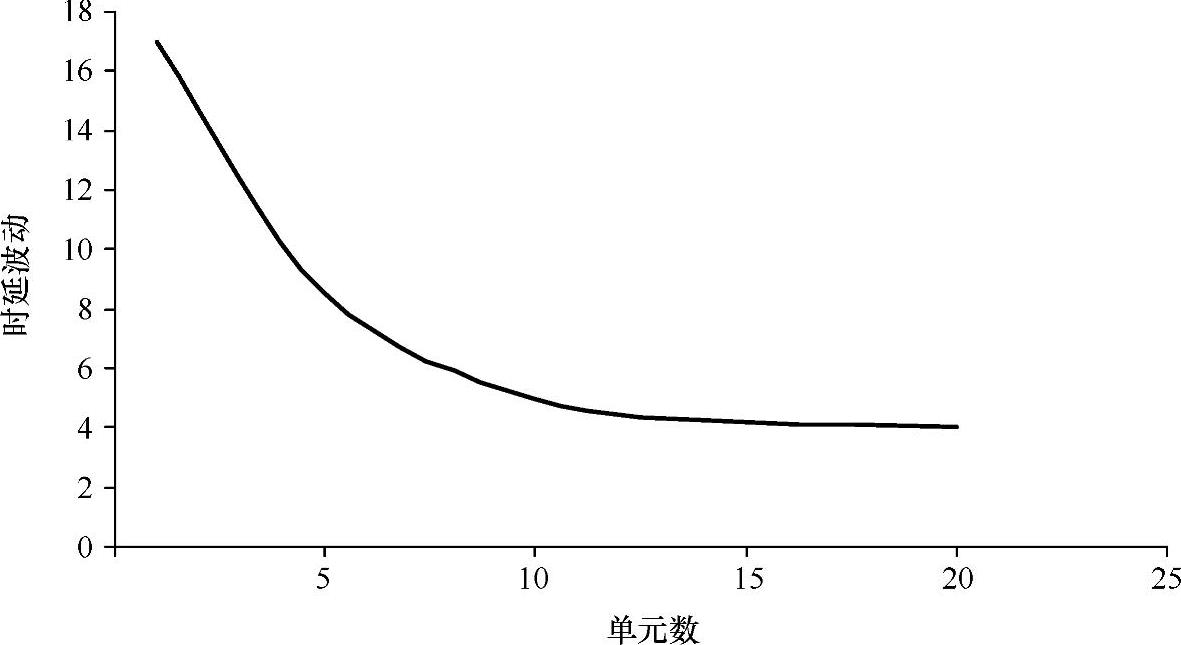
图11-24 单元数量对自计时时延波动的影响
如图11-24所示,如果使用不止一个单元,可以实现较低的自计时路径时延波动[13]。使用几个单元可以使单元电流波动得到平均。图11-25是一个多单元自计时方案。为了使单元驱动波动最小,在阵列的边界、伪自计时列旁用另一列填充单元作为伪自计时列是很重要的。在存储器列中,金属密度非常一致,使控制ILD波动变得容易。由于金属互连的规律性,由化学机械抛光(CMP)引起的电阻波动保持为最小,如在存储器阵列中看到的,制造商为了金属密度而优化CMP。大多数制造商都认识到必须减小存储器阵列电阻的波动,并且会优化存储器阵列的工艺。即使如此,仍然存在由于屏蔽层金属厚度和互连宽度波动而引起的电阻波动。
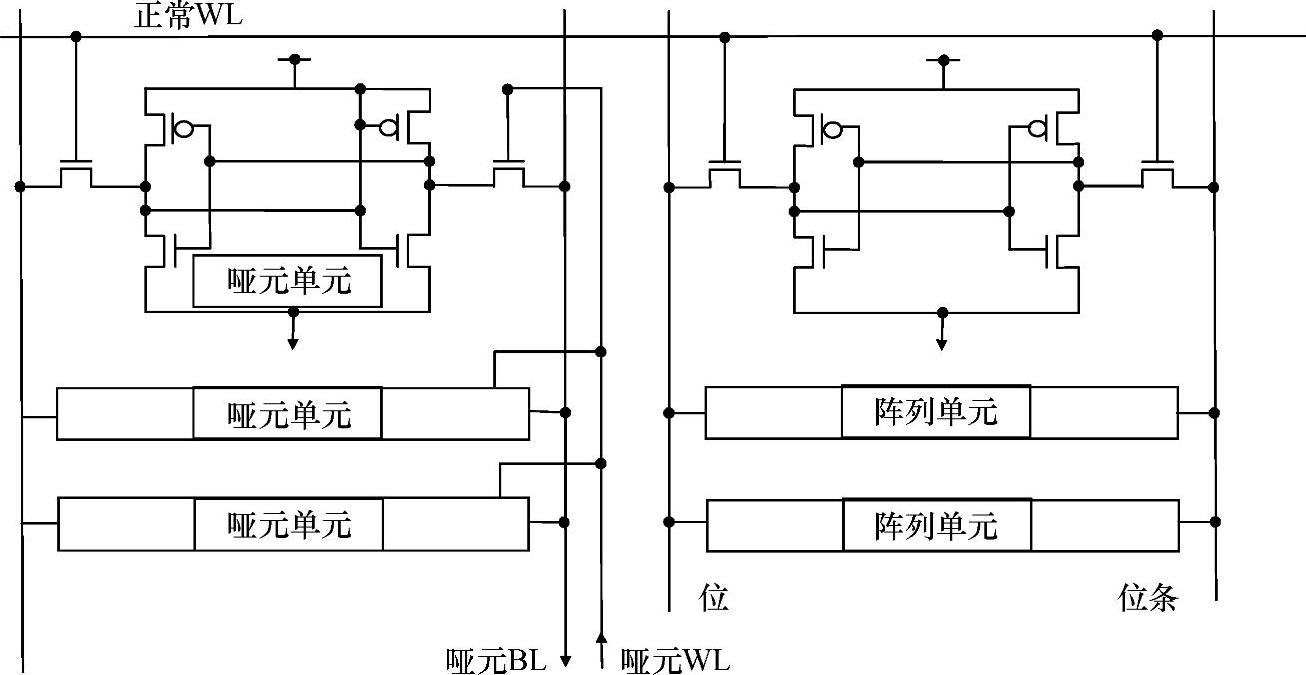
图11-25 多单元自计时方案
自计时裕量 图11-26所示为一个典型的自计时设计中的竞态条件。图中Out1上的时延必须小于Out2上的时延;否则,将会发生功能失效。由于工艺、电压和温度(PVT)的波动以及版图的差异,在实际生产出的电路中,由于一些局部效应在设计阶段并未被完全正确地建模或预见,可能会导致时延2小于时延1。当自计时设计中出现这种情况时,会导致在一些频率下不能工作,包括非常低的频率,这时会要求设计返工以恢复基本功能。这是非常严重的并且代价昂贵的设计缺陷。为了预防这种情况,我们增加了仿真模型的余量以覆盖一些未能预见的影响,以减小这种功能失效的概率。
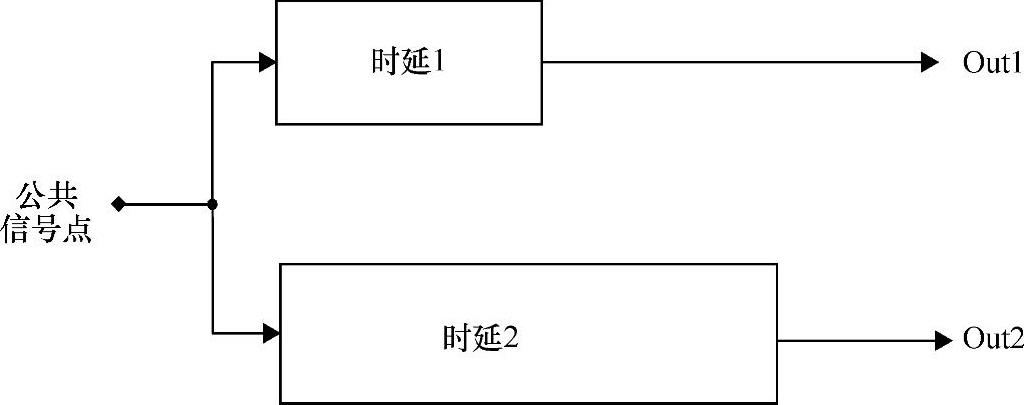
图11-26 设计自计时路径
如前面描述的,由于一些未知的影响或电路没有得到充分优化,时延2的速度可能与时延1不匹配。下面的分析将“余量”转化为那些能被用来验证自计时电路余量的具有物理意义的参数。图11-26所示的处于失效边缘的自计时电路可以表示为:时延2×(1-M)=时延1×(1+M)其中M是自计时裕量。将其简化,可以得到:
M×(时延1+时延2)=时延2-时延1
因此有:
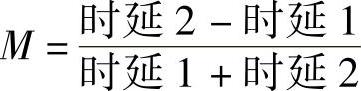
一般在所有实际工艺角下进行仿真时,将预布局布线时的M设定为0.25,而将版图后仿真时的M设定为0.15。对更实际工艺角覆盖,推荐使用统计模型。关于统计模型的详细介绍见11-3节。对于给定的自计时裕量,每个自计时路径必须采用金属编程选项,以保证在所有实际工艺角下使裕量至少再增加30%。如前面提到的,自计时竞态失效对芯片来说是灾难性的;金属编程选项的增加会导致快速的环锁定。金属选项必须被设计为可以影响一层并不超过两层中的裕量波动。这非常重要,因为掩膜的成本在不断增加,特别是对于纳米CMOS工艺节点。如果可能,在尽可能高的金属层中设计编程方式,可以在需要改变自计时裕量的情况下,加快产品的制造周转时间。
慢节点导致的时延波动 慢节点包括高扇出节点、不重复的长互连以及通过传输门和级联传输门的信号。正像不重复的长互连那样,传输门对信号来说相当于是一个大的电阻。如果一条信号路径上超过两个传输门(未采取缓存),就相当于是一个必须被处理的非常慢的节点。就像信号穿过级联传输门和不重复的长信号线的情况那样,慢节点也可以是驱动很弱的节点。被弱信号驱动的节点易受接收器所在的远端节点中的噪声耦合的影响。还有另一个障碍影响所有慢节点,包括高扇出节点。如图11-27所示,由于慢节点上输入信号的缓慢上升,接收机输入跳变点的波动被转换为较大的输入时延波动。由于工艺加工会引起P管N管之间的差异,进而会影响门输入阈值或跳变点,维持输入边缘的转换斜率则可以使设计能够更好地容忍P管与N管之间的差异。
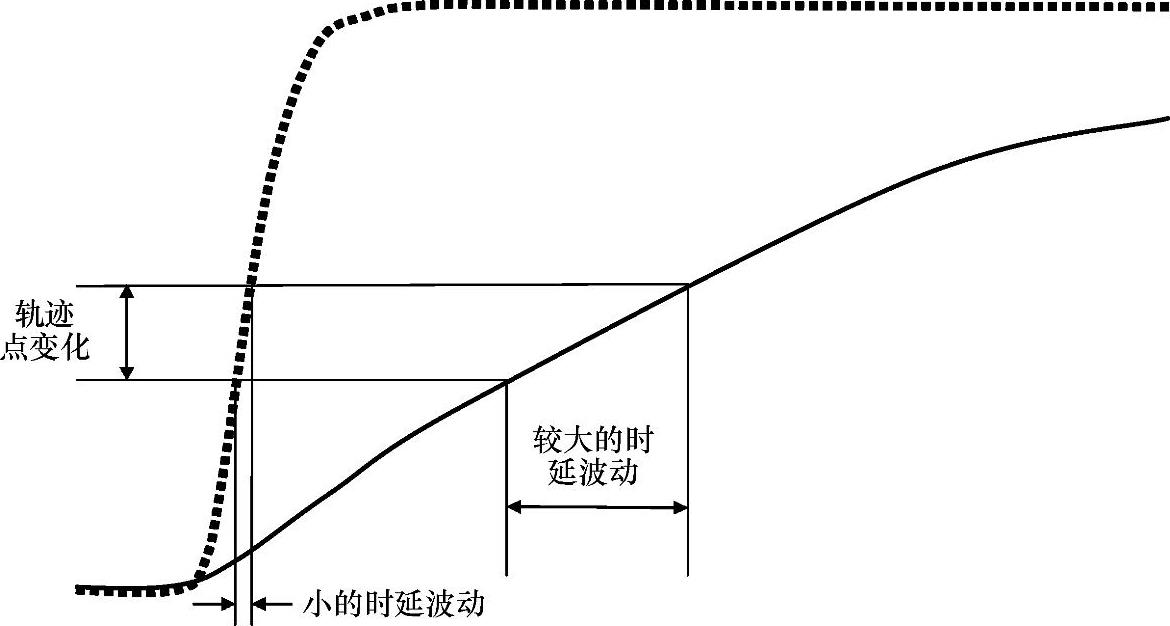
图11-27 跳变点变化与时延波动比对(https://www.xing528.com)
在一些电路中,例如算术模块,如果使用传输门加法器,在数据路径上就会有传输门。在某些情况下,数据路径上会有几个传输门串联,除非设计者在级联的全加器之间增加缓存器。这将增加了关键路径上的时延。通过改用差分级联电压开关(DCVS)逻辑可以缓解这个问题[31,32]。
脉冲寄存器时钟发生器设计策略
跳变点匹配:脉冲寄存器工作过程和设计不是本书要介绍的内容;对其详细的讨论请参看其他电路设计文章。但是,想要能够理解下面关于工艺波动对脉冲发生器和脉寄存器工作过程的影响的讨论,则需要对脉冲寄存器工作过程有全面理解。图11-28中是一个用于脉冲寄存器的脉冲发生器典型电路。Inv1到Inv3形成了一个确定脉冲发生器脉宽的时延链。脉冲发生器的脉宽波动对脉冲寄存器的保持时间有严重的影响。Nand1和Inv1的输入跳变点必须匹配;否则,脉冲宽度会随着全局时钟边缘斜率的波动而改变。更长的脉冲输出宽度将会要求更长的保持时间,同时导致更长的透明时间。如果输入到脉冲寄存器中的短脉冲没有及时得到适当的平衡,即使对这个短脉冲存在最大时间路径,由于更宽的脉冲宽度引起的更长透明期也会引起保持时间的问题。
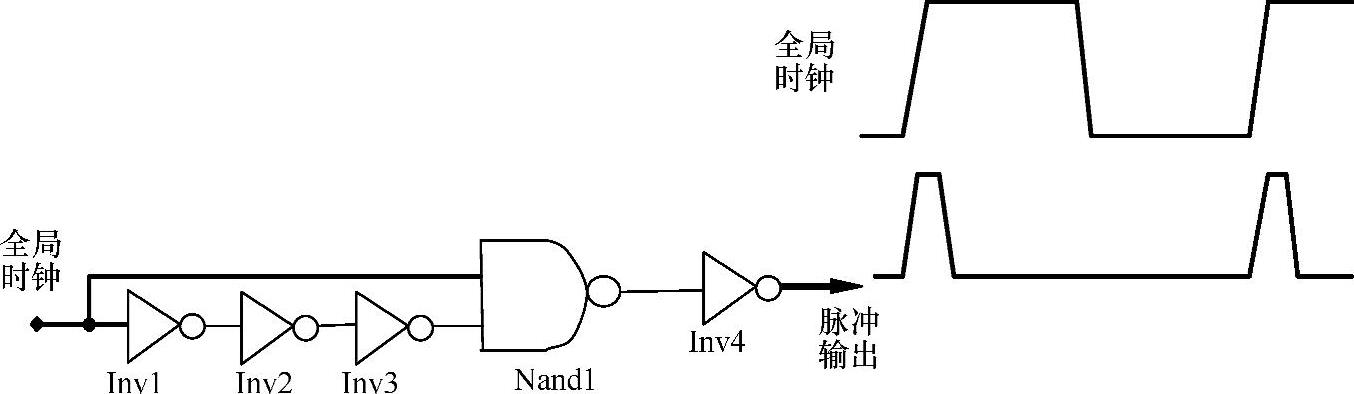
图11-28 典型的脉冲寄存时钟发生器
我们从图11-28所示的Inv1开始,考虑Nand1的跳变点比反相器链更高的情况。当全局时钟上升时,Inv1首先动作并启动时延链,而Nand1尚未对全局时钟输入做出反应。这将实际上缩短了脉冲发生器输出脉冲的宽度,因为反相器时延链跳变更早地触发了脉冲发生器输出的上升沿。从Inv1开始动作到Nand1触发之间的时延等于脉冲发生器输出脉冲宽度减小的量。如图11-27所示,时钟上升时间波动会改变这个时延,从而改变脉冲宽度。有多种原因会导致时钟上升时间的变化,而该变化会影响芯片的保持时间并引起灾难性的失效。Nand1跳变点低于Inv1的触发条件会增加脉冲宽度和脉冲寄存器要求的保持时间。在基于单元的设计中,脉冲寄存器表征条件是假定Inv1和Nand1的跳变点完全匹配。如果Inv1和Nand1的跳变点不匹配,将引起脉冲寄存器实际要求的保持时间改变,从而可能产生保持时间失效。
设定输入跳变点稍稍低于Vdd/2(低于中点的1/3),但不要太低;否则,会受到地电位反弹影响。这是因为在时钟上升沿的较低位置,边缘误差较低。由于脉冲发生器仅参考时钟上升沿,因此这一技术可以确保实现更精确的时钟参考和更低的时钟边沿时延。
脉冲发生器输出波形峰值:脉冲宽度必须足够宽,以确保在各种的实际情况下,对所有负载条件,脉冲都能到达Vdd。这保证了脉冲宽度是确定的。如果在所有的负载条件下脉冲宽度都能够到达Vdd,脉冲将总是在相同的PVT条件下从相同的电压释放电荷,因此脉冲宽度将是确定的。这就消除了脉冲宽度的波动(不包括PVT条件引起的波动)。使时钟脉冲达到Vdd的其他原因是确保总是在寄存器的时钟输入端有相同驱动电平,从而避免由于门驱动的波动导致的建立时间和保持时间的波动。
脉冲发生器时延与数据路径时延密切相关:为了保持低功耗,由Inv1和Inv2形成的时延链必须采用最小尺寸晶体管构成。这里我们不得不以功耗为代价来减缓工艺对数据时延的影响。所选器件必须足够大,从而使得时延不会主要取决于寄生参数。就像以提高速度为目标而优化的数据路径上那样,沿着时延链的寄生必须被最小化。在各种实际可能发生的极端情况下,时延链提速的速率必须与数据路径的相匹配,避免出现保持时间冲突。如果数据路径提速快于时延链,特别是对动态脉冲寄存器,就能够避免动态寄存器的输入数据在脉冲复位前发生变化。
时延链上的最后一个单元(Inv3)必须与脉冲发生器驱动的逻辑寄存器有相同的堆栈高度。脉冲发生器产生时钟脉冲,如果接收时钟脉冲的寄存器不是简单的寄存器而是动态逻辑寄存器,时延链上的Inv3必须与寄存器前面的动态逻辑有同样的堆栈高度(参见图11-29)。这使得时延链可以在各个工艺角上都能够满足逻辑时延。图11-30与图11-31是两个实例,说明需要放宽间距规则以及多晶端头覆盖,以减小由于光刻引起的多边形图形失真导致的器件波动。
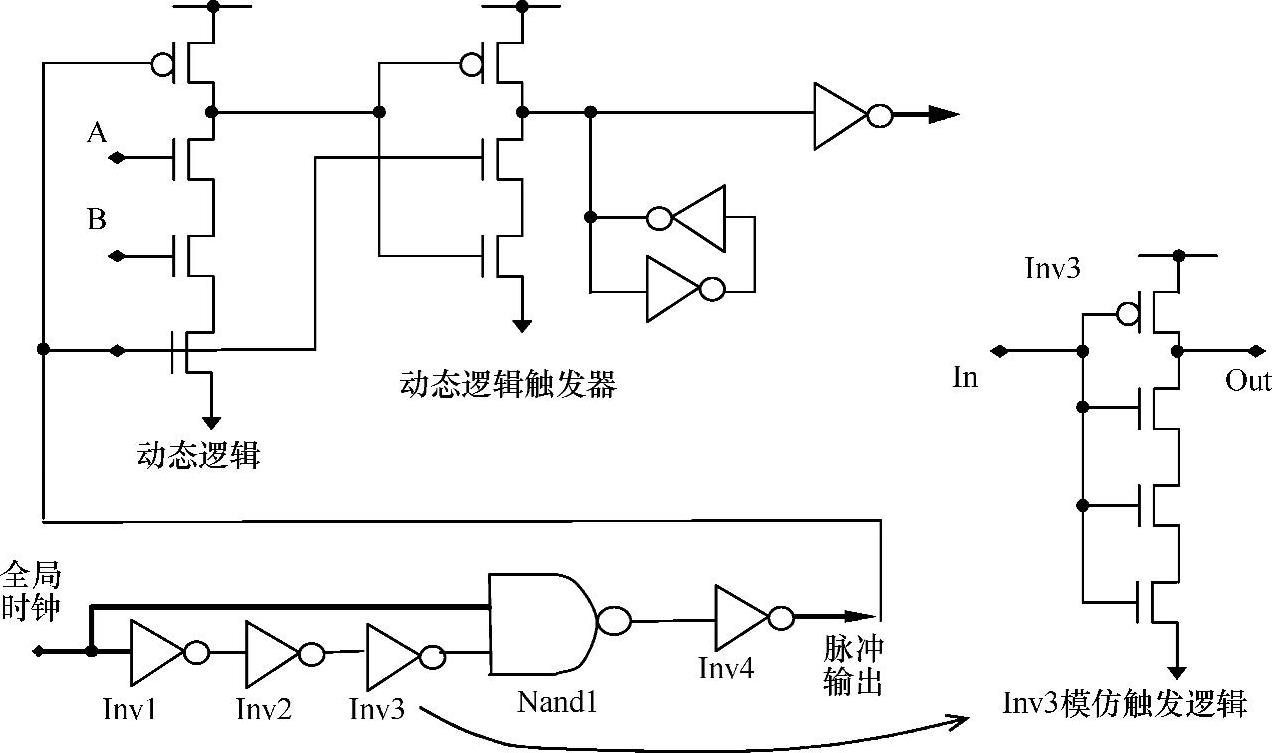
图11-29 脉冲发生器的时延追踪技术
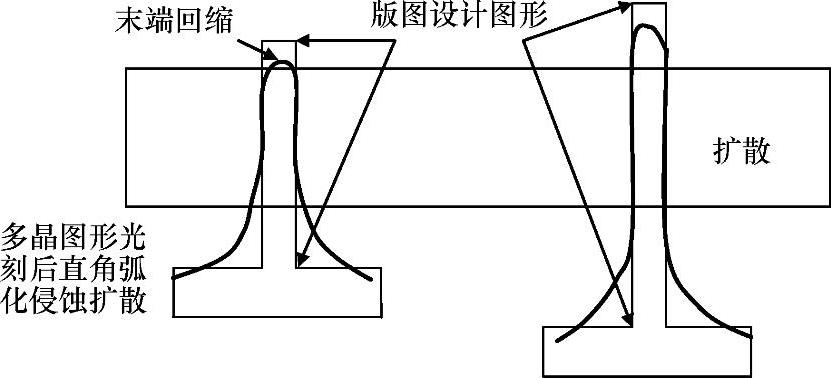
图11-30 光刻引起的多晶图形直角弧化
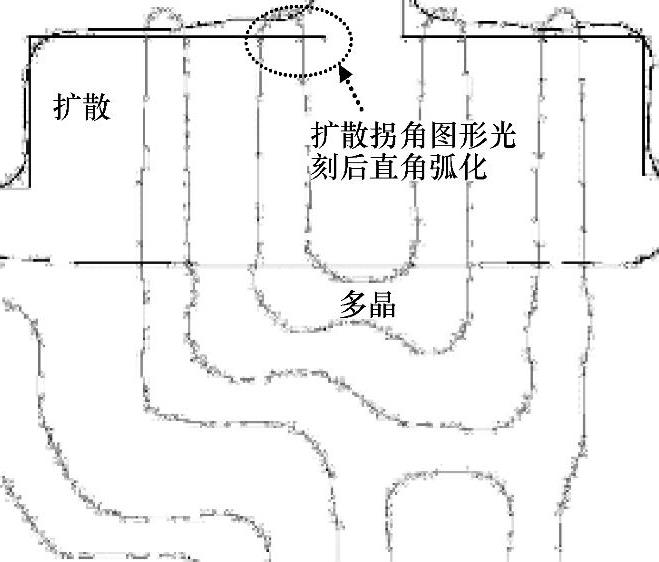
图11-31 扩散图形拐角处的多晶端头覆盖不良
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。