



在电路级,有许多技术可以被用来建立功耗优化的电路。
1.在设计阶段使用层叠效应
如果将两个关态晶体管层叠,由于栅—源、体偏置和漏源电压同时得到减小,使亚阈泄漏电流比单个关态晶体管的小得多。这种层叠效应已经被广泛地应用到各种泄漏减小技术中。这些方法中,大部分使用复杂的低泄漏输入向量、栅调整[45]和插入串联晶体管[44]将待机电路转换为层叠结构等方法,实现运行阶段的待机控制。详细内容将在9.3.2节介绍。在设计阶段,基于强制层叠技术[27],将一个非层叠器件变成两个器件的层叠而不影响输入负载(见图9-2)。采用这种方法,以一定的延迟增加为代价使层叠驱使逻辑门的泄漏减小了9倍,其效果与双Vth技术相似,但不会像采用第二种Vth那样增加工艺复杂性。可以在非关键路径应用层叠驱使技术,能够同时减小待机泄漏和有源状态下的泄漏,而会对采用正常门设计的关键路径的速度产生影响。同样的工作结果表明,这种用于减小泄漏的层叠技术将会随着工艺技术的进步和器件尺寸的减小而得到改善,使得在未来的技术发展中采用层叠效应的泄漏控制技术更加有效[27]
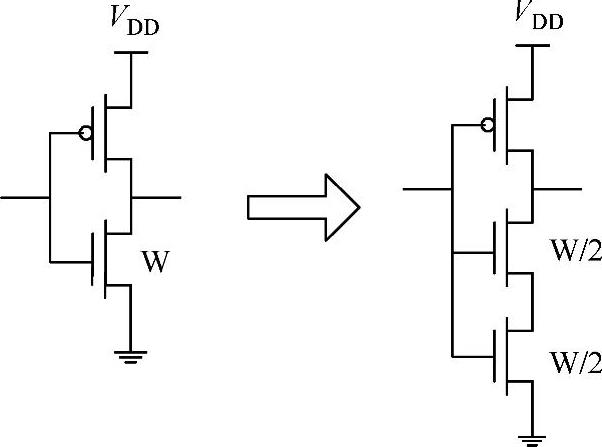
图9-2 采用层叠技术的双层叠NMOS(来源于参考文献[27])
2.输入序列重排
输入序列重排是可以优化电路延迟和容性功耗的门级技术。合适的输入序列重排使内部节点的开关活动最小并减小了有源功耗。人们基于电路结构、内部节点电容、(逻辑1)信号概率和翻转概率的解析模型,提出了不同的算法,实现优化的输入序列[47-49],总结了输入序列重排的一般规则。这些规则中最得到普遍认同的一点是将转换(开关)率最高的信号放置到最靠近输出端点的地方[48,50],这样可以使电源轨的连接活动最小,同时导致性能的优化。这一领域的另一项研究进一步考虑了扇入、扇出门和序列重排门总功耗的优化[51]。所有这些输入序列重排算法可以使平均功耗减小3.6%~12%。与其他低功耗技术相比,输入序列重排技术节省的功耗有限;然而,它不要求额外的器件和结构调整,因此可以很容易与其他低功耗技术一起使用。这一特点加速了它的应用。
3.优化确定晶体管尺寸
在设计时为了得到期望的功耗、时延和面积之间的折衷,晶体管尺寸的确定是一个重点。使用TILOS[38]和EinsTuner[39]等优化工具,可以广泛地实现尺寸优化。对于给定的时延约束,采用这些工具可以得到使电路总功耗最小化的近似解。作为尺寸优化的第一个综合器,TILOS在多项式设计优化中[38]采用的是一个简单的RC时延模型,可以处理多达25万个晶体管的电路。在各种高性能芯片设计中使用TILOS可以减小40%~50%的功耗[7]。十几年后,IBM研究开发了EinsTuner工具,对于与沟道相连的元器件进行精确的仿真,改善了TILOS中的时延模型,并且实现了基于梯度的非线性优化。其结果是EinsTuner以更高的精度实现了更好的解决,但是其付出的代价是降低了处理大规模集成电路的能力(对于由2796个晶体管构成的加法器电路,包含了超过5600个变量和超过5600个约束条件,计算过程则花费了三天时间)[39]。另外,通过考虑短路功耗[40]和上升/下降时间延迟单元[41]等,许多其他工作也使尺寸优化得到进一步改善。
4.应用多电源和多阈值电压
电源VDD和阈值电压Vth是使有源功耗、泄漏功耗和电路性能之间平衡得到优化的关键因素。在运行阶段,可以动态改变VDD和Vth,以提高不同负载点的系统功率效率,详细内容在9.3.1节介绍。在设计阶段则需要做大量的工作以解决高速低功耗设计中的VDD和Vth优化问题。目前已推导得到考虑短沟道效应和Vth变化的解析形式方程[58]。以VDD、Vth和尺寸作为变量进行的灵敏度平衡分析结果表明,在延迟增大20%的代价下,可获得40%~70%的功耗节省[9]。另一方面,由于一个电路的全局性能一般只受到几条关键路径的制约,而整个电路的路径时延分布范围很广,这也促使了多VDD和多Vth的使用[54]。如图9-3a所示,双Vth技术可以用低Vth器件来对关键路径加速而在非关键路径采用高Vth来抑制泄漏。图9-3b显示了双Vth优化对路径延迟分布的影响,其目的是实现路径延迟之间的平衡并加速关键路径。该技术已在电路中得到广泛应用[55,56],通过在路径平衡中结合多VDD和晶体管尺寸缩放设计技术,可以使优化空间得到进一步扩展。通过这种优化技术的研究,目前已提出了几种算法,可以在非关键路径上选择能够采用高Vth值而不影响系统整体性能的晶体管(可以通过将一条非关键路径转换为关键路径保证系统整体性能)[57]。另一项工作结果表明,对于有效的设计,VDD、Vth和尺寸的确定无需超过三个离散值[8]。
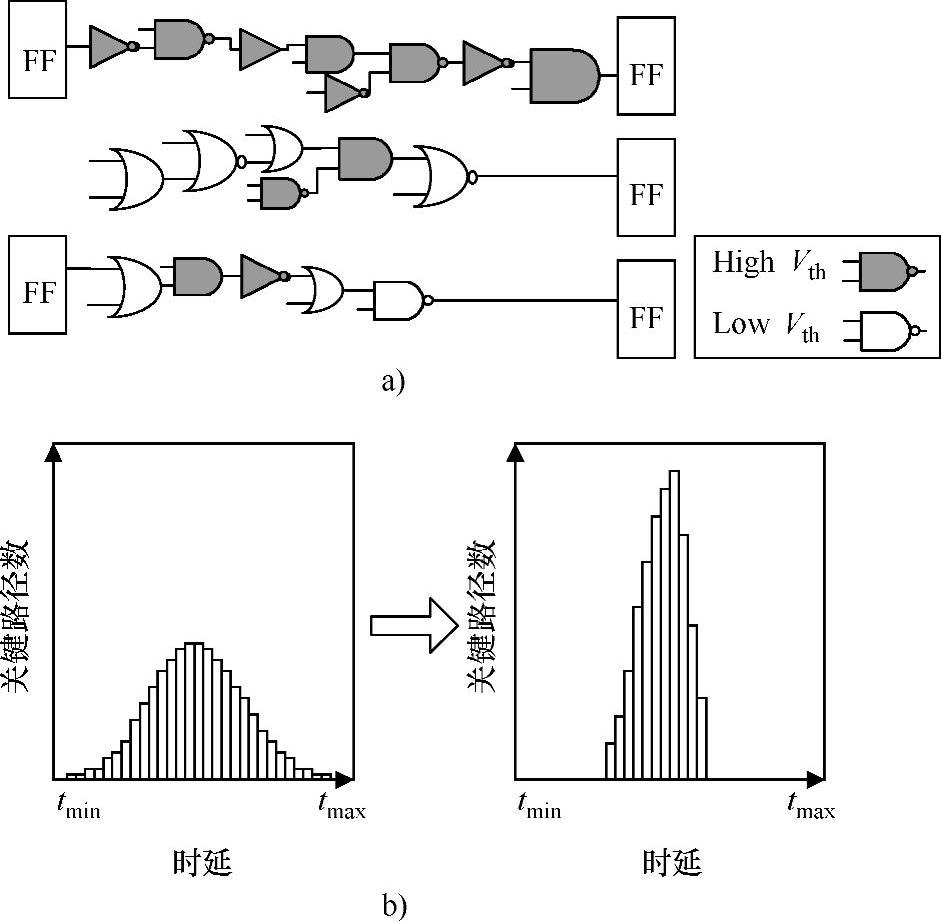
图9-3 采用双Vth技术的高速低泄漏设计(https://www.xing528.com)
a)关键路径上的晶体管应用低Vth值 b)双Vth优化前后的路径延迟分布

图9-4 归一化Ids泄漏与沟道长度的关系
5.器件沟道长度采用非最小值
设计中通常都采用工艺允许的最小沟道长度。到130nm技术节点,这一直是传统的设计惯例,但是现在由于泄漏电流的显著增加,设计者不得不将器件分成最小的和非最小的沟道长度以减小泄漏电流。沟道长度的增加对设计电路的总待机电流有很大的影响,特别是如果它被广泛地应用到大量的器件中时。图9-4所示为100nm工艺中源—漏泄漏电流与沟道长度的关系。所有的泄漏电流值均参照沟道长度为15μm的器件进行了归一化处理。将沟道长度从100nm增大到150nm,可以实现约60%的泄漏减小。与双Vth情况相似,可以在非关键速度路径上使用非最小化沟道长度以平衡系统延迟分布。采用非最小化沟道长度的另一个优点是可以减小工艺波动对这些路径的影响,因为在更长沟道器件中,沟道长度波动的相对值减小了。另外,使用多阈值器件方法将因为要包括附加的掩膜和更多的工艺步骤而增大工艺费用,而器件沟道长度采用非最小值的设计方法可以提供成本更低的方案。
6.低功耗标准单元库和定制库产生
采用由功耗最小的元件形成的标准单元库极大地方便了低功耗系统的实现。低功耗标准单元库中的单元采用能量高效的逻辑类型和定制尺寸形成,并针对不同的规范要求,提供有适用于不同阈值电压的版本。结果表明,与采用通用标准单元库得到的设计相比,使用适当策略,由逻辑综合器基于低功耗库产生的设计具有更好的性能,并使功耗得到改善[10]。采用定制库的方式[52]则可以进一步克服定制低功耗标准单元库尺寸固定的问题,给设计提供了更大的灵活性。基于按需求产生的ASIC设计方法如图9-5所示。其中根据性能评估的结果产生一个经修正的单元库,并将其用到基于单元的设计工具中。该设计流程的特点是在版图设计后再进一步确定晶体管尺寸,即基于从初始版图中提取的信息来缩小单元尺寸,从而优化单元库。采用这种方法,可以消除采用通常固定库设计中存在的面积和功耗冗余问题,形成一个完全优化的物理设计。据报道,采用定制库的方法,可以使电路功耗的减小最大可达77%,平均为65%,并且不会增加时延[53]。

图9-5 使用定制库的ASIC设计方法(来源于参考文献[52])
7.减小互连功耗
互连,包括片上互连和封装引线,已成为功耗的主要来源。随着金属互连层数的增加互连尺寸的缩小,目前设计中金属互连电容已占据芯片总电容的70%[2]。另外,由于动态功耗为(C·V2dd×频率),因此芯片工作频率的快速增加进一步恶化了互连系统中的动态功耗。注意,互连感抗在电压翻转时并没有直接消耗功率。基于互连功能划分的下述三种互连是决定功耗的主要因素:片上信号线、I/O系统的互连和时钟分布网络。为了减小他们的功耗,业已从技术和设计两方面提出了许多创新技术。减小互连功耗的一种普遍方法是采用低电压摆幅。这个技术被广泛应用到I/O系统中,如低压差分信号(Low-Voltage DifferentialSignaling,LVDS)。LVDS不仅节省功耗而且提高了I/O信号传输速度。然而,随着纳米时代信号耦合噪声的急剧增加,信号完整性考虑和设计开销制约了这一方法在片上信号发送和时钟网络中的应用。业已表明,对全局信号互连,通过改变总线位置或者对翻转方式进行编码,将使最坏情况下的耦合电容被最小化,因此采用总线改变和编码技术可以减小耦合电容上的功耗。另一种考虑功耗影响的互连设计方法是引入非正交的全局层,减小总的信号互连长度。例如,在X结构中[97],可以采用45°的版图。这种情况下,可以节省约20%的总互连长度,进而可以减小相同比例的互连功耗[97]。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。